
機器學習 (十三) 電商O2O優惠券使用預測-1
描述
發放優惠券是各大公司一種重要的營銷手段,如電商平臺、打車平臺、線下門店等等,幾乎所有涉及到客戶消費的行業都有優惠券的發放,那麼如何精準定位傳送優惠券,保證傳送的優惠券是真正想使用優惠券的人呢,或者我能預測出來每個客戶是不是用優惠券,這樣一是可以計算營銷成本,二是可以留住使用者提升品牌競爭力,對企業營銷有著重要意義。
思路流程
我們說這篇將介紹下如何通過機器學習方法來分析預測,在給客戶發券後在指定時間內使用者是否使用該券,
我們擁有某電商使用者2017年6月份的優惠券發放和使用記錄,利用這些資料來預測7月份使用者使用的概率。
- 理解資料
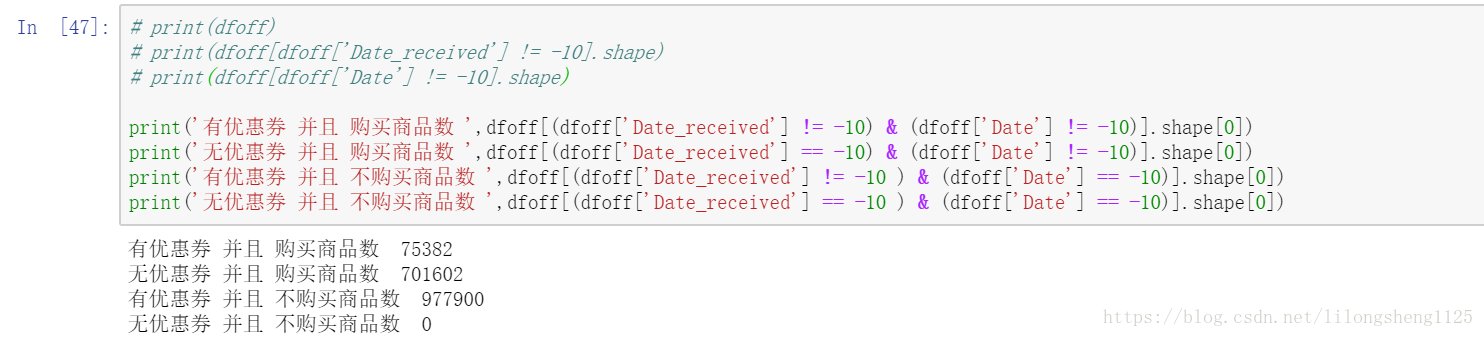
感覺理解資料非常重要,在這個場景中顯然使用者何時領取的優惠券、何時使用的是兩個比較重要特徵,這兩個特徵需要我們理解了資料,才能轉化為數字的方式表達出來,對資料理解的越深刻,以後我們可以挖掘的特徵越多,我們的模型當然訓練出來就越好,如下圖:
我統一將NaN值替換為-10了,方便處理,上面即通過優惠券接受日期判斷使用者是否收到優惠券,再通過是否購買上面商品來判斷使用者是否真正使用了券,這些資訊提取出來可以當做標籤,他們都是我們從資料中提取出來的資訊,可見有價值的資訊很多。
- 資料清洗
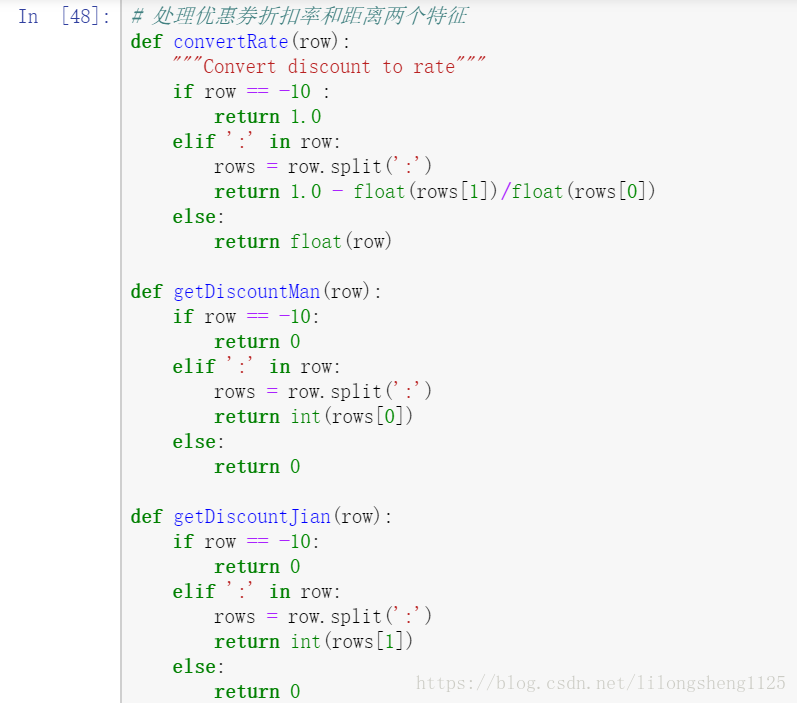
已經存在的資料需要清洗加工為統一的資料樣式,可以讓演算法直接處理的資料格式,如在處理折扣率、滿X減Y這種優惠時,將它們處理為統一值:
上面處理是將滿X減Y轉為了折扣率一樣的格式,方便後面進行模型訓練。

- 特徵提取
在原始資料中優惠券發放都是按著日曆來的,想一想可否將這個日期轉化為週期,也是可以的,比如:
這些特徵都是我們自己來從資料中提取,提取特徵需要充分理解原始資料才能提取出來有價值的特徵。


- 開始訓練
在第一次訓練時先只結合了使用者的兩個分析特徵,滿減折扣率特徵,我們拆分為了0-1之間的折扣率discount_rate,並且把滿X(discount_man)減Y(discount_jian),以及折扣型別(discount_type)等列,其次是接收優惠券的日期轉為了日期型別,並將日期列舉值轉為了one-hot型別欄位方便分析,這兩欄位也算是我們進行了擴充套件分析。
所有訓練屬性如下:

模型分析
在這部分涉及到sklearn中工具類,有必要了解下原理,方便我們今後使用SGDClassifier、Pipeline、GridSearchCV。
模型選擇:
在確定並清洗完訓練特徵後,下一步即選擇啥模型進行資料訓練,這裡我們目標是分類,那麼KNN、貝葉斯、SVM、LR等分類器是否都可以用呢,都是可以的,sklearn支援常用的分類器實現,可以直接用很方便,避免了重複造輪子,不過我們一定要理解它們的實現原理,這樣才能再上面不斷優化,創造新的學習器。
