2017CVPR、ICCV和NIPS在Person Reidentification方向的相關工作小結
轉載自: https://blog.csdn.net/qq2414205893/article/details/78901517
論文閱讀小結(以下內容為論文閱讀筆記及總結)
NIPS2017
-
6608-deep-subspace-clustering-networks
這篇文章的創新點在於,提出了一個自表達層,來對特徵進行具有自表達能力的子空間學習。其目標函式為:
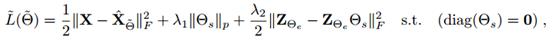
該函數借鑑了,周志華多源資料聚類傳統方法的目標函式,幾乎沒有變化。其主要演算法流程為將資料輸入xi經過神經網路編碼為zi,然後在通過反捲積將zi解碼為輸出表達`Xi`,最後使用傳統譜聚類演算法根據學習到的鄰接矩陣θs對資料進行聚類。其網路構架如下:

其中本文的一個可以借鑑點是將傳統方法中涉及矩陣學習的迭代優化演算法,改為使用神經網路做端到端的梯度下降優化,其具體實現模組如圖所示:
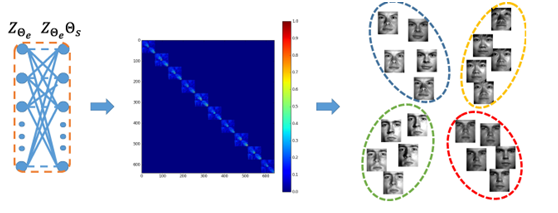
整個過程是非監督地聚類。本文侷限在於,有多少個樣本,為了學習對應的鄰接矩陣,需要使用對應個數的全連神經網路,不能做到自適應聚類樣本個數,可以看做是特徵的refine。
-
6644-pose-guided-person-image-generation
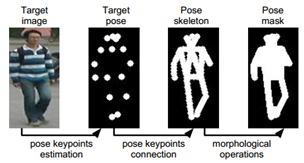
本文采用了對抗生成式網路,通過在一個具有同一個不同姿勢的資料庫上訓練,使網路學習到不同姿勢對應的畫素漂移對映,然後只需要給出目標pose,即使用21*2的矩陣表示人體關節的21個關鍵點位置,就能夠生成一張同一個人的目標姿勢照片。效果圖如下:

其中本文所用的關節點檢測模型為Realtime multi-person 2d pose estimation using part affinity fields是目前最先進的姿勢估計網路之一。其主要過程如下圖所示:

然後通過兩個階段的對抗生成網路:
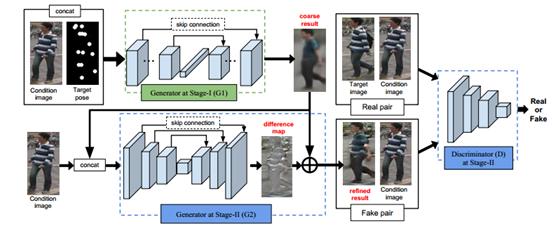
第一階段使用原圖和pose關鍵點mask級聯作為輸入,得到粗糙生成圖片,然後第二階段再由粗糙圖片和同一個人的候選圖片進行提煉refine,然後再把圖片輸入判別模型,採用極大化極小策略對目標函式優化:

