
【lucence入門系列】初探lucence
什麼是lucence
Lucene是apache軟體基金會發布的一個開放原始碼的全文檢索引擎工具包,由資深全文檢索專家Doug Cutting所撰寫,它是一個全文檢索引擎的架構,提供了完整的建立索引和查詢索引,以及部分文字分析的引擎,Lucene的目的是為軟體開發人員提供一個簡單易用的工具包,以方便在目標系統中實現全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎,Lucene在全文檢索領域是一個經典的祖先,現在很多檢索引擎都是在其基礎上建立的,思想是相通的。Lucene是根據關健字來搜尋的文字搜尋工具,只能在某個網站內部搜尋文字內容,不能跨網站搜尋。
索引和搜素
索引是現代搜尋引擎的核心,建立索引的過程就是把源資料處理成非常方便查詢的索引檔案的過程。為什麼索引這麼重要呢,試想你現在要在大量的文件中搜索含有某個關鍵詞的文件,那麼如果不建立索引的話你就需要把這些文件順序的讀入記憶體,然後檢查這個文章中是不是含有要查詢的關鍵詞,這樣的話就會耗費非常多的時間,想想搜尋引擎可是在毫秒級的時間內查找出要搜尋的結果的。這就是由於建立了索引的原因,你可以把索引想象成這樣一種資料結構,他能夠使你快速的隨機訪問儲存在索引中的關鍵詞,進而找到該關鍵詞所關聯的文件。Lucene 採用的是一種稱為反向索引(inverted index)的機制。反向索引就是說我們維護了一個詞 / 短語表,對於這個表中的每個詞 / 短語,都有一個連結串列描述了有哪些文件包含了這個詞 / 短語。這樣在使用者輸入查詢條件的時候,就能非常快的得到搜尋結果。
全文檢索
將非結構化資料中的一部分資訊提取出來,重新組織,使其變得有一定結構,然後對此有一定結構的資料進行搜尋,從而達到搜尋相對較快的目的。這部分從非結構化資料中提取出的然後重新組織的資訊,我們稱之索引。例如:字典。字典的拼音表和部首檢字表就相當於字典的索引,對每一個字的解釋是非結構化的,如果字典沒有音節表和部首檢字表,在茫茫辭海中找一個字只能順序掃描。然而字的某些資訊可以提取出來進行結構化處理,比如讀音,就比較結構化,分聲母和韻母,分別只有幾種可以一一列舉,於是將讀音拿出來按一定的順序排列,每一項讀音都指向此字的詳細解釋的頁數。我們搜尋時按結構化的拼音搜到讀音,然後按其指向的頁數,便可找到我們的非結構化資料——也即對字的解釋。
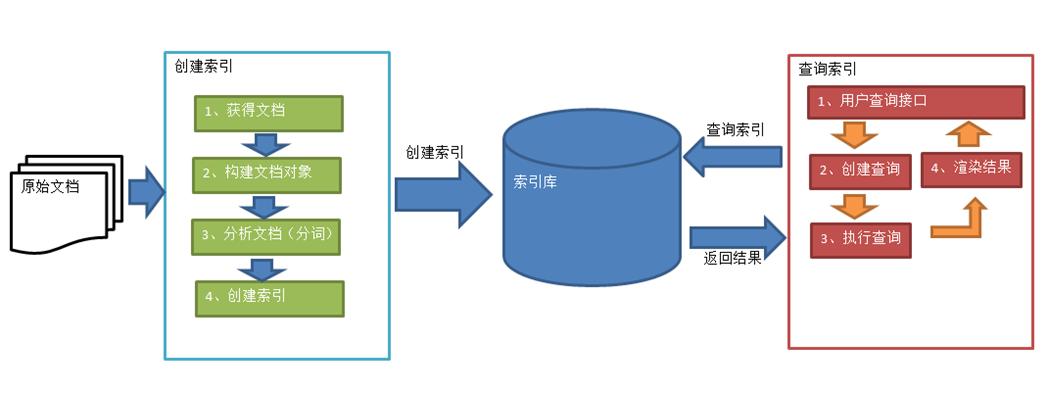
Luncene使用流程
建立索引庫
1、建立JavaBean物件
2、建立Docment物件
3、將JavaBean物件所有的屬性值,均放到Document物件
4、建立IndexWriter物件
4、將Document物件通過IndexWriter物件寫入索引庫
5、關閉IndexWriter物件
查詢索引庫中的內容
1、建立IndexSearcher物件
2、建立QueryParser物件
3、建立Query物件來封裝關鍵字
4、 用IndexSearcher物件去索引庫中查詢符合條件的前100條記錄,不足100條記錄的以實際為準
5、獲取符合條件的編號
6、用indexSearcher物件去索引庫中查詢編號對應的Document物件,將Document物件中的所有屬性取出,再封裝回JavaBean物件中去,並加入到集合中儲存
Lucene 軟體包分析
Package: org.apache.lucene.document
這個包提供了一些為封裝要索引的文件所需要的類,比如 Document, Field。這樣,每一個文件最終被封裝成了一個 Document 物件。
Package: org.apache.lucene.analysis
這個包主要功能是對文件進行分詞,因為文件在建立索引之前必須要進行分詞,所以這個包的作用可以看成是為建立索引做準備工作。
Package: org.apache.lucene.index
這個包提供了一些類來協助建立索引以及對建立好的索引進行更新。這裡面有兩個基礎的類:IndexWriter 和 IndexReader,其中 IndexWriter 是用來建立索引並新增文件到索引中的,IndexReader 是用來刪除索引中的文件的。
Package: org.apache.lucene.search
這個包提供了對在建立好的索引上進行搜尋所需要的類。比如 IndexSearcher 和 Hits, IndexSearcher 定義了在指定的索引上進行搜尋的方法,Hits 用來儲存搜尋得到的結果
快速入門
建立專案,匯入相關jar包
public class Article { //編號 private Integer id; //標題 private String title; //內容 private String content; public Article(){} public Article(Integer id, String title, String content) { this.id = id; this.title = title; this.content = content; } public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getContent() { return content; } public void setContent(String content) { this.content = content; } @Override public String toString() { return "編號:" + id+"\n標題:" + title + "\n內容:" + content; } }