說得更專業一點,模型不管多複雜最終出來的是一個函式,根據函式的定義函式的重點是對映關係,如A到B可以通過各種函式來對映,則我們的模型即從輸入到輸出的一種對映關係,也可以這麼理解在數學領域對映叫函式,在機器學習領域叫模型,在李航老師的書中稱這個對映集合為假設空間(Hypothesis space),其實是為了方便理解那麼多情況而創造出來了一個名詞而已。
有很多種、確定了哪類模型後還需要調節各種引數不同引數還對應不同模型,首先我們來用LR分類器梯度上升求解。
引數調優:
sklearn同時頁為我們提供了除錯引數的方法grid_search,可以輸入引數列表和模型、評分函式,它會選擇出來得分最優的引數,如果不適用這個調參我們自己一個引數一個引數實驗也可以求出最優引數。
官網文件說明:http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html#sklearn.model_selection.GridSearchCV
SGDClassifier類主要採用梯度下降的方法實現了LR和SVM,也就是我們如果要使用邏輯迴歸和SVM進行預測分類時,該類時一個很好的選擇,官網文件如下:
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.SGDClassifier.html
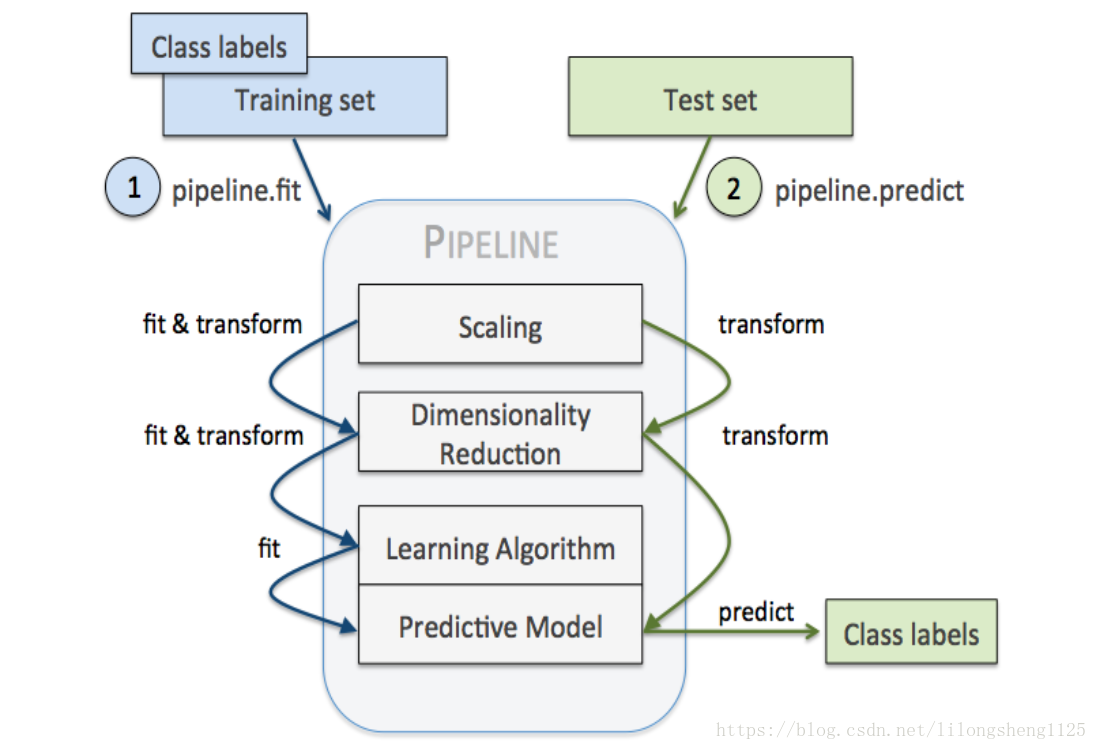
Pipeline機制在機器學習中也比較常見,就如管道含義一樣,他可以讓我們把好幾步流程串聯起來一起執行,使得程式碼簡介,類似於java中的鏈式程式設計寫法,像是一種程式設計技巧,經常放在管道中的步驟是標準化、降維、學習器三種類型的步驟,在管道中他們會依次執行,每兩個銜接地方有抓換介面卡,如下圖:
程式碼如下:
def check_model(data, predictors):
classifier = lambda: SGDClassifier(
loss='log', //對數損失函式 邏輯迴歸
penalty='elasticnet', //l1 l2結合
fit_intercept=True, //截距
max_iter=100, //迭代次數
shuffle=True, //打散樣本
n_jobs=1,
class_weight=None)//樣本權重一樣
model = Pipeline(steps=[
('ss', StandardScaler()),
('en', classifier())
])
parameters = {
'en__alpha': [ 0.001, 0.01, 0.1],
'en__l1_ratio': [ 0.001, 0.01, 0.1]
}
folder = StratifiedKFold(n_splits=3, shuffle=True)
grid_search = GridSearchCV(
model, //分類器
