
大小端及網路位元組序
原文地址:https://blog.csdn.net/z_ryan/article/details/79134980
什麼是大端模式、小端模式
“大端”和”小端”表示多位元組值的哪一端儲存在該值的起始地址處;小端儲存在起始地址處,即是小端位元組序;大端儲存在起始地址處,即是大端位元組序;具體的說:
①大端位元組序(Big Endian):最高有效位存於最低記憶體地址處,最低有效位存於最高記憶體處;
②小端位元組序(Little Endian):最高有效位存於最高記憶體地址,最低有效位存於最低記憶體處。
如下圖:當以不同的儲存方式,儲存資料為0x12345678時:
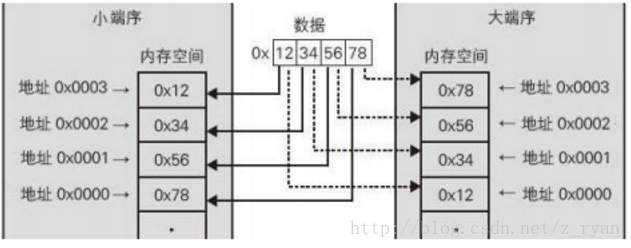
判斷位元組序
可以通過下面的小程式測試自己的機器是大端位元組序還是小端位元組序
#include <stdio.h>
union
{
char ch;
int i;
}un;
int main(void)
{
un.i = 0x12345678;
if(un.ch == 0x12)
{
printf("big endian\n");
}
else
{
printf("small endain\n");
}
return 0;
在測試程式中,使用聯合體的原因是:union型資料所佔的空間等於其最大的成員所佔的空間。對union型成員的存取都是相對於該聯合體基地址的偏移量為0處開始,也就是聯合體的訪問不論對哪個變數的存取都是從union的首地址開始的。通過檢測第一個位元組存放的資料即可得出結果。
網路位元組序
網路上傳輸的資料都是位元組流,對於一個多位元組數值,在進行網路傳輸的時候,先傳遞哪個位元組?也就是說,當接收端收到第一個位元組的時候,它將這個位元組作為高位位元組還是低位位元組處理,是一個比較有意義的問題;
UDP/TCP/IP協議規定:把接收到的第一個位元組當作高位位元組看待,這就要求傳送端傳送的第一個位元組是高位位元組;而在傳送端傳送資料時,傳送的第一個位元組是該數值在記憶體中的起始地址處對應的那個位元組,也就是說,該數值在記憶體中的起始地址處對應的那個位元組就是要傳送的第一個高位位元組(即:高位位元組存放在低地址處);由此可見,多位元組數值在傳送之前,在記憶體中因該是以大端法存放的;
所以說,網路位元組序是大端位元組序;
在實際中,當在兩個儲存方式不同的主機上傳輸時,需要藉助位元組序轉換函式。
位元組序轉換函式
#include <arpa/inet.h>
//將主機位元組序轉換為網路位元組序
unit32_t htonl (unit32_t hostlong);
unit16_t htons (unit16_t hostshort);
//將網路位元組序轉換為主機位元組序
unit32_t ntohl (unit32_t netlong);
unit16_t ntohs (unit16_t netshort);
說明:h -----host;n----network ;s------short;l----long。
例如:
#include <stdio.h>
#include <arpa/inet.h>
int main()
{
unsigned int x = 0x12345678;
unsigned char *p = (unsigned char *)&x;
printf("%0x_%0x_%0x_%0x\n",p[0],p[1],p[2],p[3]);
unsigned int y = htonl(x);
p = (unsigned char*)&y;
printf("%0x_%0x_%0x_%0x\n",p[0],p[1],p[2],p[3]);
return 0;
}
執行結果:
