
分散式系統原理(5)Quorum 機制
分散式系統原理(5)Quorum 機制
Quorum 機制是一種簡單有效的副本管理機制。本節首先討論一種最簡單的副本控制規則
write-all-read-one,在此基礎上,放鬆約束,討論 quorum 機制
約定
為了簡化討論,本節先做這樣的約定:更新操作(write)是一系列順序的過程,通過其他機制確定更新操作的順序(例如 primary-secondary 架構中由 primary 決定順序),每個更新操作記為 wi,i 為更新操作單調遞增的序號,每個 wi 執行成功後副本資料都發生變化,稱為不同的資料版本,記作 vi。假設每個副本都儲存了歷史上所有版本的資料
Write-All-Read-One(簡稱 WARO)是一種最簡單的副本控制規則,顧名思義即在更新時寫所有的副本,只有在所有的副本上更新成功,才認為更新成功,從而保證所有的副本一致,這樣在讀取資料時可以讀任一副本上的資料
假設有一種 magic 的機制,當某次更新操作 wi 一旦在所有 N 個副本上都成功,此時全域性都能知道這個資訊,此後讀取操作將指定讀取資料版本為 vi 的資料,稱在所有 N 個副本上都成功的更新操作為“成功提交的更新操作”,稱對應的資料為“成功提交的資料”。 在 WARO 中,如果某次更新操作 wi 在某個副本上失敗,此時該副本的最新的資料只有 vi-1,由於不滿足在所有 N 個副本上都成功,則 wi 不是一個“成功提交的更新操作”,此時,雖然其他 N-1 個副本上最新的資料是 vi,但 vi 不是一個“成功提交的資料”,最新的成功提交的資料只是 vi-1
這裡需要特別強調的是,在工程實踐中,這種 magic 的機制往往較難實現或效率較低。通常實現這種 magic 機制的方式就是將版本號資訊存放到某個或某組元資料伺服器上。假如更新操作非常頻繁,那麼記錄更新成功的版本號 vi 的操作將成為一個關鍵操作,容易成為瓶頸。另外,為了實現強一致性,在讀取資料的前必須首先讀取元資料中的版本號,在大壓力下也容易因為元資料伺服器的效能造成瓶頸
分析一下 WARO 的可用性。由於更新操作需要在所有的 N 個副本上都成功,更新操作才能成功,所以一旦有一個副本異常,更新操作失敗,更新服務不可用。對於更新服務,雖然有 N 個副本,但系統無法容忍任何一個副本異常。另一方面,N 個副本中只要有一個副本正常,系統就可以提供讀服務。對於讀服務而言,當有 N 個副本時,系統可以容忍 N-1 個副本異常。從上述分析可以發現 WARO 讀服務的可用性較高,但更新服務的可用性不高,甚至雖然使用了副本,但更新服務的可用性等效於沒有副本
Quorum 定義
WARO 犧牲了更新服務的可用性,最大程度的增強讀服務的可用性。下面將 WARO 的條件進行鬆弛,從而使得可以在讀寫服務可用性之間做折中,得出 Quorum 機制
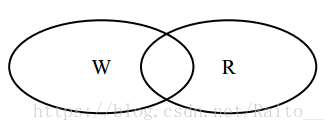
在 Quorum 機制下,當某次更新操作 wi 一旦在所有 N 個副本中的 W 個副本上都成功,則就稱該更新操作為“成功提交的更新操作”,稱對應的資料為“成功提交的資料” 。令 R>N-W,由於更新操作 wi 僅在 W 個副本上成功,所以在讀取資料時,最多需要讀取 R 個副本則一定能讀到 wi 更新後的資料 vi 。如果某次更新 wi 在 W 個副本上成功,由於 W+R>N,任意 R 個副本組成的集合一定與成功的 W 個副本組成的集合有交集,所以讀取 R 個副本一定能讀到 wi 更新後的資料 vi。 如圖 2-10,Quorum 機制的原理可以文森圖表示:
