
MongoDB的複製源oplog

之前有說過MongoDB的複製是非同步複製的,其實也就是通過oplog來實現的,他存放在local資料庫中,我們來查詢一下主節點的日誌大小。
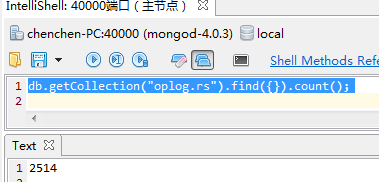
除了主節點有oplog之外,其他節點也就有oplog,如果沒有的話,主節點掛了,其他節點成為主節點,那怎麼獲取資料呢。其他節點的oplog是從主節點這邊複製過去的。
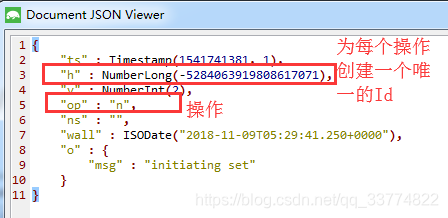
我們來看一下oplog裡面的一條資料,如下圖。
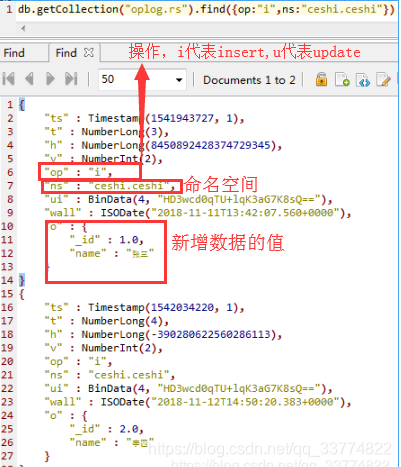
現在我們測試一下,在主節點裡面新增兩條記錄,然後查詢主節點的oplog,如下圖,看看資料有什麼特徵。
相關推薦
MongoDB的複製源oplog
之前有說過MongoDB的複製是非同步複製的,其實也就是通過oplog來實現的,他存放在local資料庫中,我們來查詢一下主節點的日誌大小。 除了主節點有oplog之外,其他節點也就有oplog,如果沒有的話,主節點掛了,其他節點成為主節點,那怎麼獲取資料呢。其他節點的oplog
部署MongoDB複製集(副本集)
環境 作業系統:Ubuntu 18.04 MongoDB: 4.0.3 伺服器 首先部署3臺伺服器,1臺主節點 + 2臺從節點 3臺伺服器的內容ip分別是: 10.140.0.5 (主節點)
MongoDB複製集與Raft協議異同點分析
此文已由作者溫正湖授權網易雲社群釋出。 歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 一、日誌複製流程: a、raft leader節點在接收client請求後,先將請求寫到日誌中,再將日誌通過AppendEntries RPC傳送到follow上。如果收到了大多數follow的確認
Ubuntu 18.04下部署MongoDB複製集(副本集)
環境 作業系統: 18.04 MongoDB: 4.0.3 伺服器 首先部署3臺伺服器,1臺主節點 + 2臺從節點 3臺伺服器的內容ip分別是: 10.140.0.5 (主節點) 10.140.0.6 (從節點01)
認識MongoDB複製集
從這一篇開始,我們要踏上MongoDB進階之路啦,想想還有點小開心呢。一筐豬鎮樓。 引入複製集 我們先來想一個場景,如果本地專案使用MongoDB,都是下載,安裝,連線一條龍服務。這實際也就是單點模式,那如果我們專案要上線了,這個時候還是一個數據庫,就可能出問題。比如我們寫了個淘寶(噓,假裝是
Windows搭建MongoDB複製集
上篇,我們已經知道了什麼是MongoDB的複製集,不知道的可以檢視上篇哦,傳送門來了。 光說不練,假把式,咱來自己搭建一個複製集。先下載安裝哦,不知道的檢視上篇哦,https://blog.csdn.net/qq_33774822/article/details/83585156。 咱
單臺MongoDB例項開啟Oplog
背景 隨著資料的積累,MongoDB中的資料量越來越大,資料分析團隊從資料庫中抽取變化資料(假如依據欄位createdatetime,transdatetime),越來越困難。我們知道MongoDB的副本集有一個數據結構Oplog,裡面儲存了Primary節點的所有寫操作(此處的寫操作是指查詢以外的操作,包
mongodb複製集Replica Set使用簡介
MongoDB高可用 對於MongoDB,可以支援使用單機模式提供服務,但是在實際的生產環境中,單機模式將面臨很大的風險,一旦這個資料庫服務出現問題,就會導致線上的服務出現錯誤甚至崩潰。因此,在實際生產環境下,需要對MongoDB做相應的主備處理,提高資料庫服務的可用性。 對於提高可用性,一些博文裡提到了
Mongodb複製(副本集)
花了不少時間做這個,各種出錯,特此分享一下自己的經驗。希望可以有所幫助。 1.首先要關閉MongoDB,本例部署主節點,路徑都是MongoDB安裝的路徑。 2.還要部署幾個從節點,本例為兩個從節點。在此之前先另外建立兩個節點需要的目錄。 3.新建立的兩個目錄只要複