parameters, //引數列表
cv=folder, //交叉驗證folder數量
n_jobs=-1, //並行數
verbose=1)//日誌長度,不輸出訓練過程
//執行搜尋
grid_search = grid_search.fit(data[predictors],
data['label'])
return grid_search
model = check_model(train, predictors)
print(model.best_score_)//執行過程中觀察到的最好評分
print(model.best_params_)//取得最佳結果的引數組合
# valid predict
y_valid_pred = model.predict_proba(valid[predictors])
valid1 = valid.copy()
valid1['pred_prob'] = y_valid_pred[:, 1]
valid1.head(2)
# avgAUC calculation
vg = valid1.groupby(['Coupon_id'])
aucs = []
for i in vg:
tmpdf = i[1]
if len(tmpdf['label'].unique()) != 2:
continue
fpr, tpr, thresholds = roc_curve(tmpdf['label'], tmpdf['pred_prob'], pos_label=1)
aucs.append(auc(fpr, tpr))
print(np.average(aucs))
# test prediction for submission
y_test_pred = model.predict_proba(dftest[predictors])
dftest1 = dftest[['User_id','Coupon_id','Date_received']].copy()
dftest1['label'] = y_test_pred[:,1]
dftest1.to_csv('submit1.csv', index=False, header=False)
dftest1.head()
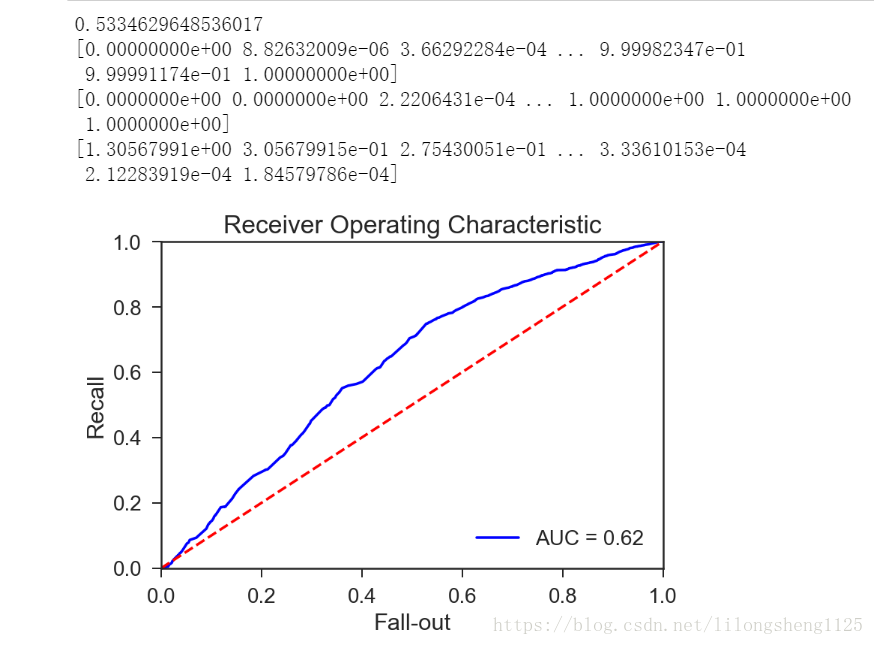
ROC曲線表示的是模型靈敏度,橫座標為FPR ,縱座標為TPR 即縱座標表示真正預測為正樣本的個數除以正樣本個數的比值,橫座標為預測為正的負樣本個數除以負樣本個數,我們想要的結果是TPR越高越好,但有時FPR也會升高。
第一個引數為標籤、第二個為預測概率值,第三個為指定哪類為正類,它的原理也很簡單是根據不同的閾值來計算不同的點,然後在連線起來即形成曲線。
from sklearn.metrics import auc
# import matplotlib as plt
plt.rcParams['axes.unicode_minus'] = False
roc_auc = auc(fpr_total, tpr_total)
plt.title('Receiver Operating Characteristic')
plt.plot(fpr_total, tpr_total, 'b', label='AUC = %0.2f' % roc_auc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('Recall')
plt.xlabel('Fall-out')
plt.show()
如下圖我畫出來的ROC曲線
ROC曲線評價統計量計算。ROC曲線下的面積值在1.0和0.5之間。在AUC>0.5的情況下,AUC越接近於1,說明診斷效果越好。AUC在 0.5~0.7時有較低準確性,AUC在0.7~0.9時有一定準確性,AUC在0.9以上時有較高準確性。AUC=0.5時,說明診斷方法完全不起作用,無診斷價值。AUC<0.5不符合真實情況,在實際中極少出現。根據經驗我們的AUC值為0.62說明模型預測準確率較低,因此還需要繼續優化,下篇我們繼續優化模型。
問題思考
-除了AUC曲線還有啥有效的方法來分析模型效果?
-我們計算出來AUC值為0.62,那麼如何優化模型?提取更有效的特徵還是模型上下功夫?
-AUC值是每一個樣本點的還是整個資料集的?
題外思考
耶魯大學的精神
耶魯大學是美國一所老牌有名的大學,很多國內外爭先恐後的進入,它也是唯一一所靠文科出名的大學,可見它將文學思想發揚光大,想一下世界各個大學辦學各有各自的特色,將每一種特色做到極致就會脫穎而出成為有名的大學,麻省理工等大學是在於理科研究和教學等方面非常優秀,其實大部分學校都注重理科教學質量,很少有大學拿文科來當做自己的強項,因為啥呢?是不是感覺文科是很虛的科目、是容易出來被罵專業軟文的學科,然而耶魯卻把文科的思想做的了極致,在創造新思想新文化、培養人作為未來領袖方面做到了極致。
舉個簡單的例子如果某個學生家鄉遇到困難,那麼它是鼓勵學習為之多做出一些力量,不是盡些綿薄之力而是盡全力,要有一種為家鄉、為祖國奉獻的責任感,將故鄉、社會、國家的責任當做自己的事情來做的責任感,與不在其位不謀其政思想正好相背離,有時感覺這種思想有點消極影響,它這所學校在於培養學生的責任感。
當然,我們偉大的祖國也不乏這種責任感,很久以前的唐朝就有詩人李賀 提筆 ,如下:
李 賀
男兒何不帶吳鉤,
收取關山五十州?
請君暫上凌煙閣,
若個書生萬戶侯?
李賀作為一個文弱書生,想拿起寶劍去收復五十州失地,這首詩被流傳千古是因為有社會責任感在裡面,有文化精髓在傳承,這些都是前任留下的寶貴財富,需要我們去靜靜品味。
參考文章
Pipeline機制
https://blog.csdn.net/lanchunhui/article/details/50521648
https://www.jianshu.com/p/9c2c8c8ef42d