
python D28 粘包
一、兩種粘包:
MTU簡單解釋:
MTU是Maximum Transmission Unit的縮寫。意思是網路上傳送的最大資料包。MTU的單位是位元組。 大部分網路裝置的MTU都是1500個位元組,也就是1500B。
如果本機一次需要傳送的資料比閘道器的MTU大,大的資料包就會被拆開來傳送,這樣會產生很多資料包碎片,增加丟包率,降低網路速度
超出緩衝區大小會報下面的錯誤,或者udp協議的時候,你的一個數據包的大小超過了你一次recv能接受的大小,也會報下面的錯誤,tcp不會,但是超出快取區大小的時候,肯定會報這個錯誤。
subprocess
importsubprocesssubprocess cmd = input('請輸入指令>>>') res = subprocess.Popen( cmd, #字串指令:'dir','ipconfig',等等 shell=True, #使用shell,就相當於使用cmd視窗 stderr=subprocess.PIPE, #標準錯誤輸出,凡是輸入錯誤指令,錯誤指令輸出的報錯資訊就會被它拿到 stdout=subprocess.PIPE, #標準輸出,正確指令的輸出結果被它拿到 ) print(res.stdout.read().decode('gbk')) print(res.stderr.read().decode('gbk'))
注意:
如果是windows,那麼res.stdout.read()讀出的就是GBK編碼的,在接收端需要用GBK解碼
且只能從管道里讀一次結果,PIPE稱為管道。
下面是subprocess和windows上cmd下的指令的對應示意圖:subprocess的stdout.read()和stderr.read(),拿到的結果是bytes型別,所以需要轉換為字串打印出來看。
好,既然我們會使用subprocess了,那麼我們就通過它來模擬一個粘包
tcp粘包演示(一):
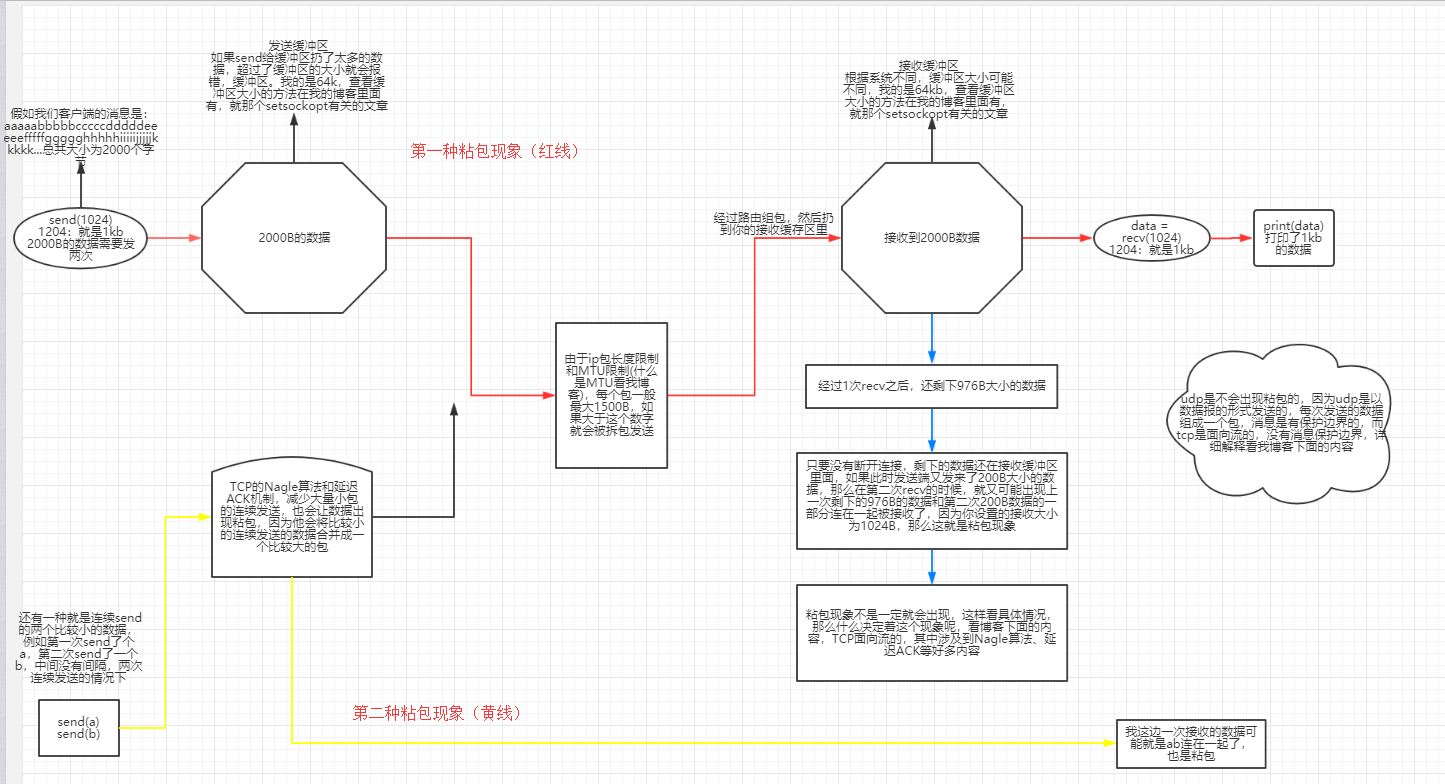
先從上面粘包現象中的第一種開始:接收方沒有及時接收緩衝區的包,造成多個包接收(客戶端傳送了一段資料,服務端只收了一小部分,
服務端下次再收的時候還是從緩衝區拿上次遺留的資料,產生粘包)
server端程式碼示例
Server端
client端程式碼示例
import socket ip_port = ('127.0.0.1',8080) size = 1024 tcp_sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) res = tcp_sk.connect(ip_port) while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break tcp_sk.send(msg.encode('utf-8')) act_res=tcp_sk.recv(size) print('接收的返回結果長度為>',len(act_res)) print('std>>>',act_res.decode('gbk')) #windows返回的內容需要用gbk來解碼,因為windows系統的預設編碼為gbktcp_client端
tcp粘包演示(二):傳送端需要等緩衝區滿才傳送出去,造成粘包(傳送資料時間間隔很短,資料也很小,會合到一起,產生粘包)
server端
from socket import * ip_port=('127.0.0.1',8080) tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(5) conn,addr=tcp_socket_server.accept() data1=conn.recv(10) data2=conn.recv(10) print('----->',data1.decode('utf-8')) print('----->',data2.decode('utf-8')) conn.close()tcp_server
client端
import socket BUFSIZE=1024 ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) # res=s.connect_ex(ip_port) res=s.connect(ip_port) s.send('hi'.encode('utf-8')) s.send('meinv'.encode('utf-8'))tcp_client
udp:是面向包的,且包和包之間存在包邊界保護所以不會產生粘包。
在udp的程式碼中,我們在server端接收返回訊息的時候,我們設定的recvfrom(1024),那麼當我輸入的執行指令為‘dir’的時候,dir在我當前資料夾下輸出的內容大於1024,
然後就報錯了,報的錯誤也是下面這個:
解釋原因:是因為udp是面向報文的,意思就是每個訊息是一個包,你接收端設定接收大小的時候,必須要比你發的這個包要大,不然一次接收不了就會報這個錯誤,
