
Vivado HLS 程式優化(基礎例項)(高階綜合)(FPGA)
前言(本文基於賽靈思官方HLS文件UG871中的7.1節):
在使用高層次綜合,創造高質量的RTL設計時,一個重要部分就是對C程式碼進行優化。
Vivado HLS擁有自動優化的功能,試圖最小化loop和function的latency,為了實現這一點,軟體會在loop和function上並行執行儘可能多的操作(比如說,在function級別上,高階綜合總是試圖並行執行function)。
除了這些自動優化,我們可以手動進行程式優化,即用在不同的solution中新增不同的directive的方法,進行優化和效能對比。其中,對同一個工程,可以建立多個不同的solution(解決方案),為不同的solution新增directive可以達到如下目的:
1、並行執行多個tasks,例如,同一個function的多次執行或同一loop的多次迭代。這是流水線結構。
2、調整陣列的物理實現((block RAM),函式,迴圈和埠(I/O),以提高資料的可用性,並幫助資料流更快地通過設計。
3、提供關於資料dependency的資訊,或者缺乏資料dependency,允許執行更多的優化。最終的優化是修改C原始碼,以消除在程式碼中意外的dependency,但是這可能會限制硬體的效能。
本文使用的例子是設計一個矩陣相乘函式。 目標是在每一個時鐘週期處理一個新的sample,並實現資料流介面。一、優化matrix multiplier。
1、solution1(無優化)
(1)矩陣乘法器設計,來顯示如何優化基於loop的設計。設計目標是在每個時鐘週期讀取一個使用FIFO介面的sample, 同時最大限度地減少面積。此分析包括在loop級優化和在function級優化的方法。
(1)對比loops和function pipeline的使用,建立一個可以處理取樣時鐘的設計。
(2)分析設計不符合效能要求的兩個最常見的原因:loops dependency和資料流的限制(或瓶頸)。
Step 1: 建立並開啟Project
找到Design_Optimization lab1資料夾,依次在Command Prompt 視窗輸入vivado_hls –f run_hls.tcl和vivado_hls –p matrixmul_prj
Step 2: 綜合分析設計
綜合後的結果:
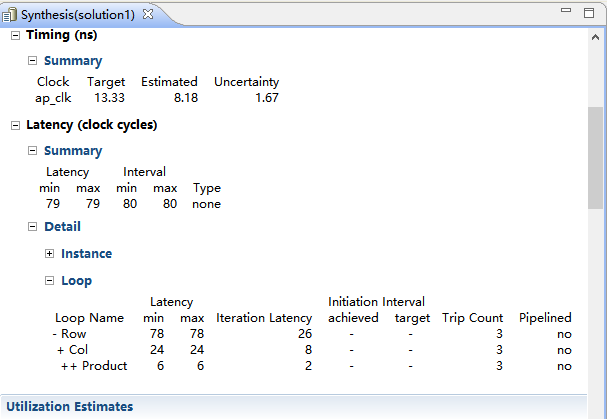 (1)圖中,總的interval為80個時鐘週期。因為每個輸入陣列中都有九個元素,所以設計每輸入讀取需要約九個週期;
(1)圖中,總的interval為80個時鐘週期。因為每個輸入陣列中都有九個元素,所以設計每輸入讀取需要約九個週期;
(2)interval比latency多一個時鐘週期,所以沒有在硬體上並行執行,即無流水;
(3)interval/latency的消耗主要是用於巢狀迴圈loops(本例有三種迴圈,每個迴圈均是迭代三次):
1)Product inner loop:
①有一個2個時鐘週期的延遲。
②總的迭代有6個時鐘週期。
2)COL loop:
①它需要1個時鐘輸入和1個時鐘退出。
②它需要8個時鐘週期為每個迭代(1 + 6 + 1)。
③總的有24個週期完成所有迭代。
3)頂層loops每次迭代需要26個時鐘週期,總的loops迭代共78時鐘週期。
為了改善initiation interval,則需要加入流水:pipeline loops或pipeline整個function,並比較這兩種結果。
