
基於區域和物件的結構性度量的非二進位制前景圖分割的評估方法
南開大學提出新物體分割評價指標,相比經典指標錯誤率降低 69.23%

作者:範登平(南開大學)
【新智元導讀】南開大學媒體計算實驗室等研究團隊從人類視覺系統對場景結構非常敏感的角度出發,提出一種新穎、高效且易於計算的結構性度量(S-measure) 來評估非二進位制前景圖,進而使得評估不需要像傳統AUC曲線那樣通過繁瑣且不可靠的多閾值化來計算精度、召回率,僅通過簡單的計算(5.3ms)就可以得到非常可靠的評價結果,成為該領域第一個簡單的專用評價指標。相關研究已被ICCV 2017錄用為spotlight paper,第一作者南開大學博士生範登平帶來詳細解讀。
論文原始碼及相關資源:http://dpfan.net/smeasure/
前景圖的度量對於物體分割演算法的發展有著重要的作用,特別是在物體檢測領域,其目的是在場景中精確地檢測和分割出物體。但是,當前廣泛應用的評估指標 (AP, AUC) 都是基於畫素級別的誤差度量,缺少結構相似性度量,從而導致評估不準確(優秀演算法排名比拙劣演算法靠後)進而影響了領域的發展。
天津南開大學媒體計算實驗室、美國中佛羅里達大學機構的聯合研究團隊從人類視覺系統對場景結構非常敏感的角度出發,提出基於區域(Region-aware)和基於物件(Object-aware)的結構性度量 (S-measure) 方法來評估非二進位制前景圖,進而使得評估更加可靠。該方法在5個基準資料集上採用5個元度量證明了新度量方法遠遠優於已有的度量方法,並且和人的主觀評價具有高度一致性(77%Ours VS. 23%AUC)。
問題引出:專門評價指標缺陷
評價指標的合理與否對一個領域中模型的發展起到決定性的作用,現有的前景圖檢測中應用最廣泛的評價指標為:平均精度AP (average precision)和曲線下的面積AUC(area under the curve)。在評價非二進位制前景圖時,需要將輸入影象進行閾值化得到多個閾值,再計算精度(precision)和召回率(recall)。
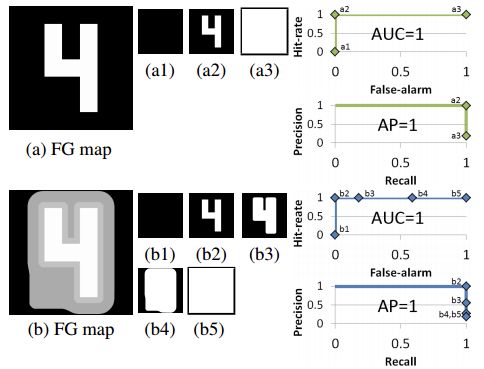
圖1
然而,該方法已經被證明[1] 存在天然的缺陷。例如圖1中(a)和(b)是兩個完全不同的前景圖,但是經過閾值化計算AP和AUC後,最後的評價結果是AP=1, AUC=1。這表示兩個前景圖的檢測效果相當,這顯然不合理。

圖2
再來看另外一個實際的例子,圖2中,根據應用排序(Application Ranking)以及人為排序(Human Ranking)認為藍色框的檢測結果優於紅色框。然而,如圖3所示,採用閾值化、再進行插值的方法(AUC)會評判紅色框檢測結果優於藍色框。