最後他的貢獻用於擴充行人重識別資料庫,使得網路在學習時就能捕捉到各種同一個人的姿勢變化,從而達到提取出姿勢不變的特徵。
-
6609-Attentional Pooling for Action Recognition
隨著注意力機制在NLP和CV任務中的廣泛運用,越來越多的學者對注意力機制的具體模組做出了建設性的探索,本篇文章是NIPS的oral文章,它提出了二階注意力模組,同時用大量的實驗探索了,注意力模組應該加入在深度網路的什麼位置,不同的基本網路與注意力模組的相互影響等等。
本文的演算法印證主要是在人體行為識別資料庫UCF101等上進行,其效果如下:

右側為注意力模組學習到的注意力關注區域。
傳統一階注意力網路大多為學習一個locations*1的mask向量,向量的值代表了對應位置上的權重,但是它沒有挖掘到,location之間的關係或者說是相互作用的權重。所以產生了二階注意力機制。
二階注意力流程圖如下:
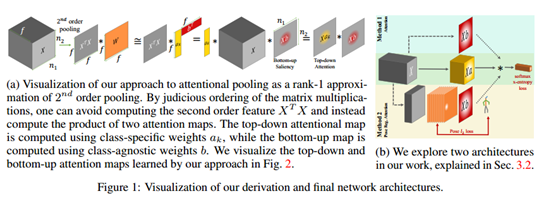
通過所提Attention pooling層可以學到一個二階attention矩陣,而不僅僅只是一個mask向量,然後再conbine二階和一階的mask,就能得到更加精確的注意力關注區域。
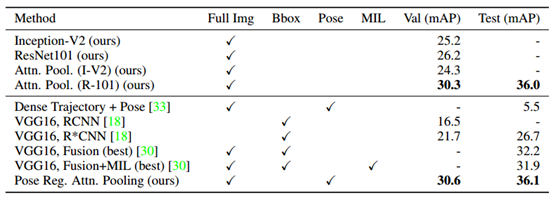
從結果中可以看到,使用了attention pooling接近從baseline提升了9個百分點。
CVPR2017
-
【CVPR2017】Beyond triplet loss: a deep quadruplet network for person re-identification
本文提出了四重損失函式:
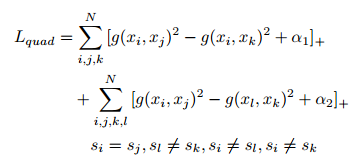
其中i為anchor,j為positive,k為negative1,l為negative2,目標函式物理意義在於使用另個不同的negative進一步增大類間距離,但是如果相對於使用足夠多的triplet組進行訓練時,理論上應該能夠達到相同效果。本文trick在於:
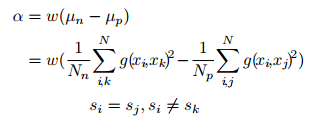
其中的a是loss函式中的margin,其物理意義在於針對每一個batch的資料所組成的an和ap對之間距離的間隔,應該是動態變化的,所以這篇文章將margin動態地設定為所有an對距離的均值和所有ap對之間距離的均值的差值,這樣能夠使網路學習時每一個batch都能起到拉開類間距離和縮小類內距離的作用,如果margin 固定,當margin過小時,針對一個batch中類間距離很大的情況,這一次的學習就會沒有意義,應為不管怎樣類間距離都會遠大於類內距離,所以類內距離沒有被壓縮。並且作者還用w來平衡三元組和四元組的影響,三元組為1,四元組為0.5.
