
ElasticSearch資料分片-資料路由
ElasticSearch(簡稱ES):是一個基於Lucene構建的開源、分散式、RESTful的全文字搜尋引擎;它還是一個分散式實時文件儲存,其中每個field均是被索引的資料且可被搜尋;也是一個帶實時分析功能的分散式搜尋引擎,並且能夠擴充套件至數以百計的伺服器儲存及處理PB級的資料。
倒排索引:
1、什麼是node
ES叢集中每一個節點就是一個node,或者一個Elasticsearch例項就是一個節點。
node分類:
a、主節點:主節點不接受客戶端的請求,他主要控制Elasticsearch叢集,負責叢集中的操作,比如建立/刪除一個索引,跟蹤哪些節點是群集的一部分,並決定哪些分片分配給相關的節點。主節點處理叢集的狀態並廣播到其他節點,並接收其他節點的確認響應。 預設情況下任何一個叢集中的節點都有可能被選為主節點,每個節點都可以通過設定配置檔案elasticsearch.yml中的node.master屬性為true(預設),node.data屬性設定為false,成為主節點。對於大型的生產叢集來說,推薦使用一個專門的主節點來控制叢集,該節點將不處理任何使用者請求,穩定的主節點對叢集的健康是非常重要的。
b、資料節點:該節點具有儲存資料和執行資料相關的操作,如增刪改查,搜尋,和聚合操作。資料節點對cpu,記憶體,io要求較高,在優化的時候需要監控資料節點的狀態,當資源不夠的時候,需要在叢集中新增新的節點。預設情況下,每個節點都可以通過設定配置檔案elasticsearch.yml中的node.data屬性為true(預設)成為資料節點。如果我們要使用一個專門的主節點,應將其node.data屬性設定為false。
c、客戶端節點:該節點主要將客戶端的請求路由到叢集中的各個節點,扮演一個負載均衡的角色。將node.master屬性和node.data屬性都設定為false,那麼該節點就是一個客戶端節點。
d、部落節點:部落節點可以跨越多個叢集,它可以接收每個叢集的狀態,然後合併成一個全域性叢集的狀態,它可以讀寫所有節點上的資料,部落節點在elasticsearch.yml中的配置如下:tribe:*:
總結:
如果將master和client獨立出來,一旦出現問題,重啟後幾乎是瞬間就恢復的,對使用者幾乎沒有任何影響。另外將這些角色獨立出來的以後,也將對應的計算資源消耗從data node剝離出來,更容易掌握data node資源消耗與寫入量和查詢量之間的聯絡,便於做容量管理和規劃。
2、什麼是shard(分片)
一個 分片 是一個底層的 工作單元 ,它僅儲存了全部資料中的一部分,一個分片是一個 Lucene 的例項,它本身就是一個完整的搜尋引擎。我們的文件被儲存和索引到分片內,但是應用程式是直接與索引而不是與分片進行互動。
Elasticsearch 是利用分片將資料分發到叢集內各處的。分片是資料的容器,文件儲存在分片內,分片又被分配到叢集內的各個節點裡。當你的叢集規模擴大或者縮小時, Elasticsearch 會自動的在各節點中遷移分片,使得資料仍然均勻分佈在叢集裡。
注意:技術上來說,一個主分片最大能夠儲存 Integer.MAX_VALUE - 128 個文件,但是實際最大值還需要參考你的使用場景:包括你使用的硬體,文件的大小和複雜程度,索引和查詢文件的方式以及你期望的響應時長。
主分片:在索引建立的時候就已經確定了主分片數,但是副本分片數可以隨時修改,索引內任意一個文件都歸屬於一個主分片,所以主分片的數目決定著索引能夠儲存的最大資料量。
副分片:一個副本分片只是一個主分片的拷貝。副本分片作為硬體故障時保護資料不丟失的冗餘備份,併為搜尋和返回文件等讀操作提供服務。
建立名為 my_index 的索引,索引在預設情況下會被分配5個主分片。

PUT /my_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
檢視叢集中每個index的分片情況:
GET /_cluster/health?level=indices
3、什麼是index(索引)
index是儲存相關資料的地方,索引實際上是指向一個或者多個物理 分片的邏輯名稱空間 。事實上,我們的資料被儲存和索引在分片(shards)中,索引只是一個把一個或者多個分片分組在一起的邏輯空間,然而內部的一些細節不需要我們程式關心,文件儲存在索引(index)中,剩下的需要的工作交由Elasticsearch關心即可。索引命名規範這個名稱必須全部小寫,不能以下劃線開頭,不能包含逗號。
4、什麼是type
在Elasticsearch中,我們可以使用相同型別(type)的文件表示相同的"事物",因為他們的資料結構是相同的,每個型別都有自己的對映(mapping)或者結構定義,就像傳統資料庫表中的列一樣,所有型別下的文件被儲存在同一個索引下,但是型別的對映(mapping)會告訴Elasticsearch不同的文件如何被索引。_type的命名規範,它的名字可以是大寫或者小寫,不能包含下劃線或逗號,後面我們將使用employee作為型別名。
5、什麼是document(文件)
