
Ubuntu 18.04.1 LTS 搭建Hadoop環境
1.Ubuntu環境配置
本文使用Ubuntu 18.04.1 LTS,其他版本搭建過程基本一致。
建立hadoop使用者(可略)
1.建立新使用者
$ sudo useradd -m hadoop -s /bin/bash
2.設定密碼
$ sudo passwd hadoop
3.為 hadoop 使用者增加管理員許可權
$ sudo adduser hadoop sudo
4.登出當前使用者並切換到hadoop使用者
更新apt
$ sudo apt-get update
安裝Vim
$ sudo apt-get install 安裝SSH、配置SSH無密碼登陸
叢集或單節點模式都需要用到 SSH 登陸。Ubuntu 預設安裝了 SSH client,此外還需要安裝 SSH server
$ sudo apt-get install openssh-server
使用ssh localhost登陸本機(需要輸入密碼)
為了避免每一次使用SSH都要輸入密碼,利用 ssh-keygen 生成金鑰,並將金鑰加入到授權中:
$ cd ~/.ssh/ # 如果不存在該資料夾,需要先登陸本機
$ ssh-keygen -t rsa # 會出現多個提示,全部回車
$ cat ./id_rsa.pub >> 登陸本機
$ ssh localhost
安裝Java環境
安裝前最好更改系統軟體源為國內源(阿里雲)
$ sudo apt-get install default-jre default-jdk
需要配置JAVA_HOME環境變數
$ vim ~/.bashrc
加入這一行
export JAVA_HOME=/usr/lib/jvm/default-java
退出,讓環境變數生效
$ source ~/.bashrc
測試
$ echo $JAVA_HOME
$ java -version
$ $JAVA_HOME 2.安裝 Hadoop 2
需要下載編譯好的hadoop-2.x.y.tar.gz 檔案
我下載的是2.7.6
將 Hadoop 安裝至 /usr/local/ 中:
$ sudo tar -zxf ~/Download/hadoop-2.7.6.tar.gz -C /usr/local
$ cd /usr/local/
$ sudo mv ./hadoop-2.7.6/ ./hadoop
$ sudo chown -R hadoop ./hadoop # 修改檔案許可權,第一個hadoop為使用者名稱
Hadoop 解壓後即可使用。檢測:
$ cd /usr/local/hadoop
$ ./bin/hadoop version
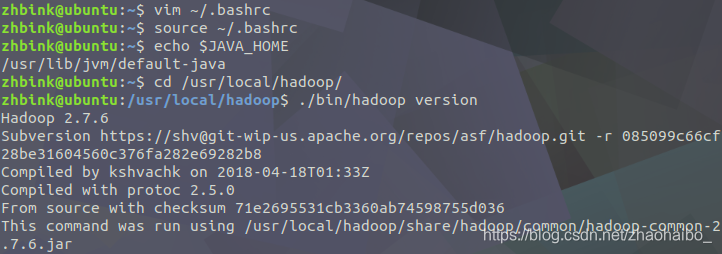
Hadoop 預設模式為非分散式模式(本地模式),無需進行其他配置即可執行。
Hadoop偽分散式配置
因為只是簡單地學習,僅使用偽分散式的方式。
修改配置檔案 core-site.xml ( vim ./etc/hadoop/core-site.xml),將
<configuration></configuration>
修改為:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.