本文沒有做Market資料集上的實驗。
-
【CVPR2017】Consistent-Aware Deep Learning for Person Re-Identification in a Camera Network
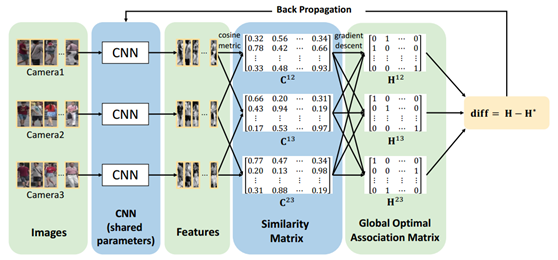
本文提出了和普通行人重識別不一樣的任務目標以及評價標準,其主要思想在於設計一個網路使得通過這個網路提取出的影象特徵能夠在同一個攝像頭中儘可能地匹配準確,例如通常我們評估行人重識別精度在具有很多個攝像頭,或者攝像頭資訊不完全等資料庫時,採用多射策略——即只要匹配到同一個的圖就算匹配上,無論這兩張圖是否來自同一個攝像頭。而本文則是隻有同一個人的不同攝像頭之間的照片匹配正確了才算是成功的行人重識別,並且希望儘可能多的讓每個不同攝像頭之間的照片匹配得上的多,就是一號攝像頭匹配二號和三號的數量和二號匹配三號的數量都要儘可能多。本文並不是一個端到端的過程,但是其自定義的feedback求導過程值得研究。
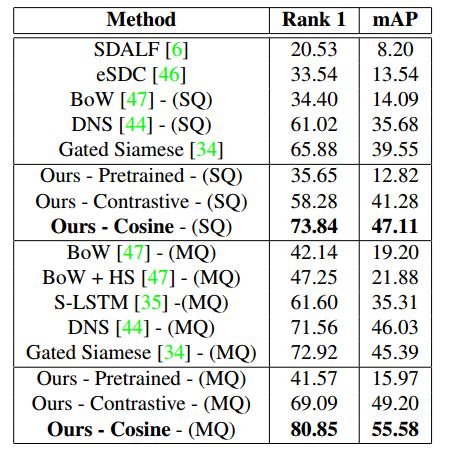
其在Market資料集上的精度如下:
-
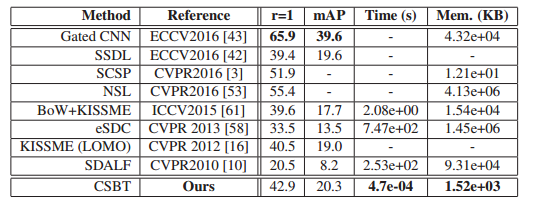
【CVPR2017】Fast Person Re-Identification via Cross-Camera Semantic Binary Transformation
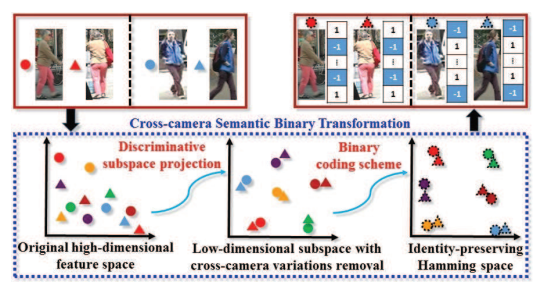
本文思想和我本身的Cross-domain latent space projection for reid工作十分相似,其代價函式也是學習一個投影向量,將分影象部分的高維特徵向量投影到低維子空間中並且保持類內距離變小,類間距離拉大,然後把分部分的向量二值化,通過逐部分的比較,然後綜合來考慮這兩張圖片是否匹配正確。
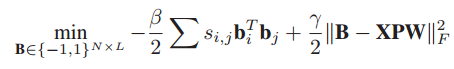
該方法是將最終的雜湊函式也加入到類內類間的代價函式中,一次性優化而成,主要屬於雜湊演算法和子空間學習的聯合應用。
Market資料庫精度,主要是速度大幅提升:
-