當pipelining loops時,loops的initiation interval是監控的重要度量指標。即使設計達到loop可以在每個時鐘週期處理一個sample,函式的initiation interval仍然需要包含函式內的loops來完成所有資料的處理。
2、solution2:(Pipeline the Product Loop)
Step 1建立solution2,在Product loop下面插入pipeline directive(這裡在Directive Editor下選擇pipeline) 。
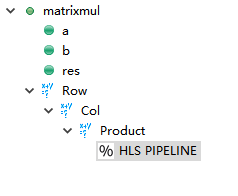 注意:當pipeline巢狀loop時,通過pipeline最內部Loop最大的好處就是,即有利於處理資料的sample。高階綜合自動應用loop flattening,摺疊巢狀loop,刪除loop轉換(本質上是建立一個更多迭代的單迴圈,但時鐘週期整體較少)。
注意:當pipeline巢狀loop時,通過pipeline最內部Loop最大的好處就是,即有利於處理資料的sample。高階綜合自動應用loop flattening,摺疊巢狀loop,刪除loop轉換(本質上是建立一個更多迭代的單迴圈,但時鐘週期整體較少)。
Step 2 綜合設計到RTL級
在綜合過程中,我們得到Console pane中報告的資訊,顯示loop flattening是loop Row上執行,預設內部Interval target為1由於依賴關係不能在loop Product上完成。
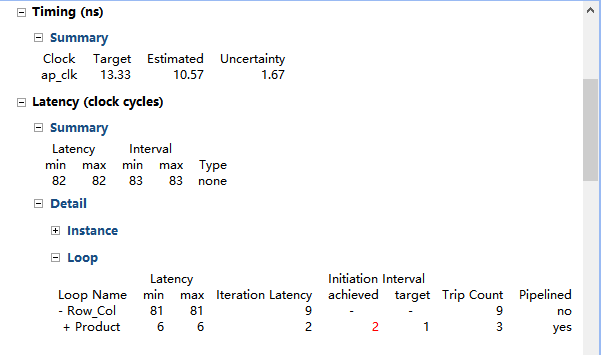 圖中表明,雖然Product loop已經被pipeline,interval為2,但是頂層loop沒有被pipeline。頂層loop不能pipeline的原因是,loop flattening只發生在loop Row,在loop Col 到Product loop上沒有loop flattening。(下面解釋loop flattening不能flatten所有nested loop的原因)
圖中表明,雖然Product loop已經被pipeline,interval為2,但是頂層loop沒有被pipeline。頂層loop不能pipeline的原因是,loop flattening只發生在loop Row,在loop Col 到Product loop上沒有loop flattening。(下面解釋loop flattening不能flatten所有nested loop的原因)
Step 3 開啟Analysis視窗,選擇state C1的write operation,右擊選擇Goto Source
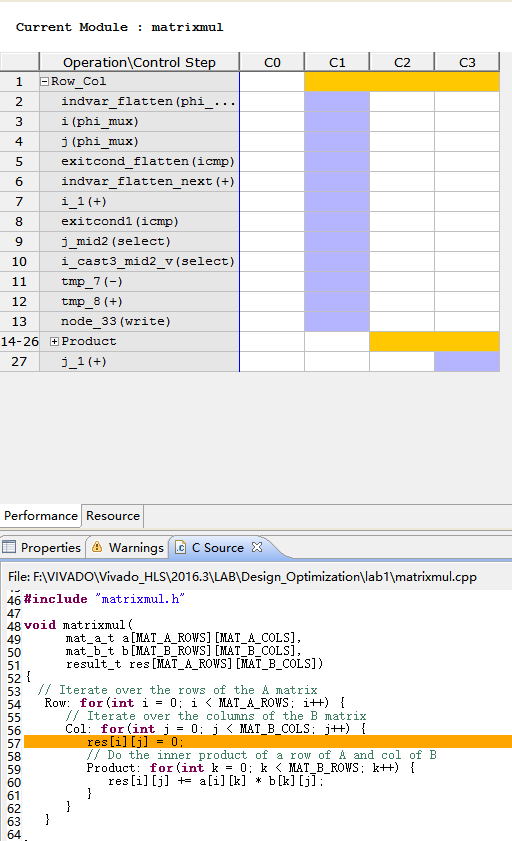 狀態C1下的寫操作是由於程式碼在Product loop前就已經設定res為0。因為res是在頂層函式,在RTL裡這是在寫入一個埠:這個操作必須發生在loop Product執行之前。因為它不是一個內部操作,而是會對I / O行為產生影響,這種操作不能移動或優化。這可以阻止Product loop被flatten進入row_col loop。
狀態C1下的寫操作是由於程式碼在Product loop前就已經設定res為0。因為res是在頂層函式,在RTL裡這是在寫入一個埠:這個操作必須發生在loop Product執行之前。因為它不是一個內部操作,而是會對I / O行為產生影響,這種操作不能移動或優化。這可以阻止Product loop被flatten進入row_col loop。
更重要的是,對於Product loop來說,為什麼只有II為2是可能flatten的?