而tcp不會報錯,這也是為什麼ucp會丟包的原因之一,這個和我們上面緩衝區那個錯誤的報錯原因是不一樣的。
粘包原因
傳送端可以是一K一K地傳送資料,而接收端的應用程式可以兩K兩K地提走資料,當然也有可能一次提走3K或6K資料,或者一次只提走幾個位元組的資料,也就是說,應用程式所看到的資料是一個整體,或說是一個流(stream),一條訊息有多少位元組對應用程式是不可見的,因此TCP協議是面向流的協議,這也是容易出現粘包問題的原因。而UDP是面向訊息的協議,每個UDP段都是一條訊息,應用程式必須以訊息為單位提取資料,不能一次提取任意位元組的資料,這一點和TCP是很不同的。怎樣定義訊息呢?可以認為對方一次性write/send的資料為一個訊息,需要明白的是當對方send一條資訊的時候,無論底層怎樣分段分片,TCP協議層會把構成整條訊息的資料段排序完成後才呈現在核心緩衝區。 例如基於tcp的套接字客戶端往服務端上傳檔案,傳送時檔案內容是按照一段一段的位元組流傳送的,在接收方看了,根本不知道該檔案的位元組流從何處開始,在何處結束 所謂粘包問題主要還是因為接收方不知道訊息之間的界限,不知道一次性提取多少位元組的資料所造成的。 此外,傳送方引起的粘包是由TCP協議本身造成的,TCP為提高傳輸效率,傳送方往往要收集到足夠多的資料後才傳送一個TCP段。若連續幾次需要send的資料都很少,通常TCP會根據優化演算法把這些資料合成一個TCP段後一次傳送出去,這樣接收方就收到了粘包資料。 1.TCP(transport control protocol,傳輸控制協議)是面向連線的,面向流的,提供高可靠性服務。收發兩端(客戶端和伺服器端)都要有一一成對的socket,因此,傳送端為了將多個發往接收端的包,更有效的發到對方,使用了優化方法(Nagle演算法),將多次間隔較小且資料量小的資料,合併成一個大的資料塊,然後進行封包。這樣,接收端,就難於分辨出來了,必須提供科學的拆包機制。 即面向流的通訊是無訊息保護邊界的。 2.UDP(user datagram protocol,使用者資料報協議)是無連線的,面向訊息的,提供高效率服務。不會使用塊的合併優化演算法,, 由於UDP支援的是一對多的模式,所以接收端的skbuff(套接字緩衝區)採用了鏈式結構來記錄每一個到達的UDP包,在每個UDP包中就有了訊息頭(訊息來源地址,埠等資訊),這樣,對於接收端來說,就容易進行區分處理了。 即面向訊息的通訊是有訊息保護邊界的。 3.tcp是基於資料流的,於是收發的訊息不能為空,這就需要在客戶端和服務端都新增空訊息的處理機制,防止程式卡住,而udp是基於資料報的,即便是你輸入的是空內容(直接回車),那也不是空訊息,udp協議會幫你封裝上訊息頭,實驗略 udp的recvfrom是阻塞的,一個recvfrom(x)必須對唯一一個sendinto(y),收完了x個位元組的資料就算完成,若是y>x資料就丟失,這意味著udp根本不會粘包,但是會丟資料,不可靠 tcp的協議資料不會丟,沒有收完包,下次接收,會繼續上次繼續接收,己端總是在收到ack時才會清除緩衝區內容。資料是可靠的,但是會粘包。粘包機制
tcp和udpb比較
補充問題一:為何tcp是可靠傳輸,udp是不可靠傳輸 tcp在資料傳輸時,傳送端先把資料傳送到自己的快取中,然後協議控制將快取中的資料發往對端,對端返回一個ack=1,傳送端則清理快取中的資料,對端返回ack=0,則重新發送資料,所以tcp是可靠的。 而udp傳送資料,對端是不會返回確認資訊的,因此不可靠 補充問題二:send(位元組流)和sendall send的位元組流是先放入己端快取,然後由協議控制將快取內容發往對端,如果待發送的位元組流大小大於快取剩餘空間,那麼資料丟失,用sendall就會迴圈呼叫send,資料不會丟失,一般的小資料就用send,因為小資料也用sendall的話有些影響程式碼效能,簡單來講就是還多while迴圈這個程式碼呢。 用UDP協議傳送時,用sendto函式最大能傳送資料的長度為:65535- IP頭(20) – UDP頭(8)=65507位元組。用sendto函式傳送資料時,如果傳送資料長度大於該值,則函式會返回錯誤。(丟棄這個包,不進行傳送) 用TCP協議傳送時,由於TCP是資料流協議,因此不存在包大小的限制(暫不考慮緩衝區的大小),這是指在用send函式時,資料長度引數不受限制。而實際上,所指定的這段資料並不一定會一次性發送出去,如果這段資料比較長,會被分段傳送,如果比較短,可能會等待和下一次資料一起傳送。tcp_udp比較
粘包的原因:主要還是因為接收方不知道訊息之間的界限,不知道一次性提取多少位元組的資料所造成的
二、粘包現象的解決解決方案(一): 問題的根源在於,接收端不知道傳送端將要傳送的位元組流的長度,所以解決粘包的方法就是圍繞,如何讓傳送端在傳送資料前,把自己將要傳送的位元組流總大小讓接收端知曉,然後接收端發一個確認訊息給傳送端,然後傳送端再發送過來後面的真實內容,接收端再來一個死迴圈接收完所有資料。