例如:某系統有 5 個副本,W=3,R=3,最初 5 個副本的資料一致,都是 v1,某次更新操作 w2 在前 3 副本上成功,副本情況變成(v2 v2 v2 v1 v1)。此時,任意 3 個副本組成的集合中一定包括v2
在上述定義中,令 W=N,R=1,就得到 WARO,即 WARO 是 Quorum 機制的一種特例
與分析 WARO 相似,分析 Quorum 機制的可用性。限制 Quorum 引數為 W+R=N+1。由於更新操作需要在 W 個副本上都成功,更新操作才能成功,所以一旦 N-W+1 個副本異常,更新操作始終無法在 W 個副本上成功,更新服務不可用。另一方面,一旦 N-R+1 個副本異常,則無法保證一定可以讀到與 W 個副本有交集的副本集合,則讀服務的一致性下降
例如:N=5, W=2, R=4 時,若 4 個副本異常,更新操作始終無法完成。若 3 個副本異常時,剩下的兩個副本雖然可以提供更新服務,但對於讀取者而言,在缺乏某些 magic 機制的,即如果讀取者不知道當前最新已成功提交的版本是什麼的時候,僅僅讀取 2 個副本並不能保證一定可以讀到最新的已提交的資料
這裡再次強調:僅僅依賴 quorum 機制是無法保證強一致性的。因為僅有 quorum 機制時無法確定最新已成功提交的版本號,除非將最新已提交的版本號作為元資料由特定的元資料伺服器或元資料叢集管理,否則很難確定最新成功提交的版本號。在下一節中,將討論在哪些情況下,可以僅僅通過 quorum 機制來確定最新成功提交的版本號
Quorum 機制的三個系統引數 N、W、 R 控制了系統的可用性,也是系統對使用者的服務承諾:資料最多有 N 個副本,但資料更新成功 W 個副本即返回使用者成功。對於一致性要求較高的 Quorum 系統,系統還應該承諾任何時候不讀取未成功提交的資料,即讀取到的資料都是曾經在 W 個副本上成功的資料
讀取最新成功提交的資料
上節中,假設有某種 magic 的機制使得讀取者知道當前已提交的資料版本號。本節取消這種假設,分析在 Quorum 機制下,如何始終讀取成功提交的資料,以及如何確定最新的已提交的資料
Quorum 機制只需成功更新 N 個副本中的 W 個,在讀取 R 個副本時,一定可以讀到最新的成功提交的資料。但由於有不成功的更新情況存在,僅僅讀取 R 個副本卻不一定能確定哪個版本的資料是最新的已提交的資料。對於一個強一致性 Quorum 系統
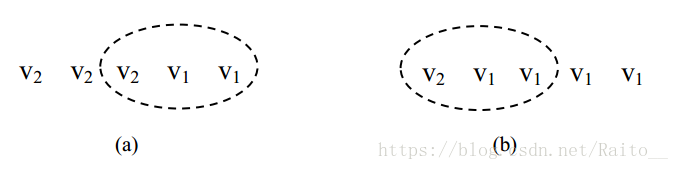
例如:N=5,W=3,R=3 的系統中,某時刻副本最大版本號為(v2 v2 v2 v1 v1)。注意,這裡繼續假設有 v2 的副本也有 v1,上述列出的只是最大版本號。此時,最新的成功提交的副本應該是 v2,因為從全域性看 v2 已經成功更新了 3 個副本。讀取任何 3 個副本,一定能讀到 v2。但僅讀 3 個副本時,有可能讀到(v2 v1 v1),如圖 2-11(a)。此時,由於 v2 蘊含 v1,可知 v1 是一個成功提交的版本,但卻不能判定 v2 一定是一個成功提交的版本。這是因為,圖 2-11(b),假設副本最大版本號為(v2 v1 v1 v1 v1),當讀取 3 個副本時也可能讀到(v2 v1 v1),此時 v2 是一個未成功提交的版本。所以在本例中,僅僅讀到(v2 v1 v1)時,可以肯定的是最新的成功提交的資料要麼是 v1 要麼是 v2,卻沒辦法確定究竟是哪一個
對於一個強一致性系統,應該始終讀取返回最新的成功提交的資料,在 quorum 機制下,要達到這一目的需要對讀取條件做進一步加強:
- 限制提交的更新操作必須嚴格遞增,即只有在前一個更新操作成功提交後才可以提交後一
個更新操作,從而成功提交的資料版本號必須是連續增加的 - 讀取 R 個副本,對於 R 個副本中版本號最高的資料