</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改配置檔案 hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
執行 NameNode 的格式化:
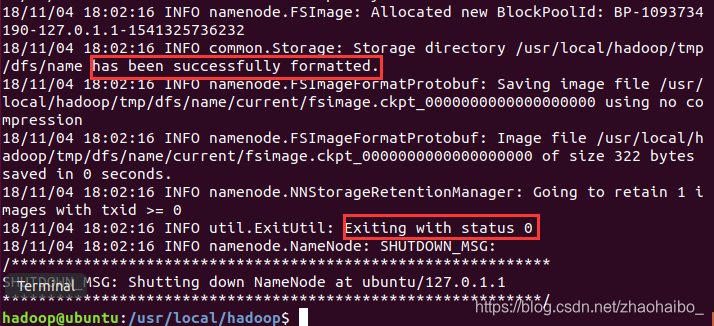
$ ./bin/hdfs namenode -format
出現 “successfully formatted” 和 “Exitting with status 0”則代表成功
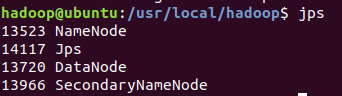
開啟 NameNode 和 DataNode 守護程序。
./sbin/start-dfs.sh
通過 jps 可以判斷是否成功啟動
如果有NameNode 或 DataNode則配置成功
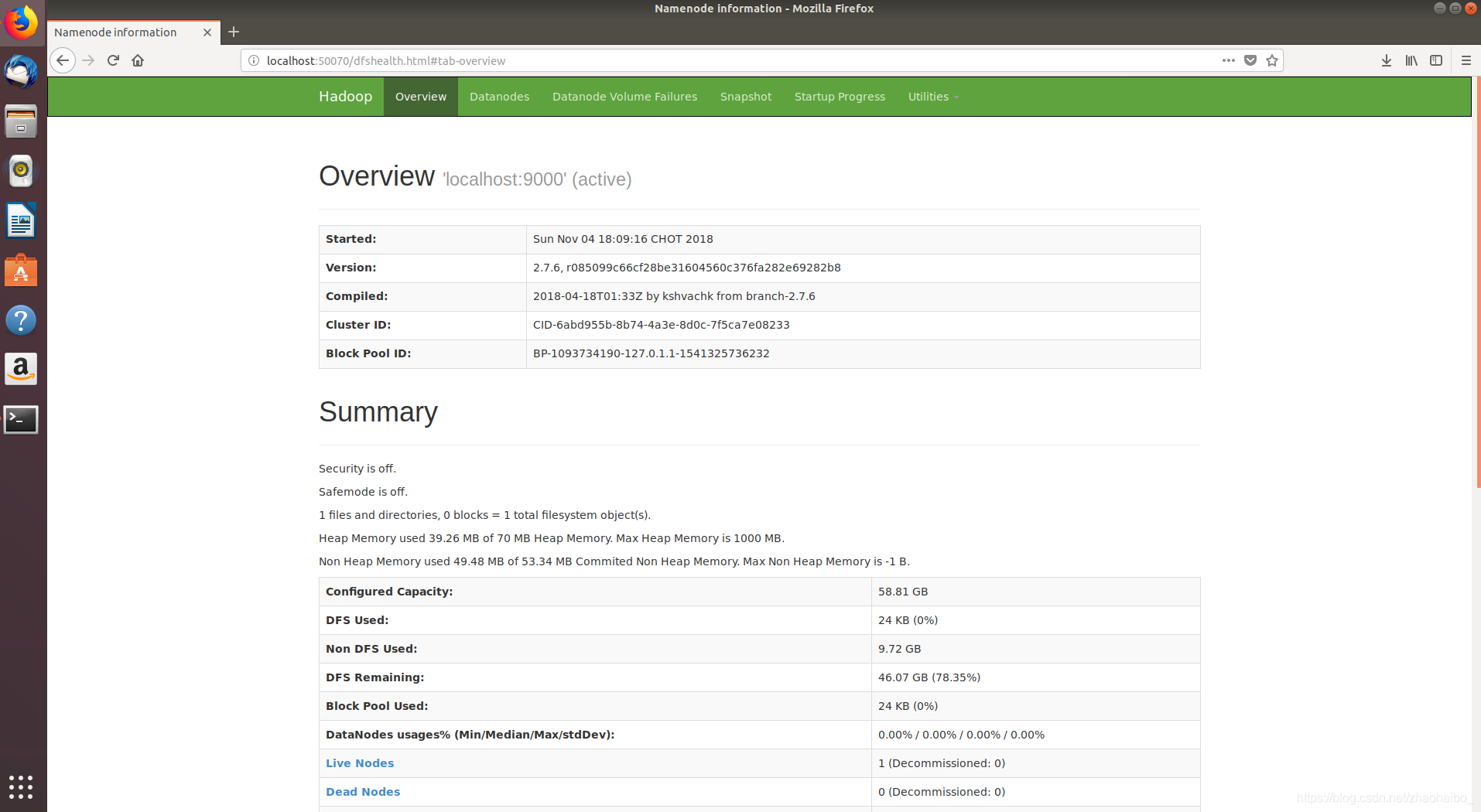
可以訪問 http://localhost:50070 檢視詳細資訊
使用HDFS
在 HDFS 中建立使用者目錄
$ ./bin/hdfs dfs -mkdir -p /user/hadoop
注:
- hadoop fs適用於任何不同的檔案系統,比如本地檔案系統和HDFS檔案系統
- hadoop dfs只能適用於HDFS檔案系統
- hdfs dfs跟hadoop dfs的命令作用一樣,也只能適用於HDFS檔案系統
開啟hdfs
$ ./sbin/start-dfs.sh
關閉hdfs
$ ./sbin/stop-dfs.sh
YARN
YARN 負責資源管理與任務排程。YARN 運行於 MapReduce 之上,提供了高可用性、高擴充套件性。
修改配置檔案 mapred-site.xml