【CVPR2017】Joint Detection and Identification Feature Learning for Person Search
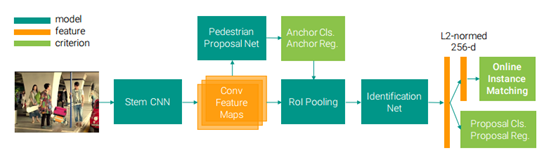
本文是將行人檢測網路和行人重識別網路聯合在一起,模型和演算法沒有創新,主要是解決了行人檢測網路的迴歸框大小和行人重識別網路的輸入影象大小之間的問題。使得整個端到端的過程更加接近真實場景的行人重識別。沒有新的代價函式。
其在Market資料集上的精度如下:
-
【CVPR2017】Learning Deep Context-aware Features over Body and Latent Parts for Person Reidentification
本文提出了所謂的身體潛在塊學習網路,其網路構架如下:
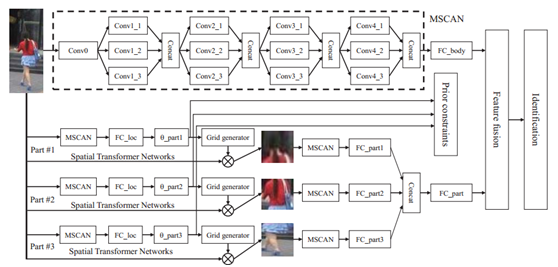
整個網路使用堆疊的CNN(MSCAN)對整張影象進行特徵提取,同時也將影象的部分作為一個輸入進入這個MSCAN進行特徵提取,最終將一個全域性特徵和三個區域性潛在塊特徵級聯起來進行最終的分類損失計算。其中影象的部分是使用NIPS2015的空間變換網產生的,該網路的作用為產生一個六維的向量來表示單應性矩陣,然後通過梯度下降來端到端的優化引數,從而達到自動學習需要將輸入影象進行怎樣的幾何變換才能使得最終的分類精度提高。本文構造了基於三個部分的損失函式如下:
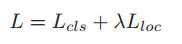
其物理意義第一項是分類損失,其實現為交叉熵損失,第二項是定位損失,即潛在塊的位置對最終分類的精度的損失,通過優化這個函式,可以得到潛在塊怎麼提取,也就是NIPS2015的空時轉換網的引數。論文中提到加入了定位損失,使得精度提高了9%。其Market精度如下圖所示:
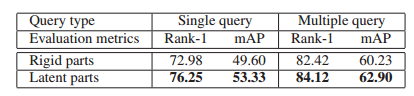
-
【CVPR2017】Multiple People Tracking by Lifted Multicut and Person Re-identification
本文主要的重點是跟蹤,沒有使用任何通用的行人重識別庫,主要是通過跟蹤來實現行人重識別但是不能跨非交疊視野。
-
【CVPR2017】Person Re-identification in the Wild
本文也是提出了整合行人檢測和行人重識別任務的端到端的行人重識別框架,同時推出了新的行人重識別資料庫PRW。沒有新的代價函式和網路構架。