看程式碼示例:
server端程式碼
複製程式碼 import socket,subprocess ip_port=('127.0.0.1',8080) s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) s.bind(ip_port) s.listen(5) while True: conn,addr=s.accept() print('客戶端',addr) while True: msg=conn.recv(1024) if not msg:break res=subprocess.Popen(msg.decode('utf-8'),shell=True,\ stdin=subprocess.PIPE,\ stderr=subprocess.PIPE,\ stdout=subprocess.PIPE) err=res.stderr.read() if err: ret=err else: ret=res.stdout.read() data_length=len(ret) conn.send(str(data_length).encode('utf-8')) data=conn.recv(1024).decode('utf-8') if data == 'recv_ready': conn.sendall(ret) conn.close()tcp_server端
client端程式碼示例
import socket,time s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) length=int(s.recv(1024).decode('utf-8')) s.send('recv_ready'.encode('utf-8')) send_size=0 recv_size=0 data=b'' while recv_size < length: data+=s.recv(1024) recv_size+=len(data) print(data.decode('utf-8'))tcp_client
解決方案(二):
通過struck模組將需要傳送的內容的長度進行打包,打包成一個4位元組長度的資料傳送到對端,對端只要取出前4個位元組,然後對這四個位元組的資料進行解包,拿到你要傳送的內容的長度,然後通過這個長度來繼續接收我們實際要傳送的內容。
關於struck的介紹:瞭解c語言的人,一定會知道struct結構體在c語言中的作用,不瞭解C語言的同學也沒關係,不影響,其實它就是定義了一種結構,裡面包含不同型別的資料(int,char,bool等等),方便對某一結構物件進行處理。而在網路通訊當中,大多傳遞的資料是以二進位制流(binary data)存在的。當傳遞字串時,不必擔心太多的問題,而當傳遞諸如int、char之類的基本資料的時候,就需要有一種機制將某些特定的結構體型別打包成二進位制流的字串然後再網路傳輸,而接收端也應該可以通過某種機制進行解包還原出原始的結構體資料。python中的struct模組就提供了這樣的機制,該模組的主要作用就是對python基本型別值與用python字串格式表示的C struct型別間的轉化(This module performs conversions between Python values and C structs represented as Python strings.)。
struck模組的使用:struct模組中最重要的兩個函式是pack()打包, unpack()解包。

pack():#我在這裡只介紹一下'i'這個int型別,上面的圖中列舉除了可以打包的所有的資料型別,並且struck除了pack和uppack兩個方法之外還有好多別的方法和用法,大家以後找時間可以去研究一下,這裡我就不做介紹啦,網上的教程很多
import struct
a=12
# 將a變為二進位制
bytes=struct.pack('i',a)
pack方法圖解:

unpack():
# 注意,unpack返回的是tuple !!
a,=struct.unpack('i',bytes)
struck解決粘包問題
先看一段虛擬碼:
import json,struct #假設通過客戶端上傳1T:1073741824000的檔案a.txt #為避免粘包,必須自定製報頭 header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1T資料,檔案路徑和md5值 #為了該報頭能傳送,需要序列化並且轉為bytes,因為bytes只能將字串型別的資料轉換為bytes型別的,所有需要先序列化一下這個字典,字典不能直接轉化為bytes head_bytes=bytes(json.dumps(header),encoding='utf-8') #序列化並轉成bytes,用於傳輸 #為了讓客戶端知道報頭的長度,用struck將報頭長度這個數字轉成固定長度:4個位元組 