
map與unordered_map的區別
內部的原理實現:
map:【標頭檔案為#include<map>】map內部是一顆紅黑樹(非嚴格平衡二叉樹),紅黑樹有自動排序的功能,所以map內部的所有元素都是有序的,紅黑樹的每一個節點都代表這map的一個元素。因此對map進行插入、刪除、查詢等操作都是相當於對紅黑樹進行操作。最後根據樹的中序遍歷可以將鍵值按照大小順序遍歷出來。
unordered_map:【標頭檔案#include<unordered_map>】unordered_map內部是一個雜湊表(散列表,把關健值對映到雜湊表中的某一個位置,這樣查詢時間複雜度是O(1)),元素的排列順序是無序的。
優缺點:
map:
1、優點:
(1)有序性:map結構的紅黑樹自身是有序的,但是要中序遍歷輸出
(2)時間複雜度低:內部結構時紅黑樹,紅黑樹很多操作都是在logn的時間複雜度下實現的,因此效率高。
2、缺點:
空間佔有率高,因為map內部實現是紅黑樹,雖然它時間複雜度低,執行效率高,但是因為每一個節點都需要額外儲存父 節點、孩子節點和紅黑樹性質,這樣使得每一個節點都佔用大量的空間。
3、應用場景:
應用於對順序有要求的問題,用map會更高效。
unordered_map:
1、優點:內部結構是雜湊表,查詢為O(1),效率高。
2、缺點:雜湊表的建立耗費時間。
3、應用場景: 對於頻繁查詢的問題,用unordered_map更高效。
總結:
1、記憶體佔用率問題轉化為 紅黑樹 VS 雜湊表,還是unordered_map記憶體佔用高。
2、但是unordered_map執行效率高。
3、對於unordered_map或unordered_set容器,其遍歷順序與建立該容器時輸入的順序不一定相同,因為遍歷是按照雜湊表從前往後依次遍歷的。
map和unordered_map的使用
unordered_map與map用法一致,裡面的元素以pair型別儲存。雖然底層實現完全不同,但是外部使用一致。
map:
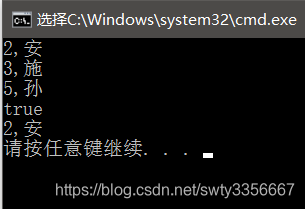
int main()
{
map<int,string> mymap;
mymap.insert(pair<int,string>(5,"孫"));
mymap.insert(pair<int,string>(2,"安"));
mymap.insert(pair<int,string>(3,"施"));
mymap.insert(pair<int,string>(3,"楊"));//key值唯一,相同的key插不進去
auto iter = mymap.begin();
while(iter != mymap.end())
{
cout<<iter->first<<","<<iter->second<<endl;
++iter;
}
auto iter2 = mymap.find(2);//返回一個指向key = 1的迭代器
if(iter2 != mymap.end())
{
cout<<"true"<<endl;
cout<<iter2->first<<","<<iter2->second<<endl;
}
}執行結果:無論怎麼插進去資料,都會按照key的大小順序排列,注意:key值唯一,兩個一樣的key插入時,第二條資料插不進去。
unordered_map:
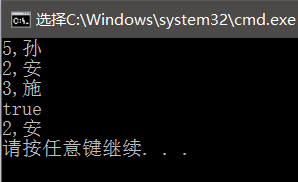
int main()
{
unordered_map<int,string> mymap;
mymap.insert(pair<int,string>(5,"孫"));
mymap.insert(pair<int,string>(2,"安"));
mymap.insert(pair<int,string>(3,"施"));
mymap.insert(pair<int,string>(3,"楊"));//key值唯一,相同的key插不進去
auto iter = mymap.begin();
while(iter != mymap.end())
{
cout<<iter->first<<","<<iter->second<<endl;
++iter;
}
auto iter2 = mymap.find(2);//返回一個指向key = 1的迭代器
if(iter2 != mymap.end())
{
cout<<"true"<<endl;
cout<<iter2->first<<","<<iter2->second<<endl;
}
}執行結果:以怎樣的順序插進unordered_map表,以怎樣的順序打印出來,不會進行自動排序,注意:key值唯一,兩個一樣的key插入時,第二條資料插不進去。
count方法與find方法的區別
mymap.count(key):計算的是下標為key的位置有無資料,有返回1,無返回0
mymap.find(key):得到的物件時一個迭代器,需要對迭代器進行判斷是否是mymap.end(),如果是則無資料,如果不是則有資料
參考:https://blog.csdn.net/zjajgyy/article/details/65935473