-
【CVPR2017】Quality Aware Network for Set to Set Recognition
本文提出的是針對視訊序列的行人重識別方法。沒有進行詳細的閱讀。
-
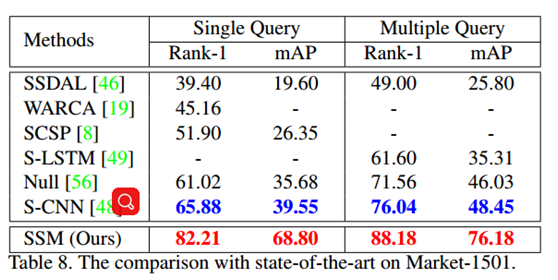
【CVPR2017】Re-ranking Person Re-identification with k-reciprocal Encoding
本文暑假何悠讀過,主要思想是利用已有的搜尋結果,通過公共鄰元關係進行再排序,其示意圖如下:

-
【CVPR2017】Scalable Person Re-identification on Supervised Smoothed Manifold
本文為AAAI2016可擴充套件流形在行人重識別中的應用,其主要核心思想是使用監督嵌入流形來對行人影象特徵向量進行降維表示,同時保證了降維時對類內距離和類間距離的約束,可擴充套件流形與普通流形所不一樣的地方在於,使用可擴充套件流行即在流形嵌入過程中除了對其鄰元關係進行保持以外,還可以擴充套件嵌入全域性的相互關係。即下圖的affinity graph:
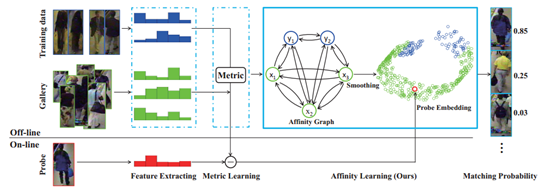
本文使用CNN特徵作為本演算法的輸入,本演算法屬於子空間學習(流形學習),最終Market精度如圖所示:
該度量學習演算法能提升CNN特徵的較大精度。
-
【CVPR2017】See the Forest for the Trees
本文為使用注意力機制的迴圈神經網路在視訊行人重識別領域的應用,其所提創新模組如下圖所示:
-
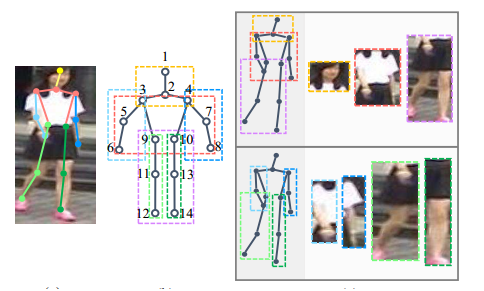
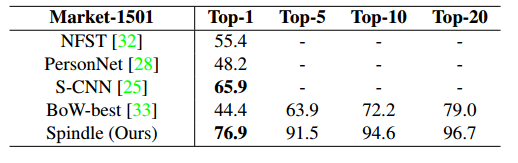
【CVPR2017】Spindle Net Person Re-identification with Human Body Region Guided
本文使用預訓練的人體姿態估計先檢測出人體關節點,然後對其進行區域性特徵提取,與我暑假期間所做工作相似:
但從文章末尾的表格可以看出本文主要的精度來自於全域性影象,身體區域特徵對整體精度提升很小。其網路構架如下:
並且其融合區域性和全域性特徵存在大量的全連線引數,計算代價極大,並且效果並未提升很多,融合方式不合理,其在market上的精度:
ICCV2017
-
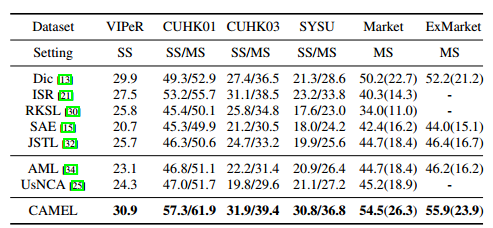