這個問題被稱作carried dependency,這個dependency發生在一個loop的迭代操作和相同loop的不同迭代操作。例如,一個操作分別發生在K = 1時,當K = 2時(其中k是迴圈指數)。
第一個操作是在line 60陣列res上的儲存(記憶體讀操作)。
第二個操作是在line 60陣列res上的下載(記憶體寫操作)。
從圖中可以看到line 60是從陣列res的讀取(由於+=操作符)和寫入陣列res。陣列預設對映到RAM block,下面Performance View的細節解釋了為什麼會發生這種衝突。
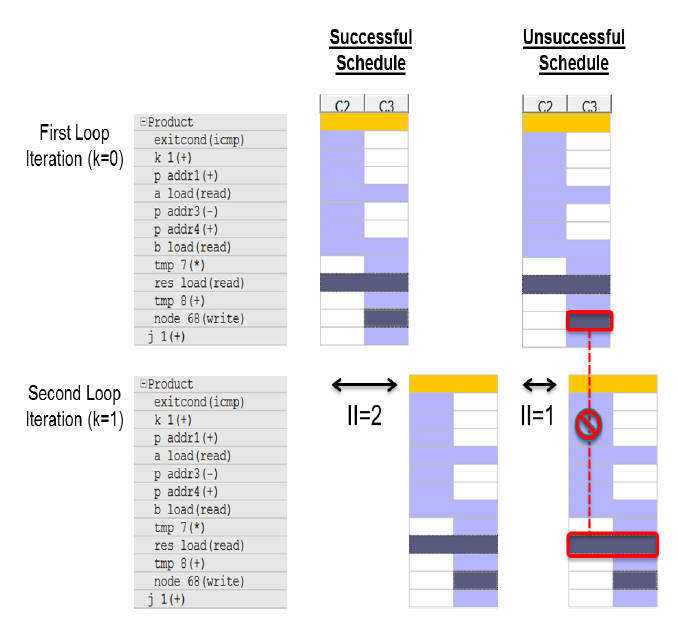 成功的schedule中,Product loop的下一次迭代如上所示。在這個schedule中,initiation interval(II)= 2,即loop操作每兩個週期重啟。任何block RAM之間的訪問沒有衝突。(沒有突出顯示的單元迭代重疊。)
成功的schedule中,Product loop的下一次迭代如上所示。在這個schedule中,initiation interval(II)= 2,即loop操作每兩個週期重啟。任何block RAM之間的訪問沒有衝突。(沒有突出顯示的單元迭代重疊。)
不成功的schedule顯示了為什麼loop不能在II = 1時pipeline。此時,下一次迭代將需要1個時鐘週期後開始。當第二次迭代嘗試一個地址去讀入時,第一次迭代中寫入block RAM的操作仍然發生。
這些地址是不同的,並且都不能在同一時間被應用到block RAM。
因此,你不能將Product loop的initiation interval 設定為1。下一步是pipeline Col loop。這將自動展開Product loop,並建立更多的operators,因此需要更多的硬體資源,但它確保在Product loop的不同迭代之間沒有dependency。3、solution3( Pipeline the Col Loop)
Step 1建立solution3,在Col Loop下面插入pipeline directive
Step 2 Run C Synthesis 
在綜合過程中,在控制檯窗格中報告的資訊顯示loop Product被展開,loop flattening是在loop Row上執行,預設initiation intervalv為1的目標不能在loop Row_Col上實現,這是由於陣列a上memory資源的限制。