2.1. 若已存在 W 個,則該資料為最新的成功提交的資料
2.2. 若存在個數據少於 W 個,假設為 X 個,則繼續讀取其他副本,直若成功讀取到 W 個該版本的副本,則該資料為最新的成功提交的資料;如果在所有副本中該資料的個數肯定不滿足 W 個,則 R 中版本號第二大的為最新的成功提交的副本
依舊接上面的例子,在讀取到(v2 v1 v1)時,繼續讀取剩餘的副本,若讀到剩餘兩個副本為(v2 v2)則 v2 是最新的已提交的副本;若讀到剩餘的兩個副本為(v2 v1)或(v1 v1)則 v1 是最新成功提交的版本;若讀取後續兩個副本有任一超時或失敗,則無法判斷哪個版本是最新的成功提交的版本
可以看出,在單純使用 Quorum 機制時,若要確定最新的成功提交的版本,最多需要讀取 R+(W-R-1) =N 個副本,當出現任一副本異常時,讀最新的成功提交的版本這一功能都有可能不可用。實際工程中,應該儘量通過其他技術手段,迴避通過 Quorum 機制讀取最新的成功提交的版本。例如,當 quorum 機制與 primary-secondary 控制協議結合使用時,可以通過讀取 primary 的方式讀取到最新的已提交的資料
基於 Quorum 機制選擇 primary
本節介紹一種基於 quorum 機制選擇 primary 的技術。基於 primary-secondary 協議中, primary 負責進行更新操作的同步工作。現在基於 primary-secondary 協議中引入 quorum 機制,即 primary 成功更新 W 個副本(含 primary 本身)後向使用者返回成功。讀取資料時依照一致性要求的不同可以有不同的做法:如果需要強一致性的立刻讀取到最新的成功提交的資料,則可以簡單的只讀取 primary 副本上的資料即可,也可以通過上節的方式讀取;如果需要會話一致性,則可以根據之前已經讀到的資料版本號在各個副本上進行選擇性讀取;如果只需要弱一致性,則可以選擇任意副本讀取
在 primary-secondary 協議中,當 primary 異常時,需要選擇出一個新的 primary,之後 secondary副本與 primary 同步資料。 通常情況下,選擇新的 primary 的工作是由某一中心節點完成的,在引入quorum 機制後,常用的 primary 選擇方式與讀取資料的方式類似,即中心節點讀取 R 個副本,選擇R 個副本中版本號最高的副本作為新的 primary。新 primary 與至少 W 個副本完成資料同步後作為新的 primary 提供讀寫服務。首先, R 個副本中版本號最高的副本一定蘊含了最新的成功提交的資料。再者,雖然不能確定最高版本號的數是一個成功提交的資料,但新的 primary 在隨後與 secondary 同步資料,使得該版本的副本個數達到 W,從而使得該版本的資料成為成功提交的資料
例如:在 N=5,W=3,R=3 的系統中,某時刻副本最大版本號為(v2 v2 v1 v1 v1),此時 v1 是系統的最新的成功提交的資料,v2 是一個處於中間狀態的未成功提交的資料。假設此刻原 primary副本異常,中心節點進行 primary 切換工作。這類“中間態”資料究竟作為“髒資料”被刪除,還是作為新的資料被同步後成為生效的資料,完全取決於這個資料能否參與新 primary 的選舉。下面分別分析這兩種情況
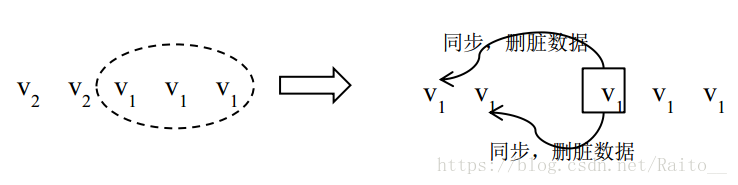