MongoDB複製整合員及狀態轉換
此文已由作者溫正湖授權網易雲社群釋出。 歡迎訪問網易雲社群,瞭解更多網易技術產品運營經驗。 複製集(Replica Set)是MongoDB核心元件,相比早期版本採用的主從(Master-Slave)架構,複製集具有很多天然的優勢,包括自動故障恢復、多機房部署、讀寫行為控制等。本文介紹複製集中最基礎的部分,
MongoDB複製集搭建
最近在學習mongodb,看文件時看到複製集這塊覺得挺有意思,於是便動手搭建了一下mongodb複製集 mongodb的複製至少需要兩個節點。其中一個是主節點,負責處理客戶端請求,其餘的都是從節點,負責
Raft與MongoDB複製集協議比較
在一文搞懂raft演算法一文中,從raft論文出發,詳細介紹了raft的工作流程以及對特殊情況的處理。但演算法、協議這種偏抽象的東西,僅僅看論文還是比較難以掌握的,需要看看在工業界的具體實現。本文關注MongoDB是如何在複製集中使用raft協議的,對raft協議做了哪些擴充套件。 閱讀本文,需要對Mong
mongodb複製集操作步驟
複製集的好處: <1> 資料備份。每一個從節點都是一個備份 <2> 資料恢復。當主節點機器死掉後,可以讓從節點成為主節點,保證程式正常執行 <3> 讀寫分離。即主節點寫、從節點讀。如果所有的讀寫操作全部放在主
MongoDB複製集簡單操作
一、MongoDB複製集介紹 1、如下圖所示有一個數據庫叢集,叢集中有三臺資料庫伺服器,一臺活躍伺服器和兩臺備份伺服器。當活躍伺服器A發生故障時,會根據權重演算法從備份伺服器B和C中選出B作為新的活躍伺服器,而當A恢復時當成備份伺服器,繼續加入到整個資料庫叢集中工作,這就是MongoDB的副本集。 2、配
MongoDB複製集搭建(Window10系統下)
一、獲取mongodb安裝包 本示例mongo版本:mongodb-win32-x86_64-3.4.17.zip 二 、安裝mongo (1)解壓 mongodb-win32-x86_64-3.4.17.zip,解壓之後檔名可自定義。Mongo
三、MongoDB複製集
一、複製集特性 資料一致性 主是唯一的 沒有MySql那樣的雙主結構 大多數原則 叢集存活節點數小於等於1/2時,只可讀,不可寫 從庫無法寫入 MySql從庫的readonly對具有super許可權的賬戶無效 自動容災
MongoDB 複製機制
一、複製原理 MongoDB的複製功能是使用操作日誌oplog實現的,oplog包含主節點(Master)的每一次寫操作,oplog是local本地資料庫中的一個數據集合,其它非主節點(Secondary)通過讀取主節點的oplog集合中的記錄同步到對應的集合,然後再寫入到自身的local資料庫的oplog
mongoDB複製集維護和切換——記憶體限制
使用mongoDB是因為用到了graylog,部署執行2-3個月之後,發現mongoDB佔用實體記憶體巨大,50G+,公司的資料架構居然質問我為什麼不設定-Xmx堆記憶體大小,我尼瑪只能呵呵醉了! 簡單說mongoDB似乎沒有配置項可以限制使用實體記憶體,粗略理解mongo
利用log4mongo-java+mongodb複製集搭建java日誌系統
The log4mongo-java 0.6 release added full support for replica sets. While earlier releases would work with replica sets, you could specify only one host
MongoDB 複製集(Replica Set)
複製集(replica Set)或者副本集是MongoDB的核心高可用特性之一,它基於主節點的oplog日誌持續傳送到輔助節點,並重放得以實現主從節點一致。再結合心跳機制,當感知到主節點不可訪問或宕機的情形下,輔助節點通過選舉機制來從剩餘的輔助節點中推選一