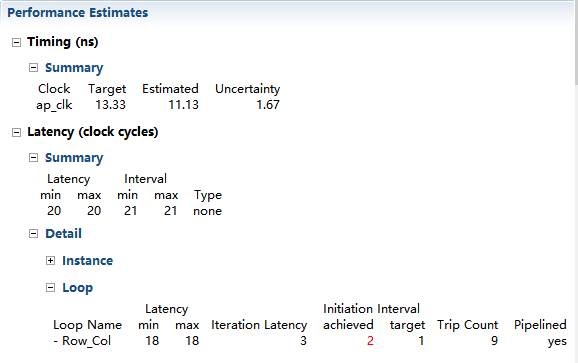 綜合報告顯示,如上所述,對loop Row_Col的interval只有2:目標是每個週期處理一個sample。你可以再一次使用Analysis視窗來證明為什麼不實現initiation target。
綜合報告顯示,如上所述,對loop Row_Col的interval只有2:目標是每個週期處理一個sample。你可以再一次使用Analysis視窗來證明為什麼不實現initiation target。
Step 3 開啟Analysis perspective,在Performance View裡,展開Row_Col loop
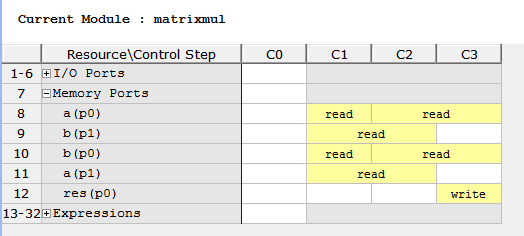
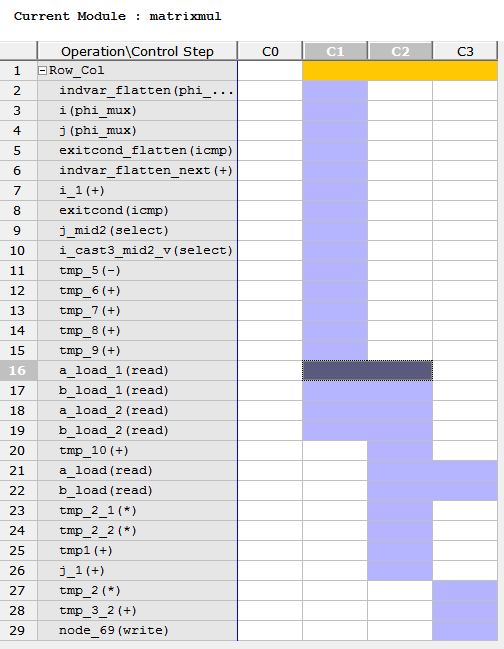 在陣列a中有三個讀操作。兩個讀操作開始於C1狀態,第三個讀操作開始與C2狀態。陣列被實現為block RAMs和陣列,這是引數的函式是實現塊記憶體埠。在這兩種情況下,一個block RAM最大隻能有兩個埠(對於雙埠block RAM來說)。訪問陣列a通過一個單一block RAM介面,沒有足夠的埠能夠在一個時鐘週期中讀取所有三個值。
在陣列a中有三個讀操作。兩個讀操作開始於C1狀態,第三個讀操作開始與C2狀態。陣列被實現為block RAMs和陣列,這是引數的函式是實現塊記憶體埠。在這兩種情況下,一個block RAM最大隻能有兩個埠(對於雙埠block RAM來說)。訪問陣列a通過一個單一block RAM介面,沒有足夠的埠能夠在一個時鐘週期中讀取所有三個值。
另一種檢視該資源限制的方法是使用到Resource視窗。
Step 4開啟Resource tab,擴充套件Memory Ports
狀態C1下面兩個讀操作與那些狀態C2下的讀操作重疊,因此,只有一個單一的週期是可見的:很顯然該資源被用於在多個狀態。即使當埠a的問題得到解決,相同的問題會發生在埠b:它也有三個讀操作。
高階綜合允許陣列被partitioned, mapped together和 re-shaped。這些都允許在不改變原始碼的情況下,對陣列進行修改。
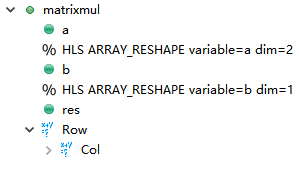
4、solution4(Reshape the Arrays)
Step 1 建立solution4,在Directive裡給陣列a和陣列b插入ARRAY_RESHAPE,選擇dimension分別為2和1
Step 2 Run C Synthesis
綜合報告顯示頂層loop Row_Col現在是每個時鐘週期處理資料的一個sample。