第一種:若中心節點與其中 3 個副本通訊成功,讀取到的版本號為(v1 v1 v1),則任選一個副本作為 primary,新 primary 以 v1 作為最新的成功提交的版本並與其他副本同步,當與第 1、第 2 個副本同步資料時,由於第 1、第 2 個副本版本號大於 primary,屬於髒資料,可以按照 2.2.2.4 節中介紹的處理髒資料的方式解決。實踐中,新 primary 也有可能與後兩個副本完成同步後就提供資料服務,隨後自身版本號也更新到 v2,如果系統不能保證之後的 v2 與之前的 v2 完全一樣,則新primary 在與第 1、2 個副本同步資料時不但要比較資料版本號還需要比較更新操作的具體內容是否一樣
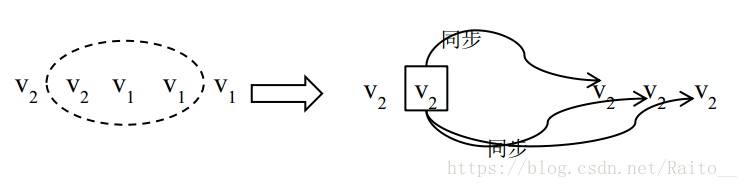
第二種:若中心節點與其他 3 個副本通訊成功,讀取到的版本號為(v2 v1 v1),則選取版本號為v2 的副本作為新的 primary,之後,一旦新 primary 與其他 2 個副本完成資料同步,則符合 v2 的副本個數達到 W 個,成為最新的成功提交的副本,新 primary 可以提供正常的讀寫服務
工程投影
| 分散式系統 | Quorum |
|---|---|
| GFS | GFS 使用 WARO 機制讀寫副本,即如果更新所有副本成功則認為更新成功,一旦更新成功,則可以任意選擇一個副本讀取資料;如果更新某個副本失敗,則更新失敗,副本之間處於不一致的狀態。GFS 系統不保證異常狀態時副本的一致性,GFS 系統需要上層應用通過 Checksum 等機制自行判斷資料是否合法。值得注意的是 GFS 中的 append 操作,一旦 append 操作某個 chunck 的副本上失敗, GFS 系統會自動新增一個 chunck 並嘗試 append 操作,由於可以讓新增的 chunck 在正常的機器上建立,從而解決了由於 WARO 造成的系統可用性下降問題。進而在 GFS 中,append 操作不保證一定在檔案的結尾進行,由於在新增的 chunk 上重試 append,append 的資料可能會出現多份重複的現象,但每個 append 操作會返回使用者最終成功的 offset 位置,在這個位置上,任意讀取某個副本一定可以讀到寫入的資料。這種在新增 chunk 上進行嘗試的思路,大大增大了系統的容錯能力,提高了系統可用性,是一種非常值得借鑑的設計思路 |
| Dynamo | Dynamo/Cassandra 是一種去中心化的分散式儲存系統。 Dynamo 使用 Quorum 機制來管理副本。使用者可以配置 N、R、W 的引數,並保證滿足 R+W>N 的 quorum 要求。與其他系統的 Quorum 機制類似,更新資料時,至少成功更新 W 個副本返回使用者成功,讀取資料時至少返回 R 個副本的資料。然而 Dynamo 是一個沒有 primary 中的去中心化系統,由於缺乏中心控制,每次更新操作都可能由不同的副本主導,在出現併發更新、系統異常時,其副本的一致性完全無法得到保障。下面著重分析 Dynamo 在異常時副本的一致性情況。首先, Dynamo 使用一致性雜湊分佈資料,理論上,即使出現一個節點異常,更新操作也可以順著一致性雜湊環的順序找到 N 個節點完成。不過,這裡我們簡化其模型,認為始終只有初始的 N 個副本,在實際中可以等效為網路異常造成使用者只能和初始的 N 個副本通訊。更復雜的是,雖然可以沿雜湊環找到下一個節點臨時加入,但無法解決異常節點又重新加入的問題,所以這裡的這種簡化模型是完全合理的。我們通過一個例子來考察Dynamo 的一致性。例如:在 Dynamo 系統中,N=3,R=2,W=2,初始時,資料 3 個副本(A、B、C)上的資料一致,這裡假設資料值都為 1,即(1,1,1)。某次更新操作需在原有資料的基礎上增加新資料,這裡假設為+1 操作,該操作由副本 A 主導,副本 A 成功更新自己及副本 C,由於異常,更新副本 B 失敗,由於已經滿足 W=2 的要求,返回使用者更新成功。