
《2017-Xception Deep Learning with Depthwise Separable Convolutions》
本論文追求的不是準確率的提高,而是不降低準確率的前提下,減少引數數量,尋找更有的結構;
這篇論文是不錯的實驗模仿物件,以後做實驗可以按照本論文的思路探索;
動機
-
要解決什麼問題?
-
- 探尋Inception的基本思路,並將這種思路發揚光大。
-
用了什麼方法解決?
-
- 從Inception發展歷程的角度,理解其基本思想,並引入與Inception類似的Depthwise Separable Convolution結構。
- 將Inception V3結構中的Inception改用Depthwise Separable Convolution。
-
效果如何?
-
- 在與Inception V3引數數量相差無幾的情況下,在ImageNet上效能有略微上升,JFT上有明顯提高。
-
還存在什麼問題?
-
- Depthwise Separable Convolution不一定就是最優結構,還有尚未探索、驗證的相似結構。
假設
- corss-channels correlations 和 spatial correlations是分開學習的,而不是在某一個操作中共同學習的。
優勢
- Xception是Inception家族中一員。
- Inception的優勢:相比普通的卷積操作,Inception的表達能力更強。
empirically appear to be capable of learning richer representations with less parameters.
- Inception的基本思想:“通道”之間的相關性 與 空間相關性 最好要分開處理
cross-channel correlations and spatial correlations are sufficiently decoupled that it is preferable not to map them jointly.
方法
-