public class FirstApp { /** * 建立索引庫 * 將Aritcle物件放入索引庫中的原始記錄表中,從而形成詞彙表 */ @Test public void createIndexDB() throws Exception{ // 建立Article物件 Article article = new Article(1,"培訓","傳智是一家IT培訓機構"); // 建立Document物件 Document document = new Document(); // 將Article物件中的三個屬性值分別繫結到Document物件 /* *引數一:document物件中的屬性名 *引數二:document物件中的屬性值 *引數三:是否將屬性值存入由原始記錄表中轉存入詞彙表 * Store.YES表示該屬性值會存入詞彙表 * Store.NO表示該屬性值不會存入詞彙表 *引數四:是否將屬性值進行分詞演算法 * Index.ANALYZED表示該屬性值會進行詞彙拆分 * Index.NOT_ANALYZED表示該屬性值不會進行詞彙拆分 */ document.add(new Field("xid",article.getId().toString(), Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("xtitle",article.getTitle(), Field.Store.YES, Field.Index.ANALYZED)); document.add(new Field("xcontent",article.getContent(), Field.Store.YES, Field.Index.ANALYZED)); // 建立IndexWriter字元流物件 /* * 引數一:lucene索引庫最終應對於硬碟中的目錄,例如:E:/IndexDBDBDB * 引數二:採用什麼策略將文字拆分,一個策略就是一個具體的實現類 * 引數三:最多將文字拆分出多少詞彙,LIMITED表示1W個,即只取前1W個詞彙,如果不足1W個詞彙個,以實際為準 */ Directory directory = FSDirectory.open(new File("E:/IndexDBDBDB")); Version version = Version.LUCENE_30; Analyzer analyzer = new StandardAnalyzer(version); IndexWriter.MaxFieldLength maxFieldLength = IndexWriter.MaxFieldLength.LIMITED; IndexWriter indexWriter = new IndexWriter(directory,analyzer,maxFieldLength); // 將document物件寫入lucene索引庫 indexWriter.addDocument(document); // 關閉IndexWriter字元流物件 indexWriter.close(); } /** * 根據關鍵字從索引庫中搜索符合條件的內容 */ @Test public void findIndexDB() throws Exception{ String keywords = "培"; List<Article> articleList = new ArrayList<>(); Directory directory = FSDirectory.open(new File("E:/IndexDBDBDB")); Version version = Version.LUCENE_30; Analyzer analyzer = new StandardAnalyzer(version); // 建立IndexSearcher字元流物件 IndexSearcher indexSearcher = new IndexSearcher(directory); // 建立查詢解析器物件 /* * 引數一:使用分詞器的版本,提倡使用該jar包中的最高版本 * 引數二:對document物件中的哪個屬性進行搜尋 */ QueryParser queryParser = new QueryParser(version,"xcontent",analyzer); // 建立物件,封裝查詢關鍵字 Query query = queryParser.parse(keywords); // 根據關鍵字,去索引庫中的詞彙表搜尋 /* * 引數一:表示封裝關鍵字查詢物件,QueryParser表示查詢解析器 * 引數二:MAX_RECORD表示如果根據關鍵字搜尋出來的內容較多,只取前MAX_RECORD個內容 * 不足MAX_RECORD個數的話,以實際為準 */ int MAX_RECORD = 100; TopDocs topDocs = indexSearcher.search(query,MAX_RECORD); // 迭代詞彙表中符合條件的編號 for(int i=0;i<topDocs.scoreDocs.length;i++){ // 取出封裝編號和分數的ScoreDoc物件 ScoreDoc scoreDoc = topDocs.scoreDocs[i]; // 取出每一個編號,例如:0,1,2 int no = scoreDoc.doc; // 根據編號去索引庫中的原始記錄表中查詢對應的document物件 Document document = indexSearcher.doc(no); // 獲取document物件中的三個屬性值 String xid = document.get("xid"); String xtitle = document.get("xtitle"); String xcontent = document.get("xcontent"); // 封裝到artilce物件中 Article article = new Article(Integer.parseInt(xid),xtitle,xcontent); // 將article物件加入到list集合中 articleList.add(article); } // 迭代結果集 for(Article a:articleList){ System.out.println(a); } } }