head_len_bytes=struct.pack('i',len(head_bytes)) #這4個位元組裡只包含了一個數字,該數字是報頭的長度 #客戶端開始傳送 conn.send(head_len_bytes) #先發報頭的長度,4個bytes conn.send(head_bytes) #再發報頭的位元組格式 conn.sendall(檔案內容) #然後發真實內容的位元組格式 #服務端開始接收 head_len_bytes=s.recv(4) #先收報頭4個bytes,得到報頭長度的位元組格式 x=struct.unpack('i',head_len_bytes)[0] #提取報頭的長度 head_bytes=s.recv(x) #按照報頭長度x,收取報頭的bytes格式 header=json.loads(json.dumps(header)) #提取報頭 #最後根據報頭的內容提取真實的資料,比如 real_data_len=s.recv(header['file_size']) s.recv(real_data_len)虛擬碼
正式程式碼
server端程式碼示例:報頭:就是訊息的頭部資訊,我們要傳送的真實內容為報頭後面的內容。
import socket,struct,json import subprocess phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) #忘了這是幹什麼的了吧,地址重用?想起來了嗎~ phone.bind(('127.0.0.1',8080)) phone.listen(5) while True: conn,addr=phone.accept() while True: cmd=conn.recv(1024) if not cmd:break print('cmd: %s' %cmd) res=subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) err=res.stderr.read() if err: back_msg=err else: back_msg=res.stdout.read() conn.send(struct.pack('i',len(back_msg))) #先發back_msg的長度 conn.sendall(back_msg) #在發真實的內容 #其實就是連續的將長度和內容一起發出去,那麼整個內容的前4個位元組就是我們打包的後面內容的長度,對吧 conn.close()server端
client端
import socket,time,struct s=socket.socket(socket.AF_INET,socket.SOCK_STREAM) res=s.connect_ex(('127.0.0.1',8080)) while True: msg=input('>>: ').strip() if len(msg) == 0:continue if msg == 'quit':break s.send(msg.encode('utf-8')) #傳送給一個指令 l=s.recv(4) #先接收4個位元組的資料,因為我們將要傳送過來的內容打包成了4個位元組,所以先取出4個位元組 x=struct.unpack('i',l)[0] #解包,是一個元祖,第一個元素就是我們的內容的長度 print(type(x),x) # print(struct.unpack('I',l)) r_s=0 data=b'' while r_s < x: #根據內容的長度來繼續接收4個位元組後面的內容。 r_d=s.recv(1024) data+=r_d r_s+=len(r_d) # print(data.decode('utf-8')) print(data.decode('gbk')) #windows預設gbk編碼自定製報頭
精進程式碼示例:
server端
import socket,struct,json import subprocess phone=socket.socket(socket.AF_INET,socket.SOCK_STREAM) phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1) phone.bind(('127.0.0.1',8080)) phone.listen(5) while True: conn,addr=phone.accept() while True: cmd=conn.recv(1024) if not cmd:break print('cmd: %s' %cmd) res=subprocess.Popen(cmd.decode('utf-8'), shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) err=res.stderr.read() print(err) if err: back_msg=err else: back_msg=res.stdout.read() headers={'data_size':len(back_msg)} head_json=json.dumps(headers) head_json_bytes=bytes(head_json,encoding='utf-8') conn.send(struct.pack('i',len(head_json_bytes))) #先發報頭的長度 conn.send(head_json_bytes) #再發報頭 conn.sendall(back_msg) #在發真實的內容 conn.close()server端