Xception是google繼Inception後提出的對Inception v3的另一種改進,主要是採用depthwise separable convolution來替換原來Inception v3中的卷積操作。
-
要介紹Xception的話,需要先從Inception講起,Inception v3的結構圖如下Figure1。當時提出Inception的初衷可以認為是:特徵的提取和傳遞可以通過1x1卷積,3x3卷積,5x5卷積,pooling等,到底哪種才是最好的提取特徵方式呢?Inception結構將這個疑問留給網路自己訓練,也就是將一個輸入同時輸給這幾種提取特徵方式,然後做concat。Inception v3和Inception v1(googleNet)對比主要是將5x5卷積換成兩個3x3卷積層的疊加。
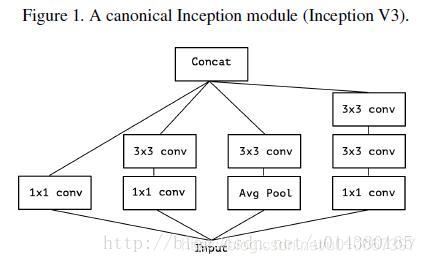
- 於是從Inception v3聯想到了一個簡化的Inception結構,就是Figure 2
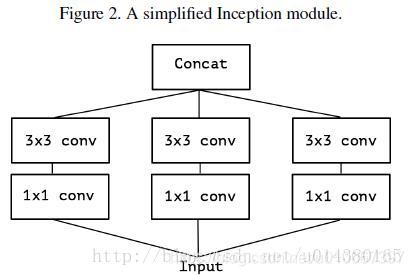
- 再將Figure2延伸,就有了Figure3,Figure3表示對於一個輸入,先用一個統一的1x1卷積核卷積,然後連線3個3x3的卷積,這3個卷積操作只將前面1x1卷積結果中的一部分作為自己的輸入(這裡是將1/3channel作為每個3x3卷積的輸入)。再從Figure3延伸就得到Figure4,也就是3x3卷積的個數和1x1卷積的輸出channel個數一樣,每個3x3卷積都是和1個輸入chuannel做卷積。
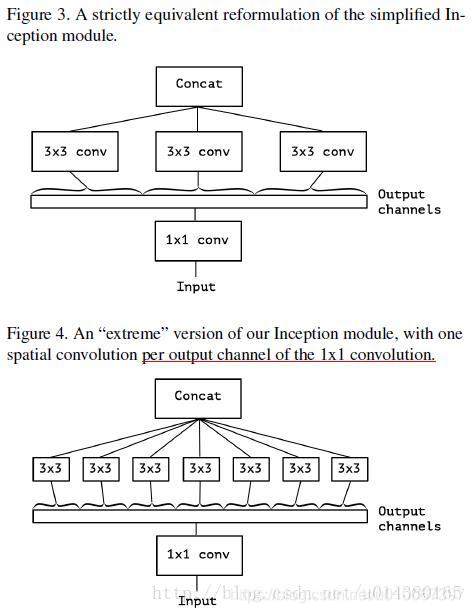
Depthwise Separable Convolution 與 “extreme” version of Inception Module比較
-
“extreme” version of Inception Module:具體操作過程可以參考上圖。
-
- 第一步:普通1x1卷積。
- 第二步:對1x1卷積結果的每個channel,分別進行3x3卷積操作,並將結果concat。
