
python3爬取1000個百度百科頁面(一)
阿新 • • 發佈:2018-11-24
一、基本概念
爬蟲:一段自動抓取網際網路資訊的程式
二、簡單爬蟲架構

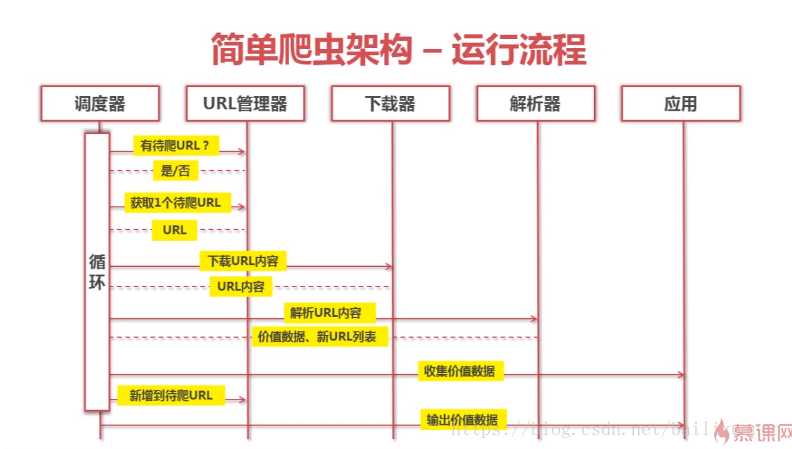
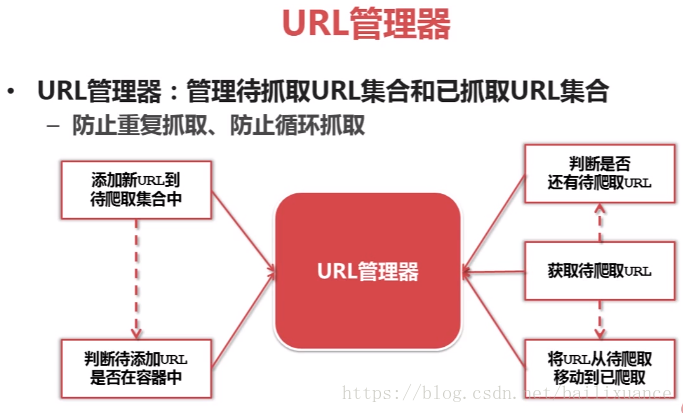
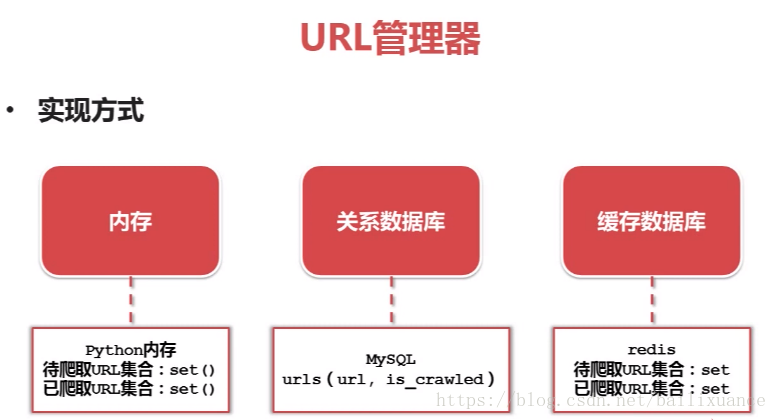
1、URL管理器:管理已經爬取和未曾爬取的url,防止重複、迴圈抓取
python中set可以直接去除重複元素
2、網頁下載器:將網頁下載到本地,urllib2,request,
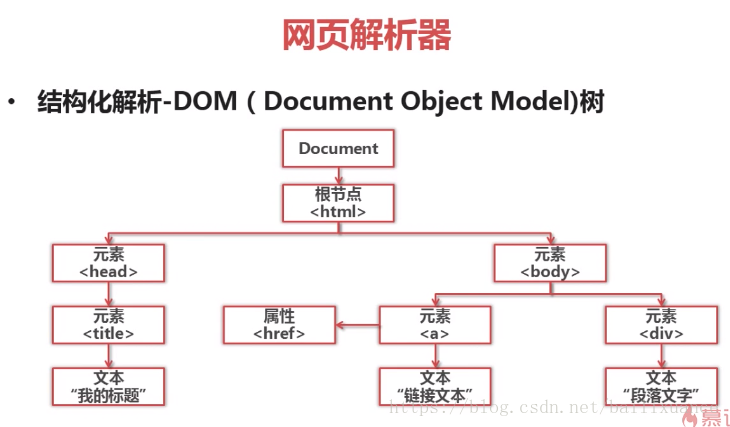
3、網頁解析器:從網頁中提取有價值的資料的工具,可以解析網頁含有的url和資料,方式有正則表示式、html.parser、BeautifulSoup等
結構化解析:將網頁解析成DOM(Document Object Mode)樹
三、使用urllib下載網頁的三種方法
import urllib.request import http.cookiejar url = "http://www.baidu.com" # 最簡潔的方法 print("第一種方法") # 返回網頁內容 response1 = urllib.request.urlopen(url) # getcode()返回狀態碼,返回200,則網頁下載成功,否則失敗, print(response1.getcode()) # read()方法來獲取下載的內容 print(len(response1.read())) print("第二種方法") request = urllib.request.Request(url) # 把爬蟲偽裝成Mozilla瀏覽器 request.add_header("user-agent","Mozilla/5.0") response2 = urllib.request.urlopen(url) print(response2.getcode()) print(response2.read()) # 新增特殊情景處理器,HTTPCookieProcessor、ProxyHandler等 print("第三種方法") cj = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj)) # 安裝這個opener urllib.request.install_opener(opener) response3 = urllib.request.urlopen(url) print(response3.getcode()) print(cj) print(len(response3.read()))