client端:
from socket import * import struct,json ip_port=('127.0.0.1',8080) client=socket(AF_INET,SOCK_STREAM) client.connect(ip_port) while True: cmd=input('>>: ') if not cmd:continue client.send(bytes(cmd,encoding='utf-8')) head=client.recv(4) head_json_len=struct.unpack('i',head)[0] head_json=json.loads(client.recv(head_json_len).decode('utf-8')) data_len=head_json['data_size'] recv_size=0 recv_data=b'' while recv_size < data_len: recv_data+=client.recv(1024) recv_size+=len(recv_data) #print(recv_data.decode('utf-8')) print(recv_data.decode('gbk')) #windows預設gbk編碼client端
整個流程的大致解釋:
我們可以把報頭做成字典,字典裡包含將要傳送的真實資料的描述資訊(大小啊之類的),然後json序列化,然後用struck將序列化後的資料長度打包成4個位元組。 我們在網路上傳輸的所有資料 都叫做資料包,資料包裡的所有資料都叫做報文,報文裡面不止有你的資料,還有ip地址、mac地址、埠號等等,其實所有的報文都有報頭,這個報頭是協議規定的,看一下
傳送時: 先發報頭長度 再編碼報頭內容然後傳送 最後發真實內容 接收時: 先手報頭長度,用struct取出來 根據取出的長度收取報頭內容,然後解碼,反序列化 從反序列化的結果中取出待取資料的描述資訊,然後去取真實的資料內容
FTB上傳下載檔案的程式碼(簡易版)
import socket import struct import json sk = socket.socket() # buffer = 4096 # 當雙方的這個接收發送的大小比較大的時候,就像這個4096,就會丟資料,這個等我查一下再告訴大家,改小了就ok的,在linux上也是ok的。 buffer = 1024 #每次接收資料的大小 sk.bind(('127.0.0.1',8090)) sk.listen() conn,addr = sk.accept() #接收 head_len = conn.recv(4) head_len = struct.unpack('i',head_len)[0] #解包 json_head = conn.recv(head_len).decode('utf-8') #反序列化 head = json.loads(json_head) filesize = head['filesize'] with open(head['filename'],'wb') as f: while filesize: if filesize >= buffer: #>=是因為如果剛好等於的情況出現也是可以的。 content = conn.recv(buffer) f.write(content) filesize -= buffer else: content = conn.recv(buffer) f.write(content) break conn.close() sk.close()tpc_server_ftb
