
DRF -- Django REST framework
模型類序列化器相關用法可以參考: 模型類序列化器講解
在web開發過程中,有前後端分離和前後端不分離兩種情況;
- 前後端不分離:後端通過模板渲染/返回Json資料/重定向等方法,將後端的資料返回給前端;
- 前後端分離:後端僅需要返回前端所需要的資料,至於前端介面的資料如何獲取,或者html資料如何展示,後端是不需要再過問的;
前後端分離的應用模式的特點:
- 前後端分離情況下,前端和後端的耦合程度降低
- 在這種情況下,我們後端寫的檢視被稱為介面,也叫API,前端會根據訪問不同的介面對資料庫進行增刪改查的動作。
RESTful
所以在有些情況下,使用前後端分離的應用模式就顯得比較友好了;但是就像一千個讀者就有一千個哈姆雷特一樣。如果沒有一個相對的約束的話,那麼一千個程式設計師就會有一千零一個設計API的風格方式了,然後RESTful這樣一個設計理念就出現了。
Roy Thomas Fielding(提出REST的大牛)將他對網際網路軟體的架構原則,定名為REST,即Representational State Transfer的縮寫。維基百科稱其為“具象狀態傳輸”,國內大部分人理解為“表現層狀態轉化”。
RESTful是一種開發理念。維基百科說:REST是設計風格而不是標準。 REST描述的是在網路中client和server的一種互動形式;REST本身不實用,實用的是如何設計 RESTful API(REST風格的網路介面),一種全球資訊網軟體架構風格。
做個對比大家可能更能感受到它的魅力所在:
我們先來具體看下RESTful風格的url,比如我要查詢商品資訊,那麼
非REST的url:http://.../queryGoods?id=1001&type=t01
REST的url:http://.../t01/goods/1001
相對而言,是不是間接很多很多。
具體關於RESTful的資訊,有興趣的可以看一下
RESTful詳細介紹
DRF:
那麼說到這,Django中,我們想要實現REST的話,那麼Django REST framework就應運而生了。
Django REST framework 框架是一個用於構建Web API 的強大而又靈活的工具。
通常簡稱為DRF框架 或 REST framework。
特點:
- 提供了定義序列化器Serializer的方法,可以快速根據 Django ORM 或者其它庫自動序列化/反序列化;
- 提供了豐富的類檢視、Mixin擴充套件類,簡化檢視的編寫;
- 豐富的定製層級:函式檢視、類檢視、檢視集合到自動生成 API,滿足各種需要;
- 多種身份認證和許可權認證方式的支援;
- 內建了限流系統;
- 直觀的 API web 介面;
- 可擴充套件性,外掛豐富
安裝配置:
安裝和配置,在官方文件中都有詳細介紹,這裡只做簡單的記錄一下:
- 安裝: pip install djangorestframework
- 配置: 在INSTALL_APPS中增加 ‘rest_framework’
然後,現在開始實現一下它的強大之處。
Serializer 序列化
本文程式碼實現前提:我已經在子應用的models.py檔案中定義了幾個模型類
# 定義圖書模型類BookInfo
class BookInfo(models.Model):
btitle = models.CharField(max_length=20, verbose_name='名稱')
bpub_date = models.DateField(verbose_name='釋出日期')
bread = models.IntegerField(default=0, verbose_name='閱讀量')
bcomment = models.IntegerField(default=0, verbose_name='評論量')
is_delete = models.BooleanField(default=False, verbose_name='邏輯刪除')
image = models.ImageField(upload_to='booktest', verbose_name='圖片', null=True)
def __str__(self):
"""定義每個資料物件的顯示資訊"""
return self.btitle
#定義英雄模型類HeroInfo
class HeroInfo(models.Model):
GENDER_CHOICES = (
(0, 'male'),
(1, 'female')
)
hname = models.CharField(max_length=20, verbose_name='名稱')
hgender = models.SmallIntegerField(choices=GENDER_CHOICES, default=0, verbose_name='性別')
hcomment = models.CharField(max_length=200, null=True, verbose_name='描述資訊')
