
使用selenium+BeautifulSoup 抓取京東商城手機資訊
阿新 • • 發佈:2018-11-23
1.準備工作:
- chromedriver 傳送門:國內:http://npm.taobao.org/mirrors/chromedriver/ vpn:
- selenium
- BeautifulSoup4(美味湯)
pip3 install selenium
pip3 install BeautifulSoup4
chromedriver 的安裝請自行百度。我們直奔主題。
起飛前請確保準備工作以就緒...
2.分析網頁:
目標網址:https://www.jd.com/


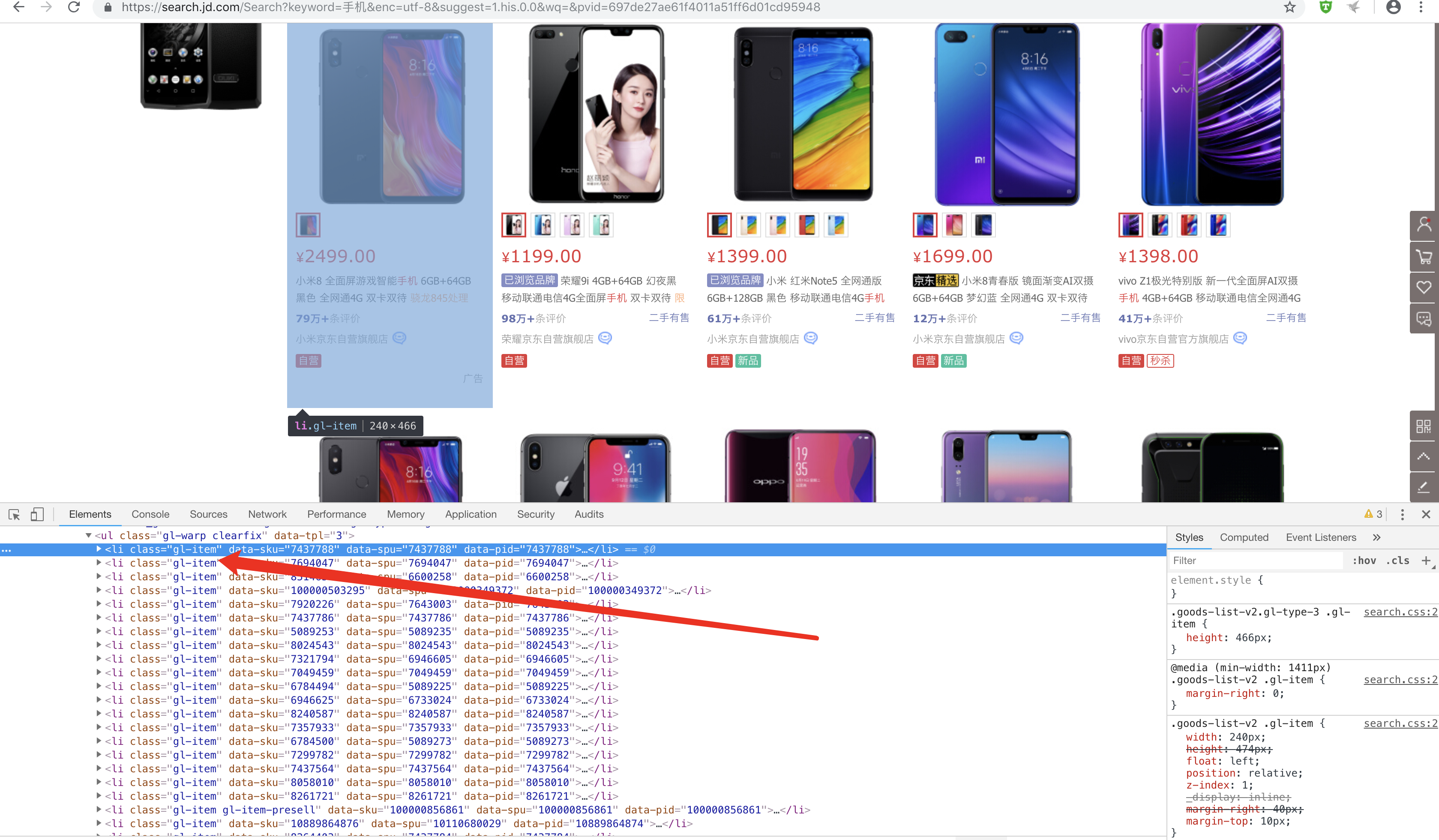
所有item均儲存在class="gl-item"裡面
需求:
- 使用selenium 驅動瀏覽器自動偵測到input輸入框,輸入框中輸入“手機”,點選搜尋按鈕.
