
邏輯迴歸預測貸款使用者是否會逾期
阿新 • • 發佈:2018-11-24
學習筆記(二)邏輯迴歸預測貸款使用者是否會逾期
演算法實踐能力的【整個思路】:構建模型——>模型融合——>模型評估——>交叉驗證——>模型調參——>特徵工程。【遵循】一次只做一件事,【先做再優化】的思路。每一個過程在完成任務的前提下,都可以拓展學習。【期望目標】掌握資料探勘的流程,提升合作的能力。各位已經有經驗,尤其是輔助的助教,還請多指導
給大家的是金融資料,我們要做的是預測貸款使用者是否會逾期,表格中,status是標籤:0表示未逾期,1表示逾期。要求:構建邏輯迴歸模型進行預測(在構建部分資料需要進行缺失值處理和資料型別轉換,如果不能處理,可以直接暴力刪除)
資料
資料處理
- 需要直接刪除的資料
-Unnamed: 0 使用者ID
trade_no:不知道是什麼,可以分析下
bank_card_no:卡號
id_name:名字
custid: ??? - 需要離散化處理的資料(未處理好,待學習)
- 針對日期資料的處理(轉換成年月日)(未處理好,待學習)
- 缺失值的填充
- 歸一化處理所有資料
程式碼展示
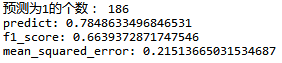
import numpy as np import pandas as pd from sklearn.metrics import classification_report from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.linear_model import SGDClassifier from sklearn.metrics import f1_score,mean_squared_error """ # 邏輯迴歸預測貸款使用者是否會逾期 """ datanew = pd.read_csv('F:/ziliao/data/data1.csv', encoding='gbk') """ 1.缺失值處理 """ datanew=pd.DataFrame(datanew.fillna(0)) # 簡單的缺失值處理 # datanew.replace(to_replace='0.', value=np.nan) # 丟棄帶有缺失值的資料 # datanew = datanew.dropna(axis=1, how='any') data_columns = datanew.columns """ 1.2 對reg_preference_for_trad 的處理 """ n = set(datanew['reg_preference_for_trad']) dic = {} for i, j in enumerate(n): dic[j] = i datanew['reg_preference_for_trad'] = datanew['reg_preference_for_trad'].map(dic) """ 1.3 資料集的切分 """ X_train, X_test, y_train, y_test = train_test_split(datanew[data_columns[1:90]], datanew[data_columns[44]],test_size=0.3, random_state=666) # 臨時將處理有難度的特徵刪去,留待日後處理 X_train.drop(["status","trade_no","bank_card_no","id_0me","source"],axis=1,inplace=True) X_test.drop(["status","trade_no","bank_card_no","id_0me", "source"],axis=1,inplace=True) """ 1.4標準化資料,方差為1,均值為零 """ standardScaler = StandardScaler() X_train_fit = standardScaler.fit_transform(X_train) X_test_fit = standardScaler.transform(X_test) log_reg = LogisticRegression() log_reg.fit(X_train_fit, y_train) log_reg_predict = log_reg.predict(X_test_fit) a=0 for i in log_reg_predict: if i == 1: a += 1 print("預測為1的個數:",a) print("predict:",log_reg.score(X_test_fit, y_test)) print("f1_score:",f1_score(y_test, log_reg_predict, average='macro')) print("mean_squared_error:",mean_squared_error(y_test, log_reg_predict))
結果:
問題
缺失值、日期、離散化資料的處理需要學習,資料處理的知識急需補充