hbook = models.ForeignKey(BookInfo, on_delete=models.CASCADE, verbose_name='圖書') # 外來鍵
is_delete = models.BooleanField(default=False, verbose_name='邏輯刪除')
def __str__(self):
return self.hname
- Serializer定義:
①針對一個模型類建立一個對應的序列化器,我們的Serializer的定義是在子應用下新建立的一個serializer.py檔案中;
②序列化類是繼承於rest_framework.serializers.Serializer;
③serializer不是隻能為資料庫模型類定義,也可以為非資料庫模型類的資料定義。serializer是獨立於資料庫之外的存在。
# 為模型提供一個序列化器-- 書模型類提供序列化器
class BookInfoSerializer(serializers.Serializer):
id = serializers.IntegerField(label='ID', read_only=True)
btitle = serializers.CharField(label='名稱', max_length=20)
bpub_date = serializers.DateField(label='釋出日期', required=False)
bread = serializers.IntegerField(label='閱讀量', required=False)
bcomment = serializers.IntegerField(label='評論量', required=False)
image = serializers.ImageField(label='圖片', required=False)
同時,為了後面程式碼的實現,我們也給HeroInfo類提供一個序列化器:
# 為模型提供一個序列化器-- 英雄模型類提供序列化器
class HeroInfoSerializer(serializers.Serializer):
GENDER_CHOICES = (
(0, 'male'),
(1, 'female')
)
id = serializers.IntegerField(label='ID', read_only=True)
hname = serializers.CharField(label='名字', max_length=20)
hgender = serializers.ChoiceField(choices=GENDER_CHOICES, label='性別', required=False)
hcomment = serializers.CharField(label='描述資訊', max_length=200, required=False, allow_null=True)
- Serializer物件的建立
定義好Serializer類後,就可以建立Serializer物件了。
Serializer的構造方法為:
Serializer(instance=None, data=empty, **kwarg)
說明:
1)用於序列化時,將模型類物件傳入instance引數
2)用於反序列化時,將要被反序列化的資料傳入data引數
3)除了instance和data引數外,在構造Serializer物件時,還可通過context引數額外新增資料,如
serializer = AccountSerializer(account, context={‘request’: request})
通過context引數附加的資料,可以通過Serializer物件的context屬性獲取
- 序列化的基本使用
1)先獲得一個書籍物件
In [9]: from testfile.models import BookInfo, HeroInfo
In [10]: book = BookInfo.objects.get(id=1)
In [11]: book
Out[11]: <BookInfo: 西遊記>
2)建立序列化物件
from testfile.serializers import BookInfoSerializer, HeroInfoSerializer
n [12]: s = BookInfoSerializer(book)
3)獲取序列化資料
通過data屬性可以獲取序列化後的資料
In [13]: s.data
Out[13]: {'id': 1, 'bcomment': 10, 'bread': 10, 'image': None, 'heroinfo_set': [1, 2], 'btitle': '西遊記', 'bpub_date': '1988-01-01'}