- 使用seleinum抓取發揮頁面的總頁碼,並模擬手動翻頁
- 使用BeautifulSoup分析頁面,抓取手機資訊
從入口首頁進入查詢狀態
1 # 定義入口查詢介面 2 def search(): 3 browser.get('https://www.jd.com/') 4 try: 5 #查詢搜尋框及搜尋按鈕,輸入資訊並點選按鈕 6 input = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#key"))) 7 submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, "#search > div > div.form > button"))) 8 input[0].send_keys('手機') 9 submit.click()10 # 獲取總頁數 11 page = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, '#J_bottomPage > span.p-skip > em:nth-child(1) > b'))) 12 return page[0].text 13 # 如果異常,遞迴呼叫本函式 14 except TimeoutException: 15 search()
查詢結束後模擬翻頁
1 # 翻頁 2 def next_page(page_number): 3 try: 4 # 滑動到網頁底部,加載出所有商品資訊 5 browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") 6 time.sleep(4) 7 html = browser.page_source 8 # 當網頁到達100頁時,下一頁按鈕失效,所以選擇結束程式 9 while page_number == 101: 10 exit() 11 # 查詢下一頁按鈕,並點選按鈕 12 button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '#J_bottomPage > span.p-num > a.pn-next > em'))) 13 button.click() 14 # 判斷是否載入到本頁最後一款產品Item(每頁顯示60條商品資訊) 15 wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR, "#J_goodsList > ul > li:nth-child(60)"))) 16 # 判斷翻頁成功 17 wait.until(EC.text_to_be_present_in_element((By.CSS_SELECTOR, "#J_bottomPage > span.p-num > a.curr"), str(page_number))) 18 return html 19 except TimeoutException: 20 return next_page(page_number)
解析頁面上的a標籤
# 解析每一頁面上的a連結 def parse_html(html): """ 解析商品列表網頁,獲取商品的詳情頁 """ soup = BeautifulSoup(html, 'html.parser') items = soup.select('.gl-item') for item in items: a = item.select('.p-name.p-name-type-2 a') link = str(a[0].attrs['href']) if 'https:' in link: continue else: link = "https:"+link yield link
根據url 擷取商品id 獲取價格資訊
# 獲取手機價格,由於價格資訊是請求另外一個地址https://p.3.cn/prices/mgets?skuIds=J_+product_id def get_price(product_id): url = 'https://p.3.cn/prices/mgets?skuIds=J_' + product_id response = requests.get(url,heeders) result = ujson.loads(response.text) return result
進入item商品詳情頁
# 進入詳情頁 def detail_page(link): """ 進入item詳情頁 :param link: item link :return: html """ browser.get(link) try: browser.execute_script("window.scrollTo(0, document.body.scrollHeight);") time.sleep(3) html = browser.page_source return html except TimeoutException: detail_page(link)
1 # 獲取詳情頁的手機資訊 2 def get_detail(html,result): 3 """ 4 獲取詳情頁的資料 5 :param html: 6 :return: 7 """ 8 dic ={} 9 soup = BeautifulSoup(html, 'html.parser') 10 item_list = soup.find_all('div', class_='Ptable-item') 11 for item in item_list: 12 contents1 = item.findAll('dt') 13 contents2 = item.findAll('dd') 14 for i in range(len(contents1)): 15 dic[contents1[i].string] = contents2[i].string 16 17 dic['price_jd '] = result[0]['p'] 18 dic['price_mk '] = result[0]['m'] 19 print(dic)
滴滴滴.. 基本上的思路就醬紫咯.. 傳送門依舊開啟直github: https://github.com/shinefairy/spider/tree/master/Crawler
end~