
POJ - 2002 Squares 數正方形【二分】【雜湊表】
Squares
題意
平面上有N個點,任取4個點,求能組成正方形的不同組合方式有多少種;相同的四個點,不同順序構成的正方形視為同一正方形
分析
做法1
先列舉兩個點,通過計算得到另外兩個點,然後檢查點集中是否存在這兩個點
(tx,ty)繞座標原點旋轉W(弧度制)之後點的座標為(x,y)
double x = tx * cos(w) - ty * sin(w);
double y = tx * sin(w) + ty * cos(w);
假如枚舉出的兩個點分別是A,B,那麼C點就是B圍繞A旋轉90度,D就是A圍繞B旋轉-90度,或者C點就是B圍繞A旋轉-90度,D就是A圍繞B旋轉90度
因為一條邊可能對應兩個方向不同的正方形嘛,那麼怎麼使列舉的時候不會重複計算正方形呢
假如列舉A是用下標i,那麼列舉B的時候j要從i+1開始列舉
另外,在二分查詢點的時候,應該在排序後的[j+1,n]的下標範圍內二分查詢,也就是查詢B點後面的點,這樣點的列舉就有次序了,就不會出現重複記數了
#include<stdio.h> #include<iostream> #include<string.h> #include<queue> #include<cstdio> #include<string> #include<math.h> #include<algorithm> #include<map> #include<set> #include<stack> #define mod 500500507 #define INF 0x3f3f3f3f #define eps 1e-5 #define LL long long using namespace std; const int maxn=1000+10; struct Point{ int x,y; Point(){} Point(int a,int b){ x=a;y=b; } bool operator < (const Point &b){ if(x==b.x) return y<b.y; return x<b.x; } }p[maxn]; bool BS(Point po,int l,int r){ int left=l,right=r,mid; while(left<=right){ int mid=(left+right)>>1; if(p[mid].x==po.x&&p[mid].y==po.y) return true; if(p[mid]<po) left=mid+1; else right=mid-1; } return false; } void transXY(Point a,Point b,Point &c,int f){ int tx=b.x-a.x,ty=b.y-a.y; c.x=a.x-ty*f; c.y=a.y+tx*f; } int main(){ int n; while(scanf("%d",&n)!=EOF&&n){ for(int i=1;i<=n;i++){ scanf("%d%d",&p[i].x,&p[i].y); } sort(p+1,p+1+n); int ans=0; for(int i=1;i<=n-3;i++){ for(int j=i+1;j<=n-2;j++){ Point c,d; transXY(p[i],p[j],c,1); transXY(p[j],p[i],d,-1); if(BS(c,j+1,n)&&BS(d,j+1,n)) ans++; transXY(p[i],p[j],c,-1); transXY(p[j],p[i],d,1); if(BS(c,j+1,n)&&BS(d,j+1,n)) ans++; } } printf("%d\n",ans); } }
做法2
先列舉兩個點,通過數學公式得到另外兩個點,使得這四個點能夠成正方形。然後檢查點集中是否存在計算出來的那兩個點,若存在,說明有一個正方形
但是這種做法會使同一個正方形被列舉4次,因此最後結果要除以4

已知:正方形的兩個點 (x1,y1) (x2,y2)
則:正方形另外兩個點的座標為
x3=x1+(y1-y2) y3= y1-(x1-x2)
x4=x2+(y1-y2) y4= y2-(x1-x2)
或
x3=x1-(y1-y2) y3= y1+(x1-x2)
x4=x2-(y1-y2) y4= y2+(x1-x2)
利用hash[]標記散點集
我個人推薦key值使用 平方求餘法
即標記點x y時,key = (x^2+y^2)%prime
此時key值的範圍為[0, prime-1]
由於我個人的標記需求,我把公式更改為key = (x^2+y^2)%prime+1
使得key取值範圍為[1, prime],則hash[]大小為 hash[prime]
其中prime為 小於 最大區域長度(就是散點個數)n的k倍的最大素數,
即小於k*n 的最大素數 (k∈N*)
為了儘量達到key與地址的一一對映,k值至少為1,
當為k==1時,空間利用率最高,但地址衝突也相對較多,由於經常要為解決衝突開放定址,使得尋找key值耗時O(1)的情況較少
當n太大時,空間利用率很低,但由於key分佈很離散,地址衝突也相對較少,使得尋找鍵值耗時基本為O(1)的情況
提供一組不同k值的測試資料
K==1, prime=997 1704ms
K==2, prime=1999 1438ms
K==8, prime=7993 1110ms
K==10, prime=9973 1063ms
K==30, prime=29989 1000ms
K==50, prime=49999 1016ms
K==100, prime=99991 1000ms
最後解決的地址衝突的方法,這是hash的難點。我使用了 鏈地址法
typedef class HashTable
{
public:
int x,y; //標記key值對應的x,y
HashTable* next; //當出現地址衝突時,開放定址
HashTable() //Initial
{
next=0;
}
}Hashtable;
Hashtable* hash[prime]; //注意hash[]是指標陣列,存放地址
//hash[]初始化為NULL (C++初始化為0)先解釋所謂的“衝突”
本題對於一組(x,y),通過一個函式hash(x,y),其實就是上面提到的key的計算公式
key = (x^2+y^2)%prime+1
於是我們得到了一個關於x,y的key值,但是我們不能保證key與每一組的(x,y)都一一對應,即可能存在 hash(x1,y1) = hash(x2,y2) = key
處理方法:
(1) 當讀入(x1, y1)時,若hash[key]為NULL,我們直接申請一個臨時結點Hashtable* temp,記錄x1,y1的資訊,然後把結點temp的地址存放到hash[key]中
此後我們就可以利用key訪問temp的地址,繼而得到x1,y1的資訊
(2) 當讀入(x2, y2)時,由於hash(x1,y1) = hash(x2,y2) = key,即(x2, y2)的資訊同樣要存入hash[key],但hash[key]已存有一個地址,怎麼辦?