4)如果要被序列化的是包含多條資料的查詢集QuerySet,可以通過新增many=True引數補充說明
In [20]: books = BookInfo.objects.all()
In [21]: books
Out[21]: <QuerySet [<BookInfo: 西遊記>, <BookInfo: 水滸傳>, <BookInfo: 繁星春水>, <BookInfo: 三國演義>, <BookInfo: 紅樓夢>, <BookInfo: 駱駝祥子>]>
In [22]: s = BookInfoSerializer(books, many=True)
In [23]: s.data
Out[23]: [OrderedDict([('id', 1), ('btitle', '西遊記'), ('bpub_date', '1988-01-01'), ('bread', 10), ('bcomment', 10), ('image', None('heroinfo_set', [1, 2])]), OrderedDict([('id', 2), ('btitle', '水滸傳'), ('bpub_date', '1988-09-09'), ('bread', 0), ('bcomment', 0)'image', None), ('heroinfo_set', [3, 4])]), OrderedDict([('id', 3), ('btitle', '繁星春水'), ('bpub_date', '1995-01-24'), ('bread', 3('bcomment', 5), ('image', None), ('heroinfo_set', [])]), OrderedDict([('id', 4), ('btitle', '三國演義'), ('bpub_date', '1978-05-07''bread', 6), ('bcomment', 33), ('image', None), ('heroinfo_set', [5])]), OrderedDict([('id', 5), ('btitle', '紅樓夢'), ('bpub_date',017-09-02'), ('bread', 9), ('bcomment', 14), ('image', 'booktest/cat.jpg'), ('heroinfo_set', [6, 7])]), OrderedDict([('id', 6), ('btitle', '駱駝祥子'), ('bpub_date', '1987-11-13'), ('bread', 9), ('bcomment', 4), ('image', None), ('heroinfo_set', [])])]
- 序列化的使用–關聯物件巢狀:
如果需要序列化的資料中包含其他關聯物件,則對關聯物件的序列化需要說明。
1) PrimaryKeyRelatedField – 該欄位將被序列化為關聯物件的主鍵
在HeroInfoSerializer中新增:
hbook = serializers.PrimaryKeyRelatedField(label=‘圖書’, read_only=True)
In [4]: hero = HeroInfo.objects.get(id=1)
In [5]: hero
Out[5]: <HeroInfo: 豬悟能>
In [6]: s = HeroInfoSerializer(hero)
In [7]: s.data
Out[7]: {'id': 1, 'hname': '豬悟能', 'hgender': 0, 'hbook': 1, 'hcomment': None}
這裡的外來鍵hbook顯示的就是關聯物件的主鍵 1
2) StringRelatedField – 該欄位將被序列化為關聯物件的字串表示方式(即__str__方法的返回值)
將1)中新增的資料刪除,在HeroInfoSerializer中新增:
hbook = serializers.StringRelatedField(label=‘圖書’) # 關聯物件的__str__顯示的資料資訊
In [4]: hero = HeroInfo.objects.get(id=2)
In [5]: hero
Out[5]: <HeroInfo: 孫悟空>
In [6]: s = HeroInfoSerializer(hero)
In [7]: s.data
Out[7]: {'hname': '孫悟空', 'hgender': 0, 'id': 2, 'hcomment': None, 'hbook': '西遊記'}
這裡顯示的就是關聯物件中定義__str__希望顯示的字串內容了,這裡顯示的是書籍對應的名稱。
3)使用關聯物件的序列化器 – 顧名思義,就是將外來鍵作為關聯物件的序列化器類的物件
將 2)中新增的資料刪除,在HeroInfoSerializer中新增:
hbook = BookInfoSerializer()
In [4]: hero = HeroInfo.objects.get(id=3)