注:
1、在python3中,在python3.3後urllib2已經不能再用,只能用urllib.request來代替,
2、在python3中,cookie要使用http.cookiejar,而不是cookie
四、BeautifuSoup模組解析
BeautifuSoup文件:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
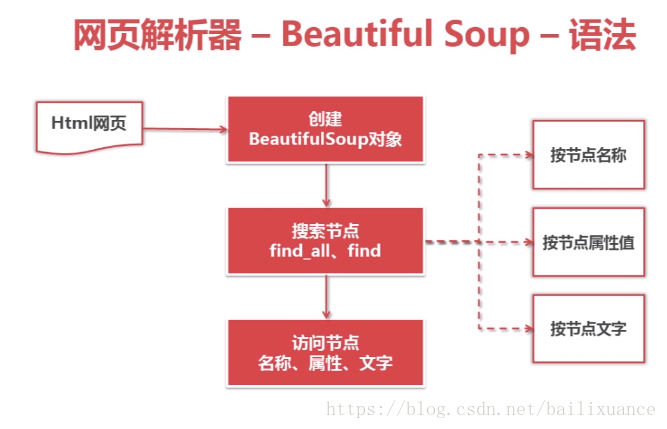
1、將網頁下載成DOM樹
2、搜尋各種節點find_all(搜尋所有滿足條件的節點),find(只搜尋第一個節點)。引數都一樣
然後可以訪問節點的名稱、屬性、文字,也可以按照節點名稱、屬性、文字訪問,

# bs4模組 解析字串
from bs4 import BeautifulSoup
import re
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
# 建立BS物件
# html.parse是解析器
soup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')
print("獲取所有的連結")
# 查詢所有標籤為'a'的節點
links = soup.find_all('a')
for link in links:
print(link.name,link['href'],link.get_text())
print("獲取lacie的連結")
link_node = soup.find('a',href = "http://example.com/lacie")
print(link_node.name,link_node['href'],link_node.get_text())
# 正則匹配(模糊匹配)
print("正則匹配")
# 字母r,正則表示式出現反斜槓的話,我們只需要寫一個
link_node = soup.find('a',href = re.compile(r"ill"))
print(link_node.name,link_node['href'],link_node.get_text())
# 獲取P段落文字
# class是python關鍵字,所以加下劃線
print("獲取P段落文字")
p_node = soup.find('p',class_ = "title")
print(p_node.name,p_node.get_text())