【ICCV17】Cross-view Asymmetric Metric Learning for Unsupervised Re-id
中山大學鄭偉詩團隊的經典演算法延續,唯一不一樣的地方在於改成了非監督的演算法。其核心思想在於先使用K-means聚類給出初始的類標籤,在進行度量學習,所使用的時傳統特徵,其精度如下:
-
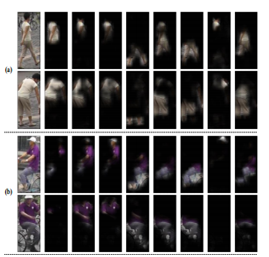
【ICCV17】Deeply-Learned Part-Aligned Representations for Person Re-Identification
該文章與暑假讀過的端到端的注意力網路for Reid非常相似,只是沒有使用LSTM迴圈神經網路,並且還提升了精度,其效果如下:

本文的主要思想為:在特徵圖上學習一個Mask,Mask在對應位置的值得大小被認為是Attention需要側重的程度,本文使用了NLP領域應用廣泛而且也相對較為先進的Attention機制,其目標函式為普通Triplet loss,如下:
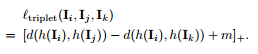
本文最後的融合方式也是直接級聯,證明了全域性結合區域性的方式能達到更好的精度:

-
【ICCV17】Group Re-Id via Unsupervised Transfer of Sparse Features Encoding
針對野外行人重識別提出的組匹配演算法,沒有使用標準行人重識別資料集。其演算法主要思想為使用跟蹤資訊或者視訊資訊構成多張行人照片的組資訊,從而採用集合到集合的匹配策略,適用於基於視訊行人重識別。
-
【ICCV17】In Defense of the Triplet Loss for Person Re-Identification
提出了目前為止精度最高的Triplet loss 函式:
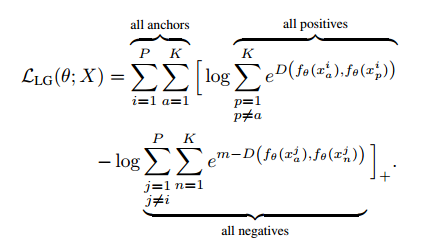
其物理意義在於取出Batch當中類內最大的距離和類間最小的距離進行Triplet loss計算,有效增加了Hard Mining的能力,同時本文也採用了Soft-margin的思想,如下圖所示:
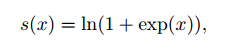
其在market庫上到達了現在最高的精度如下:

本文的trick在於使用了最新的網路構架殘差網,相比較而言比vgg的baseline 會更高一些。
-