圖3
因此,AUC評價方法完全依賴於插值的結果,忽略了錯誤發生的位置,也沒有考慮到物件的結構性度量。原因在於,AUC曲線是多個領域通用的評價指標,前景圖檢測領域還沒有一個簡單高效的專有指標。為此,有必要為該領域設計一個專門的簡單可靠的評價指標。
解決方案:面向區域和麵向物件的結構度量
由於當前的評價指標都是考慮單個畫素點的誤差,缺少結構相似性度量,從而導致評估不準確。為此,研究團隊根據人類視覺系統對場景結構非常敏感的角度出發,分別從2個角度去解決結構度量的問題。
如圖4所示:(a)面向區域(Region-aware)結構度量和(b)面向物件(Object-aware)結構度量。
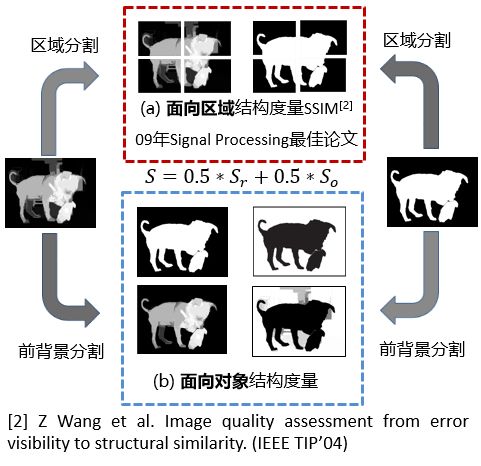
圖4
- 面向區域的結構度量將區域的前背景整體度量,作為面向物件(前背景分離度量)的補充,進而為可靠的整體結構度量提供支撐。
在計算面向區域部分,首先延著Ground-truth的重心部分採取2*2分塊法切割開,相應地為檢測結果圖切割,這樣得到4區域性塊,後每塊相似性度量方法採用著名的結構性評價指標SSIM來度量。最後,根據每個分塊佔整個前景圖的比例進行自適應加權求和得到面向區域的結構相似度。
b.面向物件的結構度量從物體角度出發,將前背景分離度量,與面向區域(前背景聚合成區域)互為補充,為度量物件級別的結構提供保障。
通過大量的研究發現,高質量的前景圖檢測結果具有如下特性:
- 前景與背景形成強烈的亮度對比。
- 前景與背景部分都近似均勻分佈。
如圖5所示,result1檢測結果中物件內部和背景部分相對均勻,唯獨亮度對比不夠強烈,result2檢測結果中內部物件分佈不均勻,背景部分大體均勻。
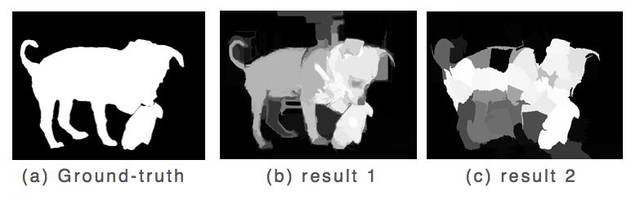
圖5
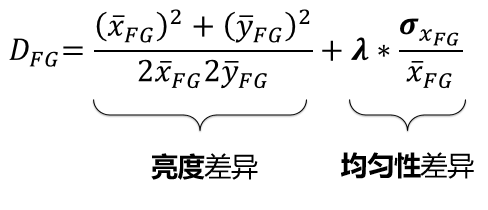
研究團隊通過設計一個簡單的亮度差異和均勻性項來度量結構相似性。
元度量實驗證明有效性
為了證明指標的有效性和可靠性,研究人員採用元度量的方法來進行實驗。通過提出一系列合理的假設,然後驗證指標符合這些假設的程度就可以得到指標的效能。簡而言之,元度量就是一種評測指標的指標。實驗採用了5個元度量:
元度量1:應用排序
推動模型發展的一個重要原因就是應用需求,因此一個指標的排序結果應該和應用的排序結果具有高度的一致性。即,將一系列前景圖輸入到應用程式中,由應用程式得到其標準前景圖的排序結果,一個優秀的評價指標得到的評價結果應該與其應用程式標準前景圖的排序結果具有高度一致性。如下圖6所示。
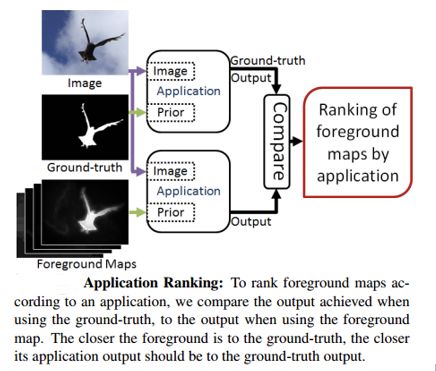
圖6
元度量2:最新水平 vs.隨機結果
一個指標的評價原則應該傾向於選擇那些採用最先進演算法得到的檢測結果而不是那些沒有考慮影象內容的隨機結果(例如中心高斯圖)。如下圖7所示。