注意到hash[key]所存放的temp中還有一個成員next,且next==0,由此,我們可以申請一個新結點存放x2,y2的資訊,用next指向這個結點
此後我們利用key訪問temp的地址時,先檢查temp->x和temp->y是否為我們所需求的資訊,若不是,檢查next是否非空,若next非空,則檢查下一結點,直至 next==0
當檢查完所有next後仍然找不到所要的資訊,說明資訊原本就不存在
就是說hash[key]只儲存第一個值為key的結點的地址,以後若出現相同key值的結點,則用前一個結點的next儲存新結點的地址,其實就是一個連結串列
簡單的圖示為:
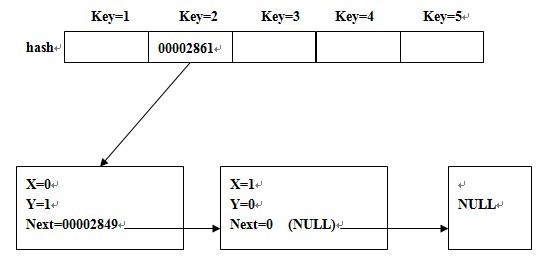
//Memory Time
//652K 1438MS
#include<iostream>
using namespace std;
const int prime=1999; //長度為2n區間的最大素數 (本題n=1000)
//其他prime可取值:
// 1n 區間: 997 1704ms
// 2n 區間: 1999 1438ms
// 8n 區間: 7993 1110ms
// 10n 區間: 9973 1063ms
// 30n 區間: 29989 1000ms
// 50n 區間: 49999 1016ms
// 100n區間: 99991 1000ms
//為了儘量達到key與地址的一一對映,hash[]至少為1n,
//當為1n時,空間利用率最高,但地址衝突也相對較多,由於經常要為解決衝突開放定址,使得尋找key值耗時O(1)的情況較少
//當n太大時,空間利用率很低,但由於key分佈很離散,地址衝突也相對較少,使得尋找鍵值耗時基本為O(1)的情況
typedef class
{
public:
int x,y;
}Node;
typedef class HashTable
{
public:
int x,y; //標記key值對應的x,y
HashTable* next; //當出現地址衝突時,開放定址
HashTable() //Initial
{
next=0;
}
}Hashtable;
Node pos[1001];
Hashtable* hash[prime]; //hash[]是指標陣列,存放地址
void insert_vist(int k)
{
int key=((pos[k].x * pos[k].x)+(pos[k].y * pos[k].y))%prime +1; //+1是避免==0
//使key從[0~1998]後移到[1~1999]
if(!hash[key])
{
Hashtable* temp=new Hashtable;
temp->x=pos[k].x;
temp->y=pos[k].y;
hash[key]=temp;
}
else //hash[key]已存地址,地址衝突
{
Hashtable* temp=hash[key];
while(temp->next) //開放定址,直至next為空
temp=temp->next;
temp->next=new HashTable; //申請新結點,用next指向,記錄x、y
temp->next->x=pos[k].x;
temp->next->y=pos[k].y;
}
return;
}
bool find(int x,int y)
{
int key=((x * x)+(y * y))%prime +1;
if(!hash[key]) //key對應的地址不存在
return false;
else
{
Hashtable* temp=hash[key];
while(temp)
{
if(temp->x==x && temp->y==y)
return true;
temp=temp->next;
}
}
return false;
}
int main(void)
{
int n;
while(cin>>n)
{
if(!n)
break;
memset(hash,0,sizeof(hash)); //0 <-> NULL
for(int k=1;k<=n;k++)
{
cin>>pos[k].x>>pos[k].y;
insert_vist(k); //插入雜湊表,標記散點
}
int num=0; //正方形的個數
for(int i=1;i<=n-1;i++)
for(int j=i+1;j<=n;j++)
{
int a=pos[j].x-pos[i].x;
int b=pos[j].y-pos[i].y;
int x3=pos[i].x+b;
int y3=pos[i].y-a;
int x4=pos[j].x+b;
int y4=pos[j].y-a;
if(find(x3,y3) && find(x4,y4))
num++;
x3=pos[i].x-b;
y3=pos[i].y+a;
x4=pos[j].x-b;
y4=pos[j].y+a;
if(find(x3,y3) && find(x4,y4))
num++;
}
cout<<num/4<<endl; //同一個正方形枚舉了4次
}
return 0;
}