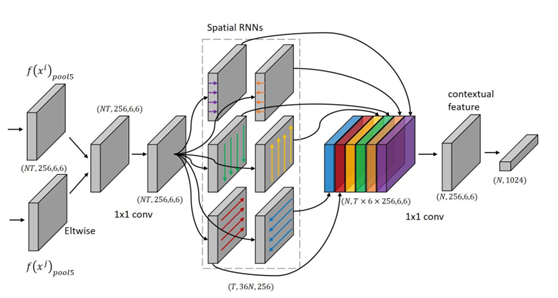
【ICCV17】Jointly Attentive Spatial-Temporal Pooling Networks for Video-based Person Re-Identification
本文是針對視訊的行人重識別網路構架,幾乎照抄了Attention機制的新形式Attentive pooling 在NLP當中的形式,結構如下:
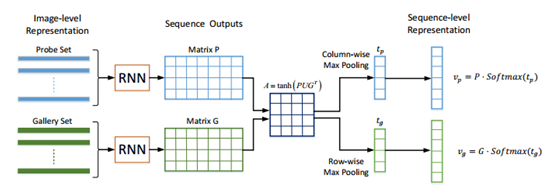
在自然語言理解領域有許多針對序列建模的方法和演算法模型,其實遠超於影象領域對序列的建模演算法,涉及序列建模可借鑑NLP。
-
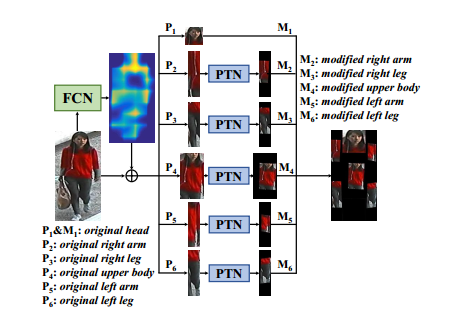
【ICCV17】Pose-driven Deep Convolutional Model for Person Re-identification
本文與CVPR2017作者相同,是基於之前的工作,同樣採用了預訓練的關節檢測網路:
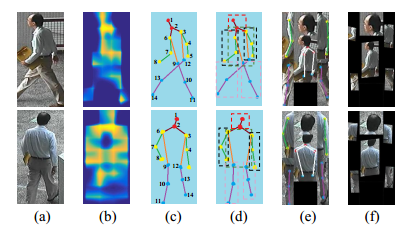
與CVPR2017 Spindle Net Person Re-identification with Human Body Region Guided不一樣的地方在於,被檢測出的身體部分,要通過NIPS2015的時空變換網(STN)進行幾何旋轉和縮放後,再進行特徵提取和融合,是整合了CVPR2017中使用STN的網路和pose關節點檢測網路的混合構架,其示意圖如下:
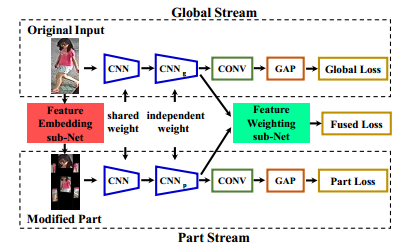
最終的融合方式也更加合理,使用了avgpooling之後將part stream和global stream融合起來:
其融合的方式公式化如下:
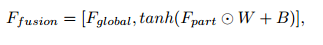
相當於級聯了和全域性特徵一樣長的區域性特徵,而這個區域性特徵是使用權重相加方式合成的。與我們自己的工作不一樣。
-
【ICCV17】RGB-Infrared Cross-Modality Person Re-Identification
本文針對紅外影象跨模態地重識別行人構建了網路,並且分析了雙流網路和單流網路的區別,最終採用獨特的Zero-Padding模式進行訓練,其框架如下:
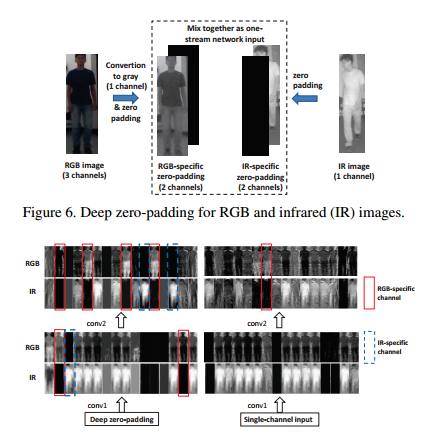