此時 3 個副本上的資料分別為(2,1,2)。接著,進行新的更新操作,該操作需要在原有資料的基礎上增加新資料,假設為+2 操作,假設使用者端由於異常聯絡副本 A 失敗,聯絡副本 B 成功,本次更新操作由副本 B 主導,副本 B 讀取本地資料 1,完成加 2 操作後同步給其他副本,假設同步副本 C 成功,此時滿足 W=2 的要求,返回使用者更新成功。此時 3 個副本上的資料分別為(2, 3, 3)。這裡需要說明的是在 Dynamo 中,副本 C 必須要接受副本 B 發過來的更新並覆蓋自身資料,即使從全域性角度說該更新與副本 C 上的已有資料是衝突的,但副本 C 自身無法判斷自己的資料是否有效。假如第一次副本 A 主導的更新只在副本 C 上成功,那麼此時副本 C 上的資料本身就是錯誤的髒資料,被副本 B 主導的這次更新覆蓋也是完全應該的。最後,使用者讀取資料,假設成功讀取副本 A 及副本 B 上的資料,滿足 R=2 的需求,使用者將拿到兩個完全不一致的資料 2 與 3,Dynamo 將解決這種不一致的情況留給了使用者進行。為了幫助使用者解決這種不一致的情況,Dynamo 提出了一種 clock vector 的方法,該方法的思路就是記錄資料的版本變化,以類似 MVCC(2.7 )的方式幫助使用者解決資料衝突。所謂 clock vector即記錄了資料變化的路徑的向量,為每個更新操作維護分配一個向量元素,記錄資料的版本號及主導該次更新的副本名字。接著例 2.4.7 來介紹 clock vector 的過程。例如:在 Dynamo 系統中,N=3,R=2,W=2,初始時,資料 3 個副本(A、B、C)上的資料一致,這裡假設資料值都為 1,即(1,1,1),此時三個副本的 clock vector 都為空([], [], [])。某次更新操作需在原有資料的基礎上增加新資料,這裡假設為+1 操作,該操作由副本 A 主導,副本 A 成功更新自己及副本 C,返回使用者更新成功。此時 3 個副本上的資料分別為(2,1,2),而三個副本的 clock vector 為([(1, A)], [], [(1, A)]),A、C 的 clock vector 表示資料版本號為 1,更新是有副本 A 主導的。接著,進行新的更新操作,該操作需要在原有資料的基礎上增加新資料,假設為+2 操作,假設本次更新操作由副本 B 主導,副本 B 讀取本地資料 1,完成加 2 操作後同步給其他副本,假設同步副本 C 成功,。此時 3 個副本上的資料分別為(2, 3, 3),此時三個副本的 clock vector 為([(1, A)], [(1, B)], [(1, B)])。為了說明 clock vector,這裡再加入一次+3 操作,並由副本 A 主導,更新副本 A 及副本 C 成功,此時資料為(5, 3, 5),此時三個副本的 clock vector 為([(2, A), (1, A)], [(1, B)], [(2, A), (1, A)])。最後,使用者讀取資料,假設成功讀取副本 A 及副本 B 上的資料,得到兩個完全不一致的資料 5與 3,及這兩個資料的版本資訊[(2, A), (1, A)], [(1, B)]。使用者可以根據自定義的策略進行合併,例如假設使用者判斷出,其實這些加法操作可以合併,那麼最終的資料應該是 7,又例如使用者可以選擇保留一個數據例如 5 作為自己的資料。由於提供了 clock vector 資訊,不一致的資料其實成為了多版本資料,使用者可以通過自定義策略選擇合併這些多版本資料。Dynamo 建議可以簡單的按照資料更新的時間戳進行合併,即用資料時間戳較新的資料替代較舊的資料。如果是簡單的覆蓋寫操作,例如設定某個使用者屬性,這樣的策略是有效且正確的。然而類似上例中這類併發的加法操作(例如“向購物車中增加商品”),簡單的用新資料替代舊資料的方式就是不正確的,會造成資料丟失 |
