
Spark入門詳解(一)-Spark簡介
簡介
Spark是基於記憶體計算的大資料分散式計算框架。Spark基於記憶體計算,提供可互動查詢方式,提供近實時處理方式,同時保證了高容錯性和高可伸縮性,允許使用者將Spark部署在大量廉價硬體之上,形成叢集。
Spark使用Scala語言進行實現,它是一種面向物件、函數語言程式設計語言,能夠像操作本地集合物件一樣輕鬆地操作分散式資料集(Scala提供一個稱為Actor的並行模型,其中Actor通過它的收件箱來發送和接收非同步資訊而不是共享資料,該方式被稱為:Shared Nothing模型)。
特點
-
執行速度快
資料從記憶體中讀取,理論上速度可以高達HadoopMapReduce的100多倍。 -
適用性強
- 支援3種語⾔言的API:scala、java、python,特別是Scala是一種高效、可拓展的語言,能夠用簡潔的程式碼處理較為複雜的處理工作。
- 能夠讀取HDFS、Cassandra和HBase等離線資料。
- 能夠讀取Kafka、Flume和Kinesis等實時資料。
- 能夠以Mesos、YARN或Standalone作為資源管理器排程JOB,進行叢集資源的合理分配和容錯,來完成Spark應用程式的計算。
-
通用性強
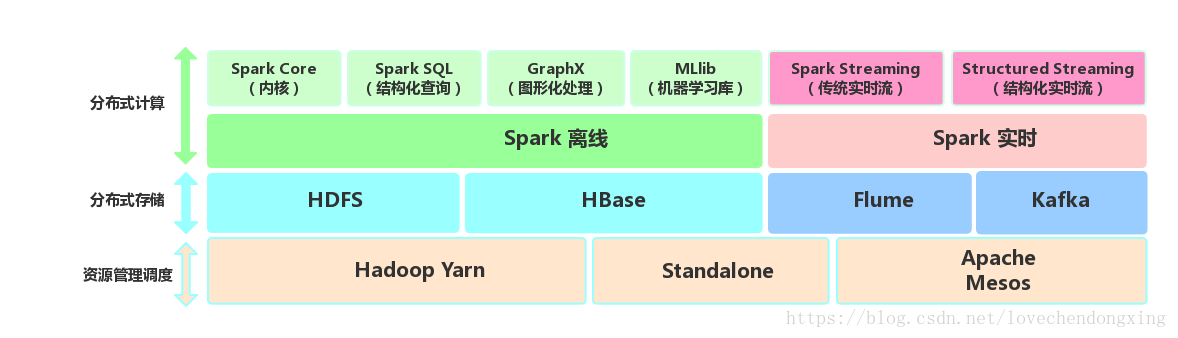
Spark生態圈即BDAS(伯克利資料分析棧)包含了Spark Core、Spark SQL、MLLib、GraphX、Spark Streaming和Structured Streaming等元件,提供離線計算、實時計算、圖形化處理和機器學習等能力,能夠無縫的整合並提供一站式解決方案。
-
Spark Core:包含Spark的基本功能。尤其是定義RDD的API、操作以及這兩者上的動作。其他Spark的庫都是構建在RDD和Spark Core之上的。
-
Spark SQL:提供Hive查詢語言(HiveQL)以及SQL查詢語言(如Mysql)與Spark進行互動的API。每個資料庫表被當做一個RDD,Spark SQL查詢被轉換為Spark Core操作。
-
Spark Streaming:對實時資料流進行處理和控制。Spark Streaming允許程式能夠像普通RDD一樣處理實時資料。
-
Structured Streaming:以結構化的方式操作流式資料,能夠像使用Spark SQL處理批處理一樣,處理流資料。基於Event-Time,相比於SparkStreaming的Receive-Time更精確。
-
GraphX:控制圖、並行圖操作和計算的一組演算法和工具的集合。GraphX擴充套件了RDD API,包含控制圖、建立子圖、訪問路徑上所有頂點的操作。
-
MLlib:一個常用機器學習演算法庫,演算法被實現為對RDD的Spark操作。這個庫包含可擴充套件的學習演算法,比如分類、迴歸等需要對大量資料集進行迭代的操作。
-
Spark和Hadoop的區別
-
Hadoop有兩個核心模組,分散式儲存模組HDFS和分散式計算模組MapReduce。
-
Spark本身並沒有提供分散式儲存能力,因此Spark的資料儲存大多依賴於Hadoop的分散式檔案系統HDFS。
-
Hadoop的MapReduce與Spark都可以進行資料計算,而相比於MapReduce,Spark擁有DAG執行引擎,支援在記憶體中對資料進行迭代計算。官方提供的資料表明,如果資料由磁碟讀取,速度是MapReduce的10倍以上,如果資料從記憶體中讀取,速度可以高達100多倍。
-
Spark的容錯性高,通用性好。
Spark的適用場景
- Spark是基於記憶體的迭代計算框架,適用於需要多次操作特定資料集的應用場合。需要反覆操作的次數越多,所需讀取的資料量越大,受益越大,資料量小但是計算密集度較大的場合,受益就相對較小
- 由於RDD的特性,Spark不適用那種非同步細粒度更新狀態的應用,例如web服務的儲存或者是增量的web爬蟲和索引。就是對於那種增量修改的應用模型不適合
- 資料量不是特別大,但是要求實時統計分析需求
Spark專案的pom.xml檔案
環境:intellij idea 2017.3.4 + maven 3.5.0
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>spark</groupId>
<artifactId>spark</artifactId>
<version>1.0-SNAPSHOT</version>
<!--<properties>-->
<!--<scala.version>2.11.8</scala.version>-->
<!--</properties>-->
<!--引入依賴的jar包-->
<dependencies>
<!--spark-core在資源庫的座標資訊-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<!--spark-sql在資源庫的座標資訊-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.3.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>com.databricks</groupId>
<artifactId>spark-avro_2.11</artifactId>
<version>4.0.0</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-my-jar-with-dependencies</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>