In [5]: hero
Out[5]: <HeroInfo: 武松>
In [6]: s = HeroInfoSerializer(hero)
In [7]: s.data
Out[7]: {'hgender': 0, 'hname': '武松', 'hbook': OrderedDict([('id', 2), ('btitle', '水滸傳'), ('bpub_date', '1988-09-09'), ('bread' ('bcomment', 0), ('image', None), ('heroinfo_set', [3, 4])]), 'hcomment': '醉拳', 'id': 3}
這裡資料的顯示就是外來鍵對應的序列化後的資料了。
4)還有其他幾個方法,這裡列出來,但是不做相關演示了。
①HyperlinkedRelatedField
此欄位將被序列化為獲取關聯物件資料的介面連結
②SlugRelatedField
此欄位將被序列化為關聯物件的指定欄位資料
③ 重寫to_representation方法
序列化器的每個欄位實際都是由該欄位型別的to_representation方法決定格式的,可以通過重寫該方法來決定格式。
注意,to_representations方法不僅侷限在控制關聯物件格式上,適用於各個序列化器欄位型別。
- many引數
如果關聯的物件資料不是隻有一個,而是包含多個數據,如想序列化圖書BookInfo資料,每個BookInfo物件關聯的英雄HeroInfo物件可能有多個,此時關聯欄位型別的指明仍可使用上述幾種方式,只是在宣告關聯欄位時,多補充一個many=True引數即可。
在BookInfoSerializer中新增:
heroinfo_set = serializers.PrimaryKeyRelatedField(label=‘英雄’, read_only=True, many=True)
In [4]: book = BookInfo.objects.get(id=2)
In [5]: book
Out[5]: <BookInfo: 水滸傳>
In [6]: s = BookInfoSerializer(book)
In [7]: s.data
Out[7]: {'bcomment': 0, 'bpub_date': '1988-09-09', 'id': 2, 'btitle': '水滸傳', 'image': None, 'heroinfo_set': [3, 4], 'bread': 0}
欄位與型別
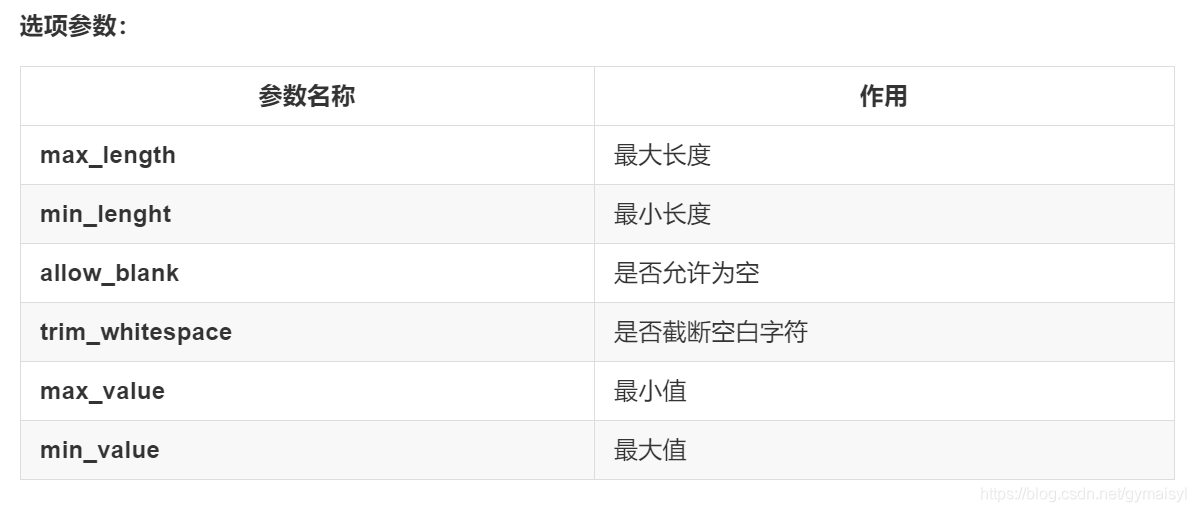
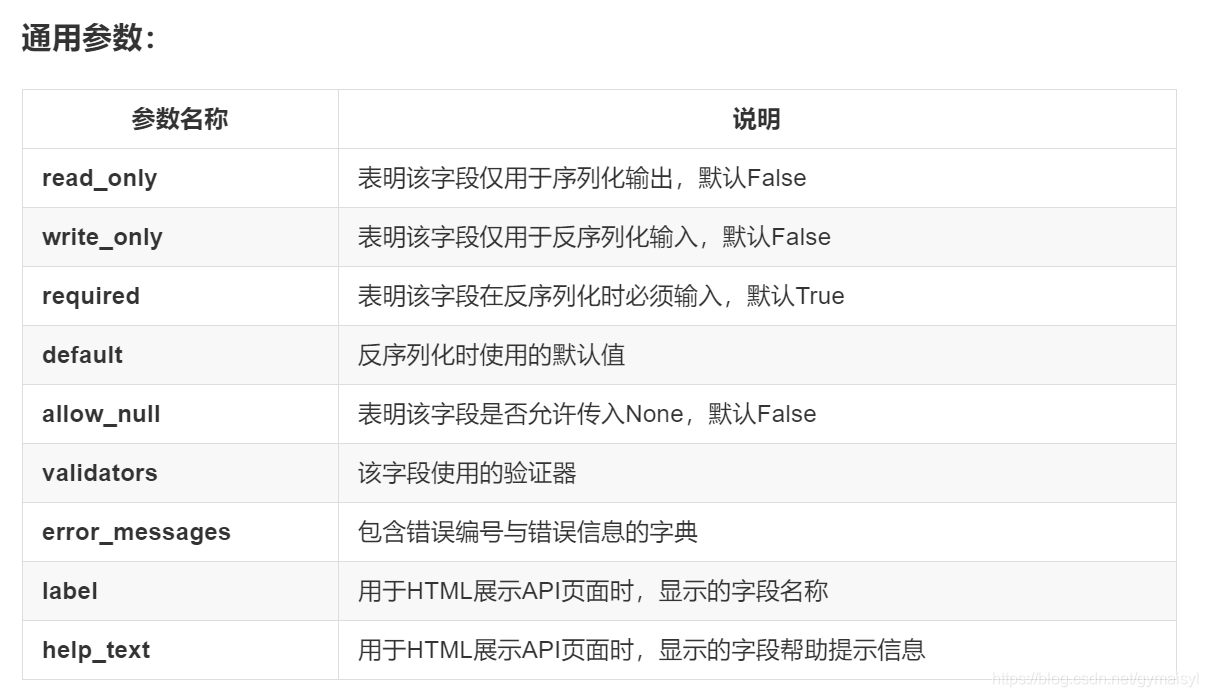
反序列化
反序列化的使用,包括兩部分:
一:資料校驗
二:反序列化
- 資料校驗
使用序列化器對資料進行反序列化之前,必須要對資料進行校驗,資料的校驗又可以分為:
1)序列化器自帶的檢驗方法
2)自定義校驗方法
①自定義的校驗方法:is_valid()
在獲得反序列資料之前,需要通過is_valid()進行對資料的校驗,驗證成功返回True,驗證不成功返回False。
例1:False案例
In [4]: s = BookInfoSerializer(data=data)
In [8]: data = {}
In [9]: s = BookInfoSerializer(data=data)
In [10]: s.is_valid()
Out[10]: False
當然,關於錯誤資訊,我們是可以通過 errors 獲取屬性的錯誤資訊,資訊內容包括欄位和欄位的錯誤;
非欄位的錯誤,可以通過修改REST framework配置中的NON_FIELD_ERRORS_KEY來控制錯誤字典中的鍵名。
In [11]: s.errors
Out[11]: {'btitle': [ErrorDetail(string='This field is required.', code='required')]}
例2:True案例
對於驗證成功的資料,我們可以通過 validated_data 獲取到,這個和之前的序列化不一樣,序列化是通過data獲得序列化後的資料的。
In [13]: data = {'btitle': 'python'}
In [14]: s = BookInfoSerializer(data=data)
In [15]: s.is_valid()
Out[15]: True
In [16]: s.errors
Out[16]: {}
In [17]: s.validated_data
Out[17]: OrderedDict([('btitle', 'python')])
例3:錯誤丟擲案例
is_valid()方法還可以在驗證失敗時丟擲異常serializers.ValidationError,可以通過傳遞 raise_exception=True 引數開啟,REST framework接收到此異常,會向前端返回HTTP 400 Bad Request響應;