| Zookeeper | Zookeeper 使用的 paxos 協議本身就是利用了 Quorum 機制,在後面中有詳細分析,這裡不贅述。當利用 paxos 協議外選出 primary 後,Zookeeper 的更新流量由 primary 節點控制,每次更新操作,primary 節點只需更新超過半數(含自身)的節點後就返回使用者成功。每次更新操作都會遞增各個節點的版本號(xzid)。當 primary 節點異常,利用 paxos 協議選舉新的 primary 時,每個節點都會以自己的版本號發起 paxos 提議,從而保證了選出的新 primary 是某個超過半數副本集合中版本號最大的副本。新 primary 的版本號未必是一個最新已提交的版本,可能是一個只更新了少於半數副本的中間態的更新版本,此時新primary 完成與超過半數的副本同步後,這個版本的資料自動滿足 quorum 的半數要求;另一方面,新 primary 的版本可能是一個最新已提交的版本,但可能會存在其他副本沒有參與選舉但持有一個大於新 primary 的版本號的資料(中間態版本),此時這樣的中間態版本資料將被認為是髒資料,在與新 primary 進行資料同步時被 zookeeper 丟棄 |
| Mola*/Armor* | Mola和 Armor系統中所有的副本管理都是基於 Quorum,即資料在多數副本上更新成功則認為成功。Mola 系統的讀取通常不關注強一致性,而提供最終一致性。對於 Armor*,可以通過讀取副本版本號的方式,按 Quorum 規則判斷最新已提交的版本。由於每次讀資料都需要讀取版本號,降低了系統系統性能,Doris系統在讀取 Armor資料時採用了一種優化思路:由於Doris系統的資料是批量更新,Doris維護了 Armor副本的版本號,並只在每批資料更新完成後再重新整理 Armor副本的版本號,從而大大減少了讀取 Armor*副本版本號的開銷 |
| Big Pipe* | Big Pipe中的副本管理也是採用了 WARO 機制。值得一提的是,Big Pipe 利用了 zookeeper 的高可用性解決了 WARO 在更新失敗時副本的不一致的難題。當更新操作失敗時,每個副本都會嘗試將自己的最後一條更新操作寫入 zookeeper。但最多隻有一個副本能寫入成功,如果副本發現之前已經有副本寫入成功後則放棄寫入,並以 zookeeper 中的記錄為準與自身的資料進行同步。另一方面,與 GFS 更新失敗後新建 chunck 類似,當 Big Pipe更新失敗後,會將更新切換到另一組副本,這組副本首先讀取 zookeeper 上的最後一條記錄,並從這條更新記錄之後繼續提供服務。例如,一共有 3 個副本 A、B、C,某次更新操作在 A、B 上成功,各副本上的資料為(2,2,1),此時 3 個副本一旦探測出異常,都會嘗試向 zookeeper 寫入最後的記錄。如果 A 或 B 寫入成功,則意味著最後一次的更新操作成功,副本 C 會嘗試同步到這條更新,新切換的副本組也會在資料 2的基礎上繼續提供服務。如果 C 寫入成功,則相當於最後一次更新失敗,當副本 A、 B 讀到 zookeeper上的資訊後會將最後一個更新操作作為“髒資料”並回退掉最後一個更新操作,新切換的副本組也只會在資料 1 的基礎上繼續提供服務。從這裡不難看出,當出現更新失敗時,Big Pipe*中這條中間態資料的命運完全取決於是哪個副本搶先完成寫 zookeeper 的過程 |