
深度學習 --- 基於RBM的深度置信網路DBN-DNN詳解
上一節我們詳細的講解了受限玻爾茲曼機RBM的原理,詳細闡述了該網路的快速學習原理以及演算法過程,不懂受限玻爾茲曼機的建議先好好理解上一節的內容,本節主要講解的是使用RBM組成深層神經網路的深度置信網路DBN(Deep Belief Network),但是該網路效果並沒有那麼理想,hinton在此基礎上加入反向傳播演算法即DNN,使的效果要比DBN好太多了。為什麼會有這麼好的效果呢?通過前面幾節受限玻爾茲曼機的原理我們可以知道受限玻爾茲曼機理論上可以達到全域性最優解,即通過他訓練的資料基本上會處於全域性最優解的範圍以內,但為什麼深度RBM的表現並不是很好呢?因為特徵壓縮的很厲害,丟失了很多特徵資訊,下面會詳解,此時在結合BP。我們都知道BP的優缺點(不懂的
自編碼器
大家應該都知道什麼是壓縮吧,例如一張原始圖片有幾兆大小,我們通過壓縮技術,壓縮到幾百k,這個壓縮率很高了,但是帶來的影響就是影象會有明顯的馬賽克,不清晰,如下圖,左圖是原圖,右圖就是壓縮的,同時這裡的壓縮也叫編碼,同樣的神經網路也可以做壓縮編碼的工作,或者說神經網路可以做特徵提取,下面我們詳細看看神經網路是如何做編碼的。

影象劃分
一般圖片處理都是通過圖片劃分技術進行劃分,然後寫成矩陣的形式,如下圖加入一張圖片的畫素是128x128的,這裡使用4x4方格進行劃分,每個方格對應一個亮度值(這裡以灰度影象為例)即0~255的一個值,因此整個影象可以劃分為1024個方格,而每個方格的資料按列排列,最後一張圖片就可以儲存到一個16x1024的矩陣中,此時每一列就是我們的一個樣本,而每個樣本應該表示一個亮度值,總有1024個樣本,(這裡大家需要理解好,因為從這裡我就開始引入這些概念了,為後面的CNN做鋪墊),這樣我們使用這樣的樣本通過神經網路壓縮。如下圖所示:

編碼神經網路
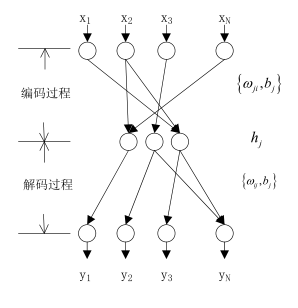
如上圖,上圖是一個經典的神經網路模型,只是這裡不同的是隱層的神經元要比輸入輸出少的,其實這就是壓縮的了即編碼,我們上面把圖片資訊寫成矩陣了,假如這裡把上圖的輸入神經元N=16,隱層的神經元為3個,輸出仍然為16個神經元,把圖片矩陣資料輸入這個神經網路進行訓練,學習演算法使用BP,最後使的誤差最小,此時的隱層就可以得到了一個3x1024的矩陣,因此圖片就壓縮了也叫編碼了,此時的訓練權值就是壓縮權值或者說是編碼權值即對應著上圖的編碼過程,如果解壓呢直接輸出y即可,對應上圖的解壓過程,這裡應該不難理解。因此是通過訓練的,一旦訓練好就可以對其他類的圖片進行壓縮了,因此稱為自編碼器。但是呢這個編碼器有個缺點就是 我不知道隱層我應該設計幾個神經元好,如果只最求壓縮率,設定一個神經元,但是解壓後的圖形將嚴重失真,如果最求失真度,那麼中間層我使用15個神經元,雖然 不失真,但是起不到壓縮效果,怎樣確定合適的神經元呢?這裡吳恩達的給出瞭解決方法即稀疏自編碼器。
稀疏自編碼器
大家有時間可以好好讀讀該論文《Sparse autoencoder》,這裡我簡要的介紹,公式不細推,當然能保證大家能看懂的。所謂稀疏自編碼器就是說中間的隱層的神經元數讓系統根據不同情況自動做出決定,使其達到壓縮率和失真度有個平衡。那麼我如何實現使他自動確定神經元的個數呢?又怎麼表達呢?這裡先按照上面的例子解釋一下,假如上面的例子隱層的神經元也為16個,通過自動決定機制讓其部分隱層神經元輸出逼近0,這時候這神經元就可以捨棄了,是通過這樣的機制實現的,但是又是通過什麼實現自動決定隱層神經元哪個輸出為0哪個不為0呢?這裡我先使用語言解釋,然後再通過圖片和數學來證明它,怎麼實現呢,其實很簡單,上面的例子自動編碼的學習函式其實是BP,他的誤差函式就是輸出和樣本的差,那麼我們在這個誤差函式的基礎上加一個懲罰項,這個懲罰項是隱層所有神經元的輸出和,那麼我們在求誤差函式的極小值時就把隱層的輸出考慮到了,因此他會限制隱層的輸出,至於怎麼限制的我們下面會說明。(這裡的懲罰項在機器學習裡經常使用,大家應該深入理解加入懲罰項的原因和好處,尤其要知道如何構造懲罰項,以後遇到類似問題,我們能否也類似構造懲罰項呢?),下面我們就詳細解釋一下稀疏自編碼器的工作原理。
這是自編碼器的流程圖:

這和我們舉得例子是一樣的,也就是BP神經網路了,code就是隱層輸出了,就是壓縮編碼了。假如input是比code更高維度的資料,其中誤差為下面計算,學習是通過BP學習。
稀疏自編碼器的流程圖

稀疏懲罰項(Sparsity Penalty) :
誤差項:
loss :
訓練演算法使用BP
我們發現了自編碼器和稀疏編碼的不同就是多了一個懲罰項,其他的都一樣,都是使用BP,那麼我們下邊就詳細解釋懲罰項的構造,但是BP我不會細講,前面都講過了。好,下面開始:
我們知道,常規的自編碼器是基於bp 的神經網路,這裡直接把損失函式寫出來不解釋。
![]()
下面細說懲罰項:
這裡啟用神經元代表輸出接近1,未啟用代表神經元接近0,我們希望隱層大多數的神經元都是未啟用狀態,因此如何設計懲罰項就很重要了。


上式表示隱藏層第j個的神經元輸出,上式是對隱藏層的神經元求和在取均值 ,如果想要達到未啟用的神經元儘量多的,則上式的均值應該儘量的小,這裡我們設定一個閾值
,使他們儘量相等,即:
例如如果我們假如=0.05,他們儘量的相等,且均值很小,在所有的隱層啟用函式中啟用的神經元並不多才能達到均值很小的目的,因此這樣才可以達到目的,關鍵是如何衡量他倆很接近呢?即如何建立關係式或者說建立優化目標?
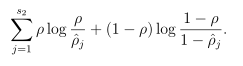
我們看到上式很複雜,其中s2代表隱層神經元的個數, 上式就是我們的懲罰項了,我們看看能否達到要求,如果,則此時二者的比值為1,取對數後為0,反之不為0,前後都這樣的,因此總體為0,因此可以達到我們的效果。
其實上式的來源是KL距離,這個我們在上一節說過,有興趣的同學可以查一下相關資料,KL的目的就是衡量兩個分佈的相似性,如果很相似則為0,反之不為零。

這兩個其實是伯努利分佈的接近程度,因此可以使用,我們看看圖:

如圖,這裡設定 =0.2,我們從圖中可以看到,在0.2是KL距離為0,在接近於1和0時,KL距離都急劇增大,也就是如果啟用的神經元多則均值就會變大,KL距離也會變大,我們的損失函式就會考慮這個情況,因此總的損失函式如下:

其中是說明懲罰項的重要程度的意思,後面就是計算了,不細講了,這就是稀疏自編碼器的原理,大家應該能看懂的。下面我們就介紹深度置信網路,因為有前面和上面的基礎,DBN會很簡單,另外就是稀疏自編碼器詳細的過程推倒請參考吳恩達的《Sparse autoencoder》這篇論文。
DBN-DNN
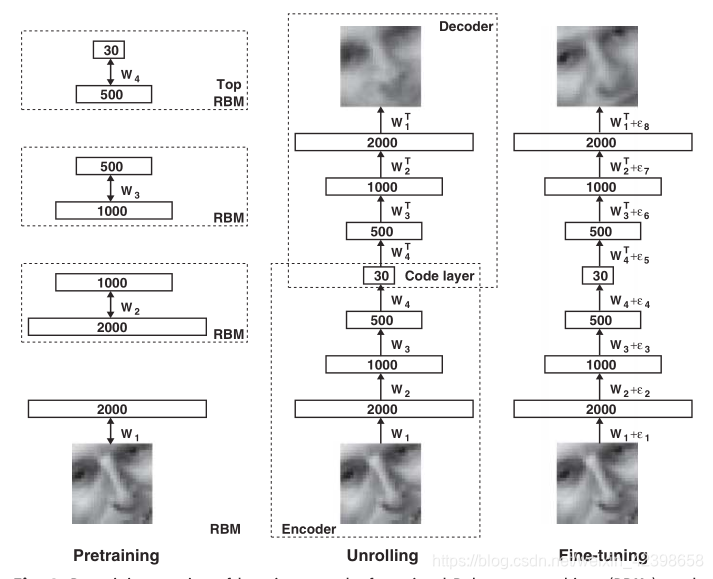
上面的就是hinton發表在nature的一篇經典之作,也因為這篇文章,深度學習開始發展起來,從上圖我們可以看到最左邊的圖是多個受限玻爾茲曼機,按照上面的理解,加入此時的黑白圖片的畫素點為2000,因此使用2000個神經元讀取,然後通過第一個受限玻爾茲曼機的編碼或者壓縮為1000個神經元,壓縮率為1\2,然後通過第二個RBM進行編碼為500個神經元,總壓縮率為1\4,然後使用第三個RBM繼續進行壓縮為30個神經元,此時總壓縮率接近1\60,可以說壓縮率很高了,把他們組合在一起就是編碼階段如上圖的中間部分,按照上面進行Decoder即解壓在觀察圖片,發現失真很嚴重了,但是總體輪廓還是有的,從圖中還是可以看出是一個人,好,到這裡大家有沒有一個疑問,就是上面的自編碼器和稀疏自編碼器一層效果那麼好為什麼還要建立深層的壓縮機制,直接使用一層不也可以壓縮編碼嗎?這裡大家先自己思考一下,下面我給解釋,雖然可以通過一步編碼也可以達到這個類似效果,但是一步壓縮其實是在原圖的基礎上直接進行特徵提取的,那麼什麼是特徵呢?根據上圖個人理解就是特徵就是圖片的輪廓即變化很激烈的地方(這個用訊號處理知識來解釋會更好,變化很激烈的一般高頻分量很豐富),這些地方有明顯的突出的地方,例如方桌他的四個角特徵很明顯,因為都直角變化了,但是桌面變化就不明顯了,即使變化也只是顏色的變化,這些不是重要的資訊,即我們無法通過顏色特徵識別這是個桌子,但是如果我們有桌子的四個拐角的特徵,那麼我們就可以判斷他是一個桌子,因此這裡我們可以把桌子的四個拐角看做深層特徵,而顏色看做淺層特徵了,總結一下,特徵就是一個物體的故有表徵,是區別其他物體的根本不同所在,例如區別自行車和三輪車,輪子個數就是很明顯的特徵,男生和女生的區別,頭髮,衣服,行為等可以區別開,也就是說當我們需要區分很接近的物品時,我們不能只依靠一個特徵,我們需要更多的特徵取區分,這就是影象識別裡的知識。好,我們繼續接著討論為什麼需要深層的自編碼器而不是一層,因為我們通過多層可以提取深層次的特徵即主要特徵,即第一層在總體上進行提取,提取到全域性的特徵,包括顏色、變化不明顯的地方都捕捉到了,在第二層我們繼續提取,此時在第一層的基礎上繼續提取特徵此時顏色就會被弱化,而變化很劇烈的特徵就會保留,後面多層就是把主要的輪廓保留下來了,其他的都捨棄了,如果只使用一層,那麼物體的主要輪廓無法凸顯,淺層特徵還保留著,直接結果可能我們無法從輪廓中識別他是什麼,因此需要深層的提取,這就是原因,以上解釋是 根據個人的理解(有什麼不對的請留言)。好,我們看到上圖的中間影象即Unrolling的編碼和解碼過程就是多個自編碼器的堆疊,從結果來看,DBN很好的提取到了深層特徵即總體輪廓保留下來了,但是細節損失嚴重,為了儘可能的保留細節方面,hinton把此訓練穩定的權值用作BP網路的初始權值,從前面幾節我們知道,RBM一旦收斂一般會收斂到全域性最優解附近,那麼BP網路在此基礎上進行微調,使其到全域性最優值,微調的另外一個目的就是儘可能的保留細節,因此得到的效果細節會更豐富,如上右圖所示,要比DBN的效果好很多,圖片的細節保留的很多,效果很好,因此最右邊的圖稱為DNN,整個圖片稱為DBN-DNN。
深度信念網路目前已經在語音識別、影象識別、以及自然語言處理等領域取得較好的效果,並得到了廣泛的使用。
到這裡就基本上結束了,大家有時間看看hinton的《Reducing the Dimensionality of Data with Neural Networks》這篇論文,主要內容就是上面的講的,講了RBM的訓練演算法,我們前幾節都講了,因此看起來會很容易的,好,本節到此結束,下一節我們講徑向基神經網路,這個網路在卷積神經網路會使用到。