In [19]: data = {}
In [20]: s = BookInfoSerializer(data=data)
In [21]: s.is_valid(raise_exception=True)
ValidationError: {'btitle': [ErrorDetail(string='This field is required.', code='required')]}
②自定義驗證
1) validate_<filed_name> : 針對單一欄位增加驗證要求
在對應的序列化器中新增自定義驗證
例1:在BookInfoSerializer序列化器中新增下面的程式碼
def validate_btitle(self, value):
if 'python' not in value.lower():
raise serializers.ValidationError('引數不是我想要的')
return value
ipython中執行的結果
In [4]: data = {'btitle': 'pythons'}
In [5]: s = BookInfoSerializer(data=data)
In [6]: s.is_valid()
Out[6]: True
In [7]: s.validated_data
Out[7]: OrderedDict([('btitle', 'pythons')])
In [8]: data = {'btitle': 'django'}
In [9]: s = BookInfoSerializer(data=data)
In [10]: s.is_valid()
Out[10]: False
In [11]: s.errors
Out[11]: {'btitle': [ErrorDetail(string='引數不是我想要的', code='invalid')]}
2)valildate :多個欄位之間的比較驗證
在BookInfoSerializer序列化器中新增下面的程式碼
def validate(self, attrs):
bread = attrs['bread']
bcomment = attrs['bcomment']
if bread < bcomment:
raise serializers.ValidationError('我需要閱讀量比評論量大的資料,你不符合')
執行過程和結果如下:
In [6]: data = {'btitle': 'python02', 'bread': 30, 'bcomment':50}
In [7]: s = BookInfoSerializer(data=data)
In [8]: s.is_valid()
Out[8]: False
In [9]: s.errors
Out[9]: {'non_field_errors': [ErrorDetail(string='我需要閱讀量比評論量大的資料,你不符合', code='invalid')]}
這裡丟擲的錯誤內容不是欄位的錯誤資訊,也就是非欄位的錯誤資訊,所以我們的errors中獲取到的是 ‘non_field_errors’,如果希望顯示結果不是這個,是可以在test_frame的配飾中進行修改的。
3)validators : 在欄位中新增validators選項引數,具體的驗證要求,可以在序列化器外面進行函式定義。
在BookInfoSerializer序列化器外面定義一個validators函式,並把
序列化器中的validate_btitle刪除;
def about_python(value):
if 'python' not in value.lower():
raise serializers.ValidationError('引數不是我想要的')
序列化器中的btitle欄位新增一個引數:
btitle = serializers.CharField(label='名稱', max_length=20, validators=[about_python])
執行過程和結果如下:
In [4]: data = {'btitle': 'django', 'bread': 30, 'bcomment':50}
In [5]: s = BookInfoSerializer(data=data)
In [6]: s.is_valid()
Out[6]: False
In [7]: s.errors
Out[7]: {'btitle': [ErrorDetail(string='引數不是我想要的', code='invalid')]}
validators 的總結:
(1):在序列化器外面進行定義,然後再欄位裡面新增這個驗證的引數;
(2):validators的作用和 validate_<filed_name> 差不多,只不過一個是再序列化器內部進行定義,只是針對這一個序列化器使用;而validators定義是在序列化器外面的,所以的其他的序列化器也可以使用。