重新命名:
$ mv ./etc/hadoop/mapred-site.xml.template ./etc/hadoop/mapred-site.xml
編輯 vim ./etc/hadoop/mapred-site.xml :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
修改配置檔案 yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value>
</property>
</configuration>
啟動 YARN (需要先執行過 ./sbin/start-dfs.sh):
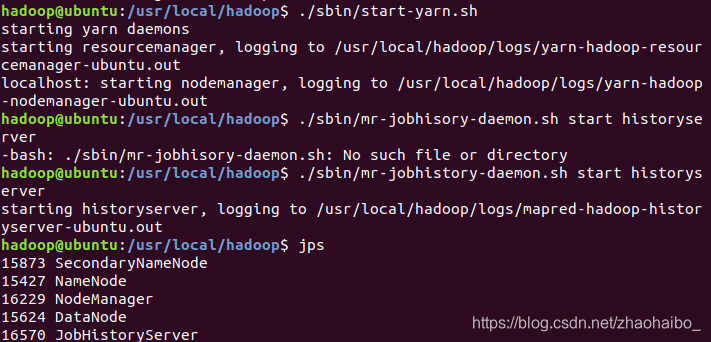
$ ./sbin/start-yarn.sh
$ ./sbin/mr-jobhistory-daemon.sh start historyserver
通過 jps ,多了 NodeManager 和 ResourceManager 兩個後臺程序
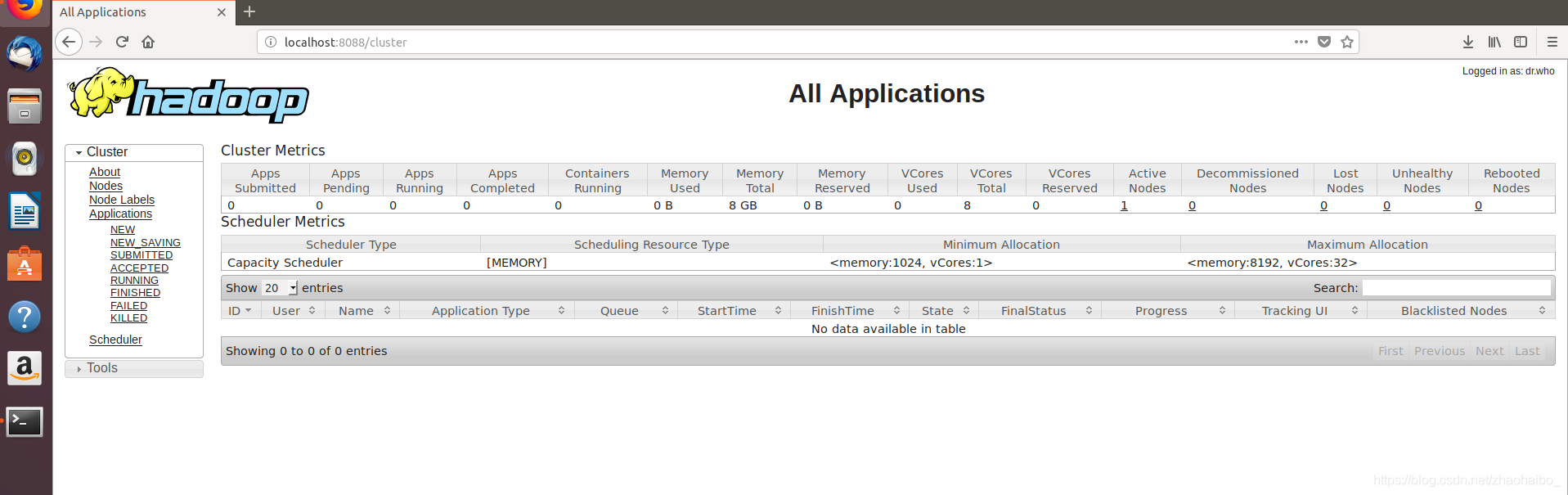
啟動 YARN 後可以通過localhost:8088.cluster 檢視任務的執行情況
關閉 YARN 的指令碼:
$ ./sbin/stop-yarn.sh
$ ./sbin/mr-jobhistory-daemon.sh stop historyserver
Hadoop執行例子
hadoop附帶很多例子,包括wordcount、join、grep、terasort等。執行 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar 可以看到所有例子