import os import json import socket import struct sk = socket.socket() sk.connect(('127.0.0.1',8090)) buffer = 1024 #讀取檔案的時候,每次讀取的大小 head = { 'filepath':r'D:\打包程式', #需要下載的檔案路徑,也就是檔案所在的資料夾 'filename':'xxx.mp4', #改成上面filepath下的一個檔案 'filesize':None, } file_path = os.path.join(head['filepath'],head['filename']) filesize = os.path.getsize(file_path) head['filesize'] = filesize # json_head = json.dumps(head,ensure_ascii=False) #字典轉換成字串 json_head = json.dumps(head) #字典轉換成字串 bytes_head = json_head.encode('utf-8') #字串轉換成bytes型別 print(json_head) print(bytes_head) #計算head的長度,因為接收端先接收我們自己定製的報頭,對吧 head_len = len(bytes_head) #報頭長度 pack_len = struct.pack('i',head_len) print(head_len) print(pack_len) sk.send(pack_len) #先發送報頭長度 sk.send(bytes_head) #再發送bytes型別的報頭 #即便是視訊檔案,也是可以按行來讀取的,也可以readline,也可以for迴圈,但是讀取出來的資料大小就不固定了,影響效率,有可能讀的比較小,也可能很大,像視訊檔案一般都是一行的二進位制位元組流。 #所有我們可以用read,設定一個一次讀取內容的大小,一邊讀一邊發,一邊收一邊寫 with open(file_path,'rb') as f: while filesize: if filesize >= buffer: #>=是因為如果剛好等於的情況出現也是可以的。 content = f.read(buffer) #每次讀取出來的內容 sk.send(content) filesize -= buffer #每次減去讀取的大小 else: #那麼說明剩餘的不夠一次讀取的大小了,那麼只要把剩下的讀取出來傳送過去就行了 content = f.read(filesize) sk.send(content) break sk.close()tpc_client_ftb
三、驗證客戶端的連結合法性
首先,我們來探討一下,什麼叫驗證合法性, 舉個例子:有一天,我開了一個socket服務端,只想讓咱們這個班的同學使用,但是有一天,隔壁班的同學過來問了一下我開的這個服務端的ip和埠,然後他是不是就可以去連線我了啊,那怎麼辦,我是不是不想讓他連線我啊,我需要驗證一下你的身份,這就是驗證連線的合法性,再舉個例子,就像我們上面說的你的windows系統是不是連線微軟的時間伺服器來獲取時間的啊,你的mac能到人家微軟去獲取時間嗎,你願意,人家微軟還不願意呢,對吧,那這時候,你每次連線我來獲取時間的時候,我是不是就要驗證你的身份啊,也就是你要帶著你的系統資訊,我要判斷你是不是我微軟的windows,對吧,如果是mac,我是不是不讓你連啊,這就是連接合法性。如果驗證你的連線是合法的,那麼如果我還要對你的身份進行驗證的需求,也就是要驗證使用者名稱和密碼,那麼我們還需要進行身份認證。連線認證>>身份認證>>ok你可以玩了。
如果你想在分散式系統中實現一個簡單的客戶端連結認證功能,又不像SSL那麼複雜,那麼利用hmac+加鹽的方式來實現,直接看程式碼!(SSL,我們都)
from socket import * import hmac,os secret_key=b'Jedan has a big key!' def conn_auth(conn): ''' 認證客戶端連結 :param conn: :return: ''' print('開始驗證新連結的合法性') msg=os.urandom(32)#生成一個32位元組的隨機字串 conn.sendall(msg) h=hmac.new(secret_key,msg) digest=h.digest() respone=conn.recv(len(digest)) return hmac.compare_digest(respone,digest) def data_handler(conn,bufsize=1024): if not conn_auth(conn): print('該連結不合法,關閉') conn.close() return print('連結合法,開始通訊') while True: data=conn.recv(bufsize) if not data:break conn.sendall(data.upper()) def server_handler(ip_port,bufsize,backlog=5): ''' 只處理連結 :param ip_port: :return: ''' tcp_socket_server=socket(AF_INET,SOCK_STREAM) tcp_socket_server.bind(ip_port) tcp_socket_server.listen(backlog) while True: conn,addr=tcp_socket_server.accept() print('新連線[%s:%s]' %(addr[0],addr[1])) data_handler(conn,bufsize) if __name__ == '__main__': ip_port=('127.0.0.1',9999) bufsize=1024 server_handler(ip_port,bufsize)服務端