-
Depthwise Separable Convolution的結構在MobileNet V1中有詳細介紹。
-
- 第一步:depthwise卷積,對輸入的每個channel,分別進行3x3卷積操作,並將結果concat。
- 第二步:pointwise卷積,對depthwise卷積中的concat結果,進行1x1卷積操作。
-
Depthwise Separable Convolution 與 “extreme” version of Inception Module的區別:
-
- 操作循序不一致:Depthwise Separable Convolution先進行3x3卷積,再進行1x1卷積;Inception先進行1x1卷積,再進行3x3卷積。
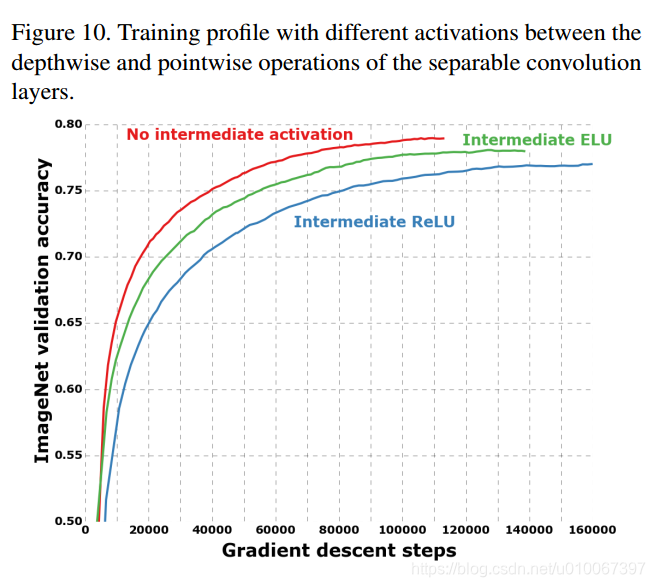
- 是否使用非線性啟用操作:Inception中,兩次卷積後都使用Relu;Depthwise Separable Convolution中,在depthwise卷積後一般不新增Relu。在本論文中,通過試驗進行驗證。具體原因在論文MobileNet V2中有解釋。
- 下面圖示方式給出兩者差別

- 差別二特別重要,
網路結構
- 以前卷積方法
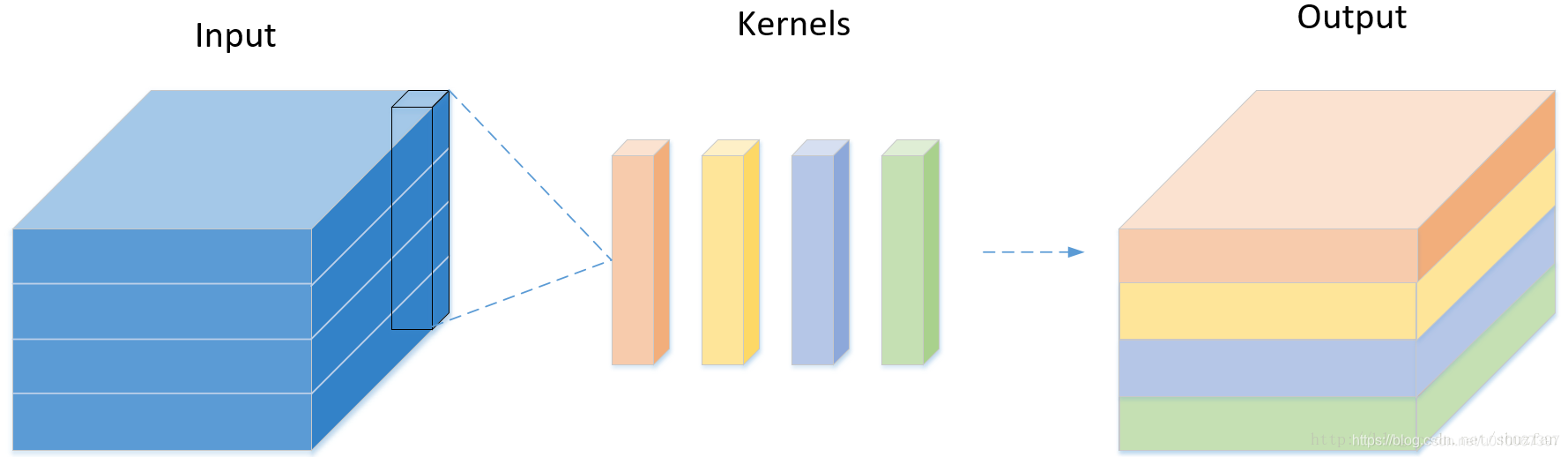
- depthwise 卷積方法
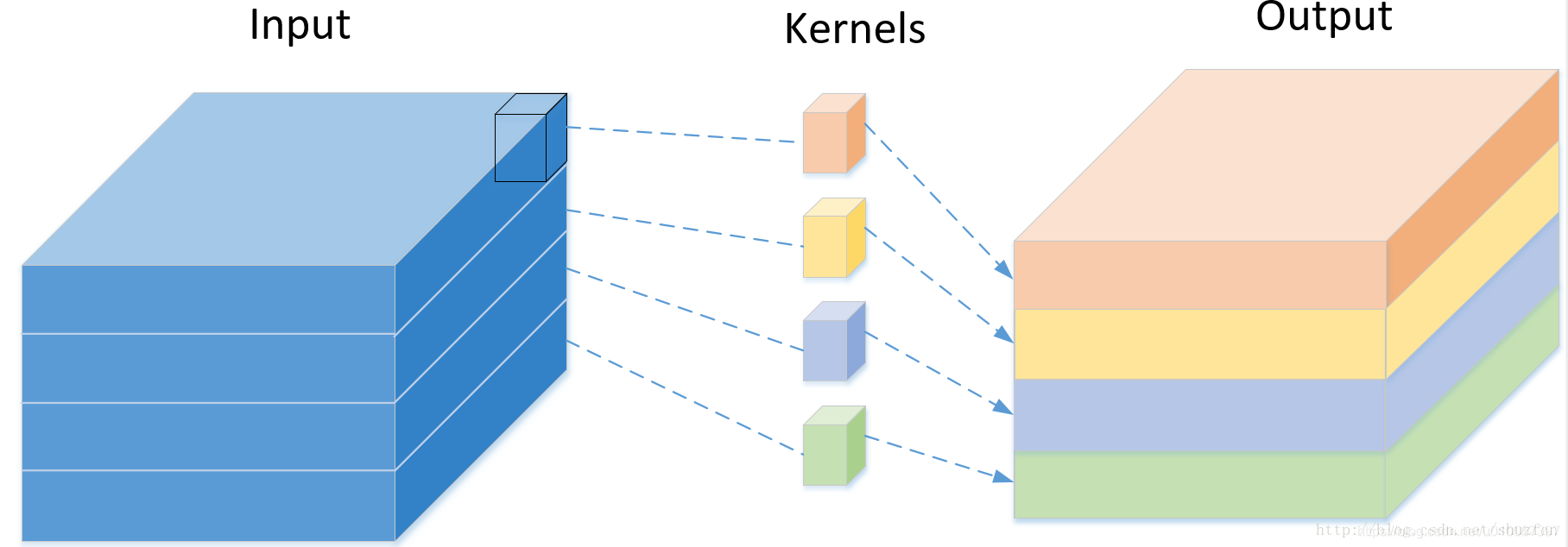
- 網路整體架構
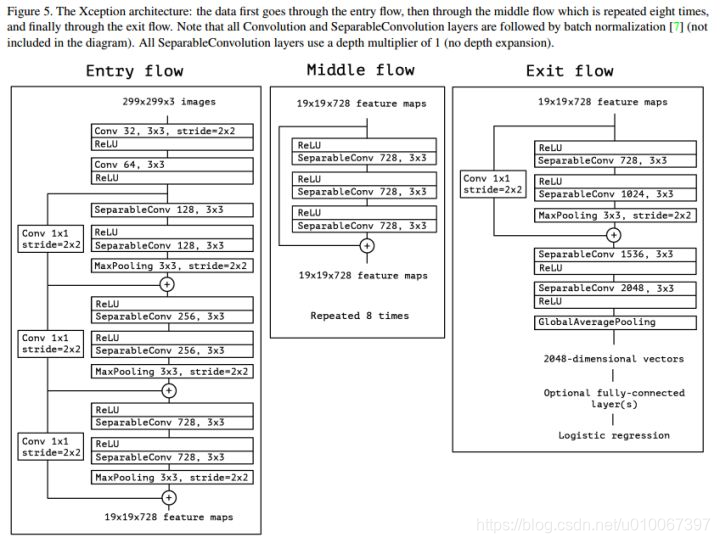
總結
- 從實驗結果來看, Xception在引數量上同Inception V3基本等同, 在Imagenet上的表現二者也很接近(另一個更大規模的Google私有資料集上,Xception的優勢要稍微明顯些)。
- 大規模使用Group操作,其實不利於矩陣層面的運算。即使可以減少引數,但不一定可以提高速度。
- Xception在效能上的提升比較有限,而且不能確定是否是ResNet結構帶來的提升。