
一、spark單機安裝
阿新 • • 發佈:2018-11-23
如果要全面的使用spark,你可能要安裝如JDK,scala,hadoop等好些東西。可有時候我們只是為了簡單地安裝和測試來感受一下spark的使用,並不需要那麼全面。對於這樣的需要,我們其實只要安裝好JDK,然後下載配置spark,兩步即可。
本文選擇:
1、centos
2、JDK1.8
3、spark2.3
一、JDK安裝
spark需要執行在Java環境中,所以我們需要安裝JDK。
JDK安裝配置參考:https://www.cnblogs.com/lay2017/p/7442217.html
二、spark安裝
下載
我們到spark官網(http://spark.apache.org/downloads.html

我們新建一個目錄存放spark的下載檔案
mkdirs /usr/local/hadoop/spark
進入該目錄,使用wget命令下載
wget https://archive.apache.org/dist/spark/spark-2.3.0/spark-2.3.0-bin-hadoop2.7.tgz
配置
下載完畢以後我們先解壓
tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz
你會得到一個資料夾
spark-2.3.0-bin-hadoop2.7
我們編輯/etc/profile檔案,新增環境變數

並使之生效
source /etc/profile
我們啟動spark-shell看看是否配置成功
spark-shell
你會進入shell面板
這樣,我們即安裝好了單機spark。如果你使用spark-shell提供的scala做操作的話(也就是不單獨執行scala程式),其實就不需要安裝scala。我們也不需要去整合到獨立的hadoop中,所以也不用安裝hadoop。
三、spark-shell測試
上面的安裝完成以後,你可能希望做一些很簡單的操作,來感受一下spark。在此之前,我們先準備一份txt檔案
我們在:/usr/local/hadoop/spark目錄下建立一個txt檔案,檔案內容如下:
hello java
hello hadoop
hello spark
hello scala
然後我們啟動spark-shell(退出使用":quit"命令)
spark-shell
我們執行以下程式碼
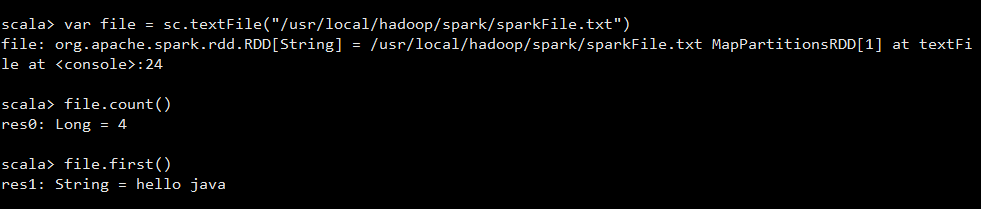
首先我們使用sparkContext的textFile方法載入了我們剛剛建立的txt檔案
然後,統計該檔案的行數,以及我們查找了第一行的資料。