from socket import * import hmac,os secret_key=b'Jedan has a big key!' def conn_auth(conn): ''' 驗證客戶端到伺服器的連結 :param conn: :return: ''' msg=conn.recv(32) h=hmac.new(secret_key,msg) digest=h.digest() conn.sendall(digest) def client_handler(ip_port,bufsize=1024): tcp_socket_client=socket(AF_INET,SOCK_STREAM) tcp_socket_client.connect(ip_port) conn_auth(tcp_socket_client) while True: data=input('>>: ').strip() if not data:continue if data == 'quit':break tcp_socket_client.sendall(data.encode('utf-8')) respone=tcp_socket_client.recv(bufsize) print(respone.decode('utf-8')) tcp_socket_client.close() if __name__ == '__main__': ip_port=('127.0.0.1',9999) bufsize=1024 client_handler(ip_port,bufsize)客戶端
介紹程式碼中使用的兩個方法:
1、os.urandom(n) 其中os.urandom(n) 是一種bytes型別的隨機生成n個位元組字串的方法,而且每次生成的值都不相同。再加上md5等加密的處理,就能夠成內容不同長度相同的字串了。

os.urandom(n)函式在python官方文件中做出了這樣的解釋 函式定位: Return a string of n random bytes suitable for cryptographic use. 意思就是,返回一個有n個byte那麼長的一個string,然後很適合用於加密。 然後這個函式,在文件中,被歸結於os這個庫的Miscellaneous Functions,意思是不同種類的函式(也可以說是混種函式) 原因是: This function returns random bytes from an OS-specific randomness source. (函式返回的隨機位元組是根據不同的作業系統特定的隨機函式資源。即,這個函式是呼叫OS內部自帶的隨機函式的。有特異性)
使用方法:
import os
from hashlib import md5
for i in range(10):
print md5(os.urandom(24)).hexdigest()
2、hmac: 我們完全可以用hashlib來實現,但是學個新的嗎,沒什麼不好的,這個操作更方便一些。
Python自帶的hmac模組實現了標準的Hmac演算法,我們首先需要準備待計算的原始訊息message,隨機key,雜湊演算法,這裡採用MD5,使用hmac的程式碼如下:
import hmac message = b'Hello world' key = b'secret' h = hmac.new(key,message,digestmod='MD5') print(h.hexdigest())
比較兩個密文是否相同,可以用hmac.compare_digest(密文、密文),然會True或者False。
可見使用hmac和普通hash演算法非常類似。hmac輸出的長度和原始雜湊演算法的長度一致。需要注意傳入的key和message都是bytes型別,str型別需要首先編碼為bytes。
def hmac_md5(key, s):
return hmac.new(key.encode('utf-8'), s.encode('utf-8'), 'MD5').hexdigest()
class User(object):
def __init__(self, username, password):
self.username = username
self.key = ''.join([chr(random.randint(48, 122)) for i in range(20)])
self.password = hmac_md5(self.key, password)
OVER