一條記錄,類似資料庫中的一列。在 Elasticsearch 中,術語 文件 有著特定的含義,它是指最頂層或者根物件, 這個根物件被序列化成 JSON 並存儲到 Elasticsearch 中,指定了唯一 ID。
文件元資料:_index:文件在哪存放; _type:文件表示的物件類別; _id:文件唯一標識(可以提供自己的 _id ,也可以讓 Elasticsearch 幫你生成)。通過_index、_type、_id 可以唯一確定 Elasticsearch 中的一個文件。
GET /car_index/car_type/1
檢查文件是否存在:
HEAD /car_index/car_type/1
當然,一個文件僅僅是在檢查的時候不存在,並不意味著一毫秒之後它也不存在:也許同時正好另一個程序就建立了該文件。
6、什麼是documnet routing(資料路由)
當客戶端發起建立document的時候,es需要確定這個document放在該index哪個shard上。這個過程就是資料路由。
路由過程:
路由演算法:shard = hash(routing) % number_of_primary_shards
routing:每次增刪改查一個document的時候,都會帶過來一個routing number,他的預設值就是這個document的_id(可能是手動指定,也可能是自動生成)routing = _id,所以決定一個document在哪個shard上,最重要的一個值就是routing值。相同的routing值,從hash函式中,產出的hash值一定是相同的。
number_of_primary_shards:主分片。
例如:假設_id=1會將這個routing值,傳入一個hash函式中,產出一個routing值的hash值,hash(routing) = 21,然後將hash函式產出的值對這個index的primaryshard的數量求餘數,21 % 3 = 0 就決定了,這個document就放在P0上。
手動指定routing:PUT /index/type/id?routing=user_id
手動指定routing value,可以保證某一類document一定被路由到一個shard上去,那麼在後續進行應用級別的負載均衡以及提升批量讀取的效能的時候,是很有幫助的。
7、為什麼primary shard數量不可變
假如我們的叢集在初始化的時候有5個primary shard,我們望裡邊加入一個document id=5,假如hash(5)=23,這時該document 將被加入 (shard=23%5=3)P3這個分片上。如果隨後我們給es叢集新增一個primary shard ,此時就有6個primary shard,當我們GET id=5 ,這條資料的時候,es會計算該請求的路由資訊找到儲存他的 primary shard(shard=23%6=5) ,根據計算結果定位到P5分片上。而我們的資料在P3上。所以es叢集無法新增primary shard,但是可以擴充套件replicas shard。
8、ES document增刪改的處理流程

ES增刪改的處理流程:增刪該的請求一定作用在主分片上。
假如我們es叢集有3個node,每個node上一個主分片一個複製分片。
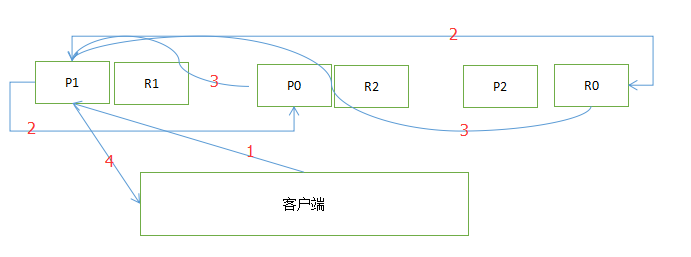
1、客戶端發起一個PUT請求,假如該請求被髮送到第一個node節點,那麼該節點將成為協調節點(coordinating node),如圖P1所在的節點就是協調節點。他將根據該請求的路由資訊計算,該document將被儲存到哪個分片。
2、第二步 通過計算髮現該document被儲存到p0分片,那麼就將請求轉發到node2節點。
3、第三步 P0根據請求資訊建立document,和相應的索引資訊,建立完畢後將資訊同步到自己的副本節點R0上。
4、第四步 P0和R0將通知我們的協調節點,任務完成情況。
5、第五部 協調節點響應客戶端最終的處理結果。
9、ES document讀請求流程
1、第一步客戶端傳送讀器請求到協調節點(coordinate node)。
2、第二步協調節點(coordinate node)根據請求資訊對document進行路由計算,將請求轉發到對應的node,node2 或者node3。 此時會使用round-robin隨機輪詢演算法,在primary shard以及其所有replica(副本)中隨機選擇一個,讓讀請求負載均衡。
3、第三步相應接收到請求的節點(node2或者node3)將處理結果返回給協調節點(coordinate node)。
4、協調節點將最終的結果反饋給客戶端。
注意:document如果還在建立索引過程中,可能只有primary shard有,任何一個replica shard都沒有,此時請求如果作用到replica shard上可能會導致無法讀取到document資訊。但是document完成索引建立之後,primary shard和replica shard就都有了。
每天用心記錄一點點。內容也許不重要,但習慣很重要!