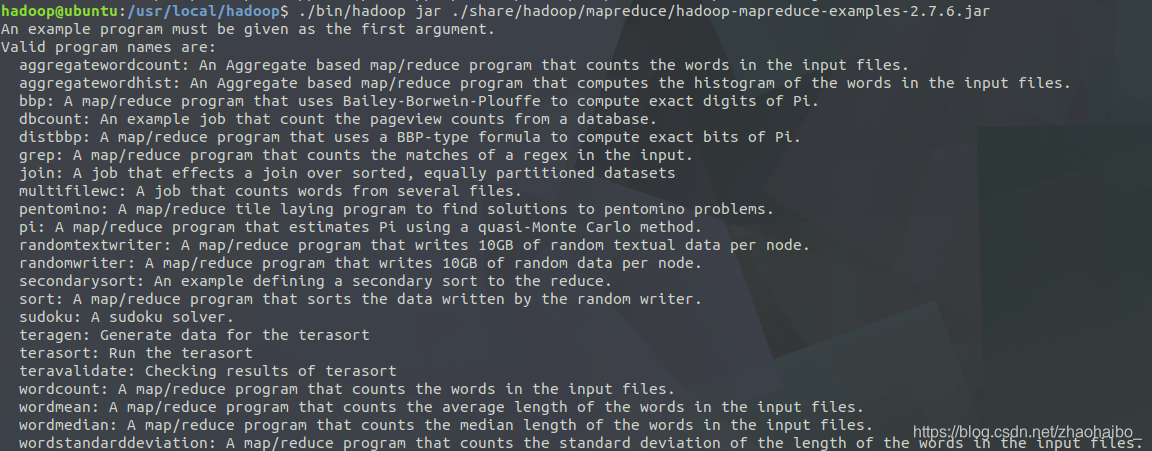
選擇執行 grep 例子,將 input 資料夾中的所有檔案作為輸入,篩選當中符合正則表示式 dfs[a-z.]+ 的單詞並統計出現的次數,最後輸出結果到 output 資料夾中。
$ cd /usr/local/hadoop
$ mkdir ./input
$ cp ./etc/hadoop/*.xml ./input # 將配置檔案作為輸入檔案
$ ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar grep ./input ./output 'dfs[a-z.]+'
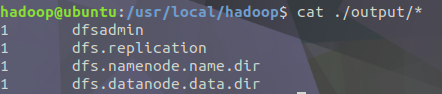
$ cat ./output/* # 檢視執行結果
執行後輸出了作業的相關資訊,輸出的結果是符合正則的單詞各出現了1次
注意,Hadoop 預設不會覆蓋結果檔案,因此再次執行上面例項會提示出錯,需要先將 ./output 刪除。
rm -r ./output
為Hadoop新增至環境變數
每一次啟動都要進入/usr/local/hadoop目錄,再執行sbin/hadoop(等同於執行 /usr/local/hadoop/sbin/hadoop),受之前為jdk新增至環境變數過程的啟發,在這裡希望將Hadoop新增至環境變數。
在~/.bashrc中加入:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
執行source ~/.bashrc使設定生效。
在任意目錄中都可以直接開啟Hadoop:start-dfs.sh;直接啟動YARN:start-yarn.sh;使用hdfs:如hdfs dfs -ls input檢視HDFS檔案。