圖7
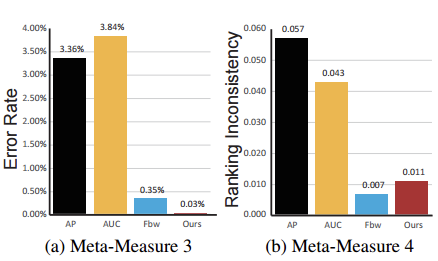
元度量3:參考GT隨機替換
原來指標認定為檢測結果較好的模型,在參考的Ground-truth替換為錯誤的Ground-truth時,分數應該降低。如圖8所示。
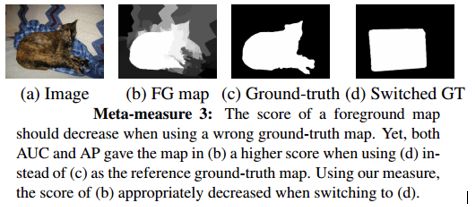
圖8
元度量4:輕微標註錯誤
評價指標應該具有魯棒性,一個好的評價指標不應對GT邊界輕微的手工標註誤差敏感。如圖9所示

圖9
元度量5:人工排序
人作為高階靈長類動物,擅長捕捉物件的結構,因此前景圖檢測的評價指標的排序結果,應該和人的主觀排序具有高度一致性。我們通過收集45個不同年齡,學歷,性別,專業背景的受試者的排序結果進一步證明了提出的評價指標與人的評價具有高度的一致性(最高可達77%)。下圖10所示為使用者調研的手機平臺。
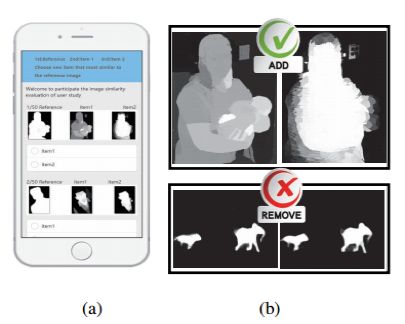
圖10
實驗結果
為了公平的比較,指標首先在公開的一個前景圖檢測資料集ASD[3]上對4個元度量進行評測。評測結果顯示我們的結果取得了最佳效能:
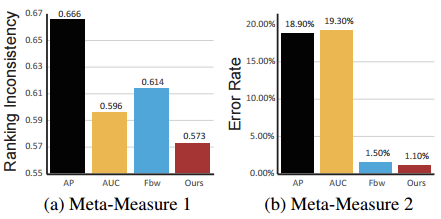
除了在基準資料集上進行評測外,還在另外4個具有不同特點的、更具挑戰性資料集上進行了廣泛的測試,以驗證指標的穩定性、魯棒性。

實驗結果表明:我們的指標分別在PASCAL, ECSSD, SOD和HKU-IS資料集上比排名第二的指標錯誤率降低了67.62%,44.05%,17.81%,69.23%。這清楚地表明新的指標具有更強的魯棒性和穩定性。
總結
該評測指標將很快出現在標準的Opencv庫以及Matlab中,屆時可以直接呼叫。
評測指標的程式碼計算簡單,僅需對均值、方差進行加減乘除即可,無需閾值256次得到多個精度和召回率,再畫進行繁瑣的插值計算得到AUC曲線。因此,S-measure計算量非常小,在單執行緒CUP(4GHz)上度量一張影象僅需要5.3ms.
程式碼連結:https://download.csdn.net/download/kateyabc/10638955
專案主頁:http:// dpfan.net/smeasure/
參考文獻:
【1】How to evaluate the foreground maps? 2014, CVPR
【2】Image quality assessment from error visibility to structural similarity. 2004 TIP.
【3】Frequency-tuned salient region detection. 2009, CVPR
轉載地址:http://www.sohu.com/a/228413138_473283