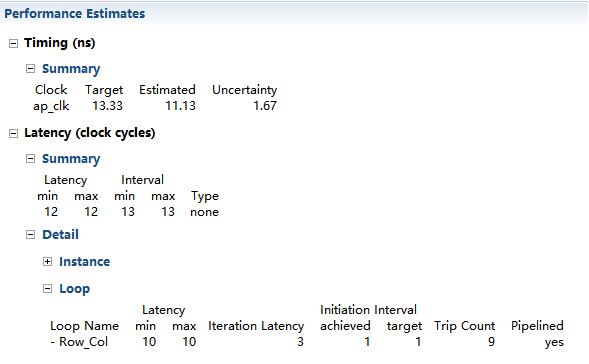 • 頂層模組需要12個時鐘週期才能完成。
• 頂層模組需要12個時鐘週期才能完成。
• 經過3次迴圈,Row_Col loop輸出sample(迭代延遲)。
• 然後每個週期讀取1個sample(Initiation Interval)。
• 9次iterations/samples(Trip count)完成所有samples。
• 3 + 9 = 12個時鐘週期
函式可以完成並返回開始處理下一組資料。現在,把block RAM介面設定為FIFO介面,資料流形式。
5、solution5(Apply FIFO Interfaces)
Step 1 建立solution5,在Directive裡給陣列a,b,res插入INTERFACE,在mode裡選擇ap_fifo

Step 2 Run C Synthesis,Console視窗報錯
•在line57寫[ 0 ] [ 0 ]。
•然後在line60寫[ 0 ] [ 0 ]。
•然後在line60一個寫[ 0 ] [ 0 ]。
•然後在line60一個寫[ 0 ] [ 0 ]。
•在line57寫入[ 0 ] [ 1 ](在增量指標J後)。
•然後在line60寫[ 0 ] [ 1 ]。

連續四個寫入地址[ 0 ] [ 0 ]不能構成一個數據流模式,而是隨機存取。
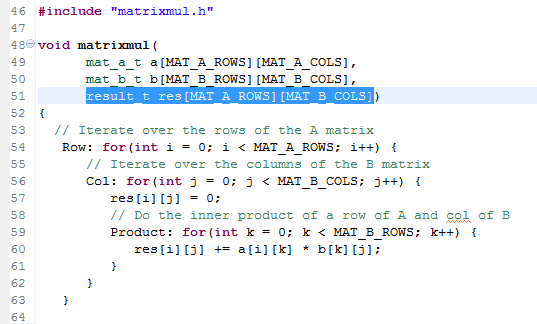
檢查程式碼後發現在陣列a和陣列b存在類似的問題。它是使用一個FIFO介面訪問程式碼已經寫好的資料,這是不可能實現的。在使用FIFO介面時,Vivado Hls的優化directives會有不足,因為當前程式碼執行了一定的讀寫順序。
下面pipeline整個function,對比這兩種方法的差異。
6、solution6(Pipeline the Function)
Step 1 建立solution6,刪掉loop Col下面的Directive,給matrixmul函式插入PIPELINE Directive
Step 2 Run C Synthesis,並比較各個report
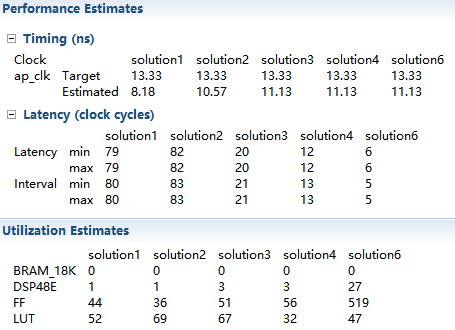 solution6在較少的時鐘就可以完成,並可以每5個時鐘週期開始一個新的transaction。然而,消耗的資源也大幅增加,因為所有的迴圈在設計中被開啟。
solution6在較少的時鐘就可以完成,並可以每5個時鐘週期開始一個新的transaction。然而,消耗的資源也大幅增加,因為所有的迴圈在設計中被開啟。