是一篇提供了很多訓練網路經驗的文章,雖然其資料我們不經常能夠獲取得到。
-
【ICCV17】SVDNet for Pedestrian Retrieval
本文是一個傳統方法與深度網路的結合,主要目的是利用SVD來對學習到的卷積核進行提煉,即希望學習到的卷積核相互正交,這樣不僅可以減少引數,同時可以去除噪聲,但是並非端到端演算法,實現過程比較複雜,其框架如下:

最終實驗證明,SVD大幅度提高了行人重識別的精度:
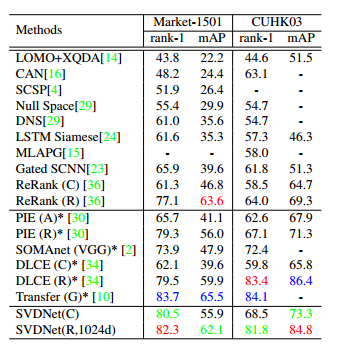
-
【ICCV17】Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro
本文通過生成對抗網路,生成更多的"人"圖片:

通過增強訓練樣本,來使得網路的精度能夠提高,同時也推出了新資料集vitro。
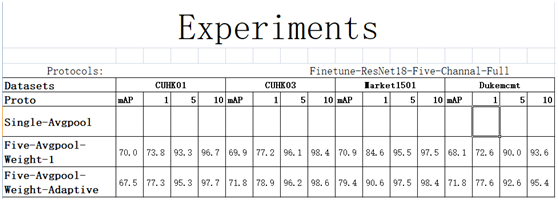
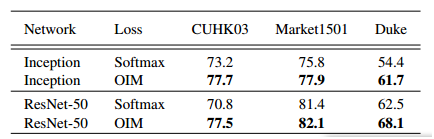
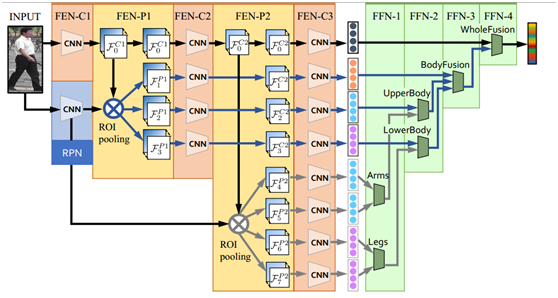
針對行人重識別任務的分塊多通道自適應融合深度神經網路
網路構架圖如下:
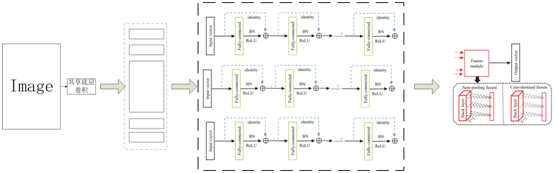
創新點:
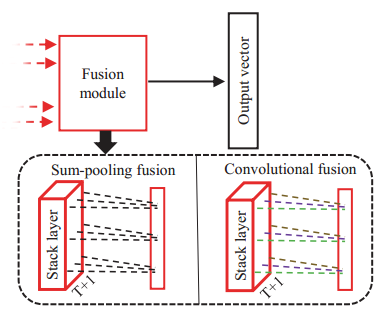
我們的融合模組採用區域性全連線方式,學習到的權重經試驗分析合理。
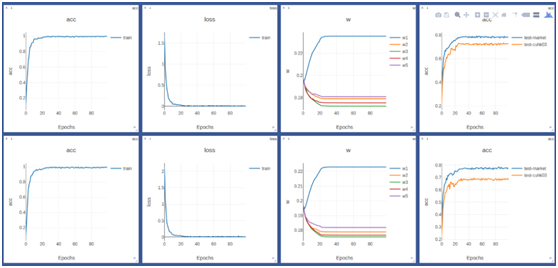
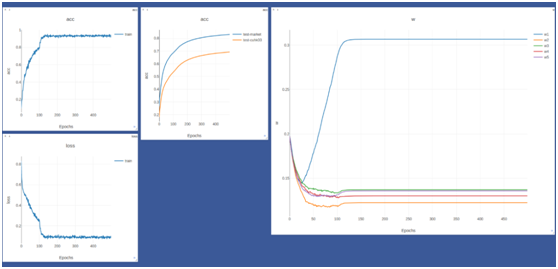
其中w1為全域性流權重等於0.4其他w2,w3,w4,w5分別為頭,衣服,褲子,腿和鞋所對應的位置,分別為1.1,1.9,1.8,1.3在market資料庫上。
在CUHK01資料庫上也表現出相同的趨勢:
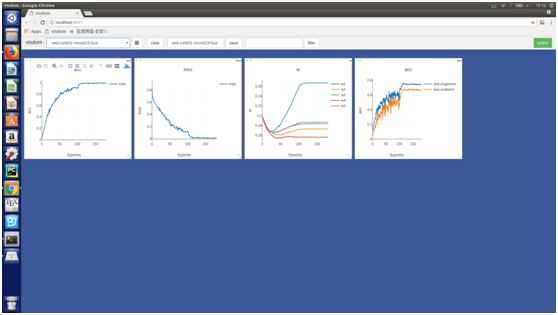
同樣我們在CUHK03資料庫上也做了對比試驗:
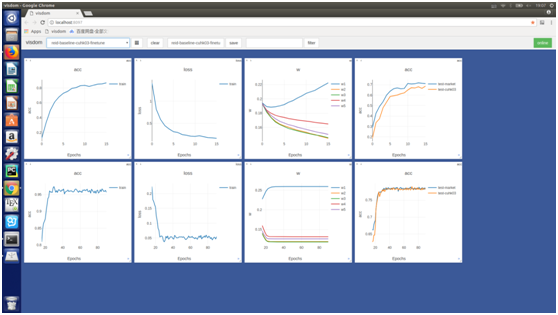
通過對比試驗我們發現在每個庫上,使用自適應權重均能獲得較大提升:
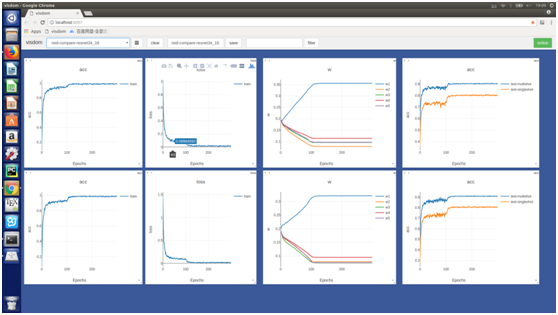
目標函式採用流形對齊中的強約束條件:
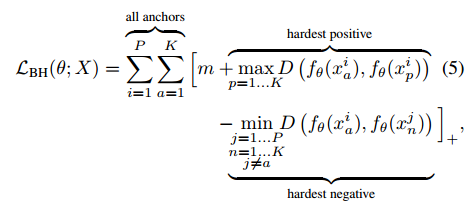
最大類內距離要小於最小類間距離。
我們的精度: