
GAN(二):VAE-GAN,BiGAN
阿新 • • 發佈:2018-11-25
一、VAE-GAN簡介
下圖展示了VAE-GAN的大體框架。
所謂“人如其名”,在給gan命名的時候也是如此。VAE-GAN就是VAE和GAN的結合體。
VAE:包含encoder和decoder兩部分。
- encoder的作用是編碼,也就是將輸入的圖片image1轉換成向量vector
- decoder的作用是解碼,也就是將向量vector轉換成圖片image2
其中,image1和image2要儘量相同,原因是我們希望對同一個東西進行編解碼後的產物仍然是自己。
GAN:包含generator和discriminator - generator:就是VAE的decoder,將向量vector轉化為image
- discriminator: 評判generator產生的image是realistic還是fake,給出一個scalar(分數或者可能性或者二分類結果)

下面說一下演算法的大致運作流程:
- 初始化encoder,decoder,discriminator(其實就是三個神經網路)
- 迭代更新:
·從database中隨機取樣,x1,x2,xM
·x1,x2,xM輸入到encoder中,產生z’ = En(x)
·將z’1,z’2,z’M輸入到decoder中,產生x’=De(z’)
·從某個分佈(如均勻分佈,高斯分佈等)取樣z1,z2,zM
·將z1,z2,zM輸入到decoder中,產生x*=De(z)
(注意,下面這張圖此處公式有誤,遵循文字敘述)
·最後,按照下圖中的式子更新encoder,decoder,discriminator
現在,用通俗的語言來敘述一下更新的理由,方便各位讀者理解:
encoder和decoder合起來的目標是:一張圖片