Pipelining loops允許迴圈保持rolling,從而提供了一個很好的方法來控制area。當pipeline一個函式時,函式中包含的所有 loops都是開啟,這是一個pipeline的要求。流水線功能設計可以每5個時鐘週期處理一組(9個)新的samples。這超過了每個時鐘處理1個sample的要求,因為高階綜合的預設行為是產生一個最高效能的設計。pipeline function會產生最好的效能,然而,如果它超過所需效能,它可能需要多個額外的directives。
一、優化 I/O Accesses的C程式碼
進一步優化需要重新編寫程式碼,下面介紹如何修改matrixmul.cpp的程式碼,來幫助克服一些在程式碼中固有的效能限制。
Step 1 建立並開啟Project
找到Design_Optimization lab2資料夾,依次在Command Prompt 視窗輸入vivado_hls –f run_hls.tcl和vivado_hls –p matrixmul_prj
Step 2 開啟matrixmul.cpp原始碼
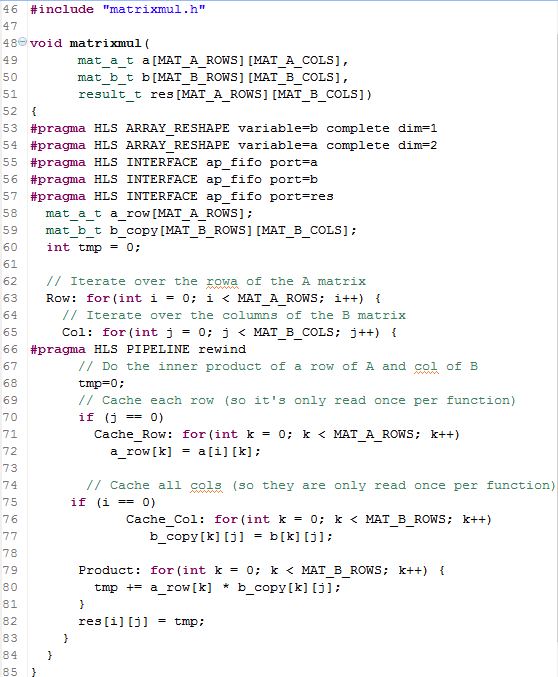 審查程式碼並確認以下:
審查程式碼並確認以下:
•之前的directives在這裡(包括FIFO介面)以pragmas形式指定的程式碼。
• for迴圈已被新增到快取行和列讀取。
•當最終的結果是計算為每個值時,一個臨時變數被用於累計,並且埠res只能被寫入。
•因為對於for迴圈快取行和列需要多個週期去執行讀取,pipeline directive已應用於Col for迴圈,來確保這些快取for迴圈自動開啟。
Step 3 Run C Synthesis
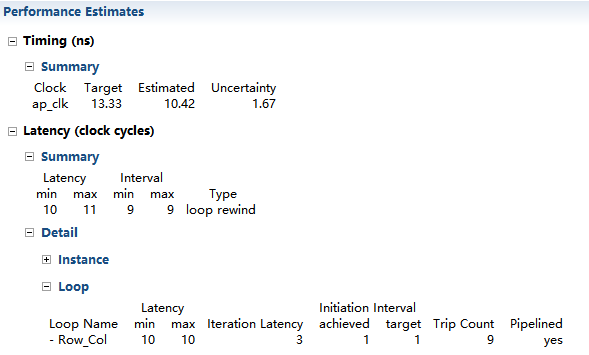 該設計已被完全綜合,每個時鐘週期讀取一個使用資料流FIFO介面的sample。
該設計已被完全綜合,每個時鐘週期讀取一個使用資料流FIFO介面的sample。
三、總結
本文介紹瞭如何分析pipelined loops,並準確地理解哪些限制阻止優化目標的實現。以及對function 和 loop 進行pipeline的優點和缺點。程式碼中意外dependencies可以阻止硬體設計目標實現,如何通過修改原始碼來克服它們。
######## 轉載請註明出處 https://blog.csdn.net/gentleman_qin/article/details/80043789 ########