(3)validators這個函式和 validate_<filed_name> 不同的是,validators如果驗證成功的話,是不需要return的,只是在驗證失敗的時候,會丟擲異常。
當然,validators在DRF中是有提供的,上面的是我們自定義的:
(1)UniqueValidator
單欄位唯一,如:
from rest_framework.validators import UniqueValidator
slug = SlugField(
max_length=100,
validators=[UniqueValidator(queryset=BlogPost.objects.all())]
)
(2)UniqueTogetherValidation
聯合唯一,如:
from rest_framework.validators import UniqueTogetherValidator
class ExampleSerializer(serializers.Serializer):
# …
class Meta:
validators = [
UniqueTogetherValidator(
queryset=ToDoItem.objects.all(),
fields=(‘list’, ‘position’)
)
]
- 反序列化–儲存
1)在進行序列化驗證之後,我們就可以基於validated_data完成資料物件的建立,可以通過實現create()和update()兩個方法來實現。
我們在序列化器中新增兩個函式 create()和 update()
def create(self, validated_data):
"""新建"""
return BookInfo(**validated_data)
def update(self, instance, validated_data):
"""更新,instance為要更新的物件例項"""
instance.btitle = validated_data.get('btitle', instance.btitle)
instance.bpub_date = validated_data.get('bpub_date', instance.bpub_date)
instance.bread = validated_data.get('bread', instance.bread)
instance.bcomment = validated_data.get('bcomment', instance.bcomment)
return instance
我們需要進行資料物件的建立,我們可以使用s.save() ,但是又如如何判斷什麼時候呼叫create,什麼時候呼叫update呢,那就得看我們在建立序列化物件的時候,傳遞的引數了。
簡單來說:
如果 instance 有值,那麼就是存在模型物件,那麼我們再傳遞data引數的時候,我們就會呼叫update,來進行資料的更新。
反之,如果沒有 instance , 或者沒有給它傳值,那麼我們就會呼叫 create() , 進行資料的建立。
2)當然,我們上面只是進行模型物件的建立,我們還需要將資料儲存到資料庫中,我們可以直接在函式中直接將資料新增到資料庫就可以了。
def create(self, validated_data):
"""新建"""
return BookInfo.objects.create(**validated_data)
def update(self, instance, validated_data):
"""更新,instance為要更新的物件例項"""
instance.btitle = validated_data.get('btitle', instance.btitle)
instance.bpub_date = validated_data.get('bpub_date', instance.bpub_date)
instance.bread = validated_data.get('bread', instance.bread)
instance.bcomment = validated_data.get('bcomment', instance.bcomment)
instance.save()
return instance
說明:
1)save()呼叫的時候,也可以進行引數傳遞,傳遞的引數,可以在create() / update() 中獲取到。
2)我們在進行資料的更新的時候,只會把需要更新的資料部分傳遞進來,但是,如果在沒有傳遞的欄位中,是required=True,必須傳遞,那麼應該如何解決呢?
很簡單,我們可以在建立序列化物件的時候,將partial=True寫在後面,這樣就允許部分資料的更新了。
s = BookInfoSerializer(book, data={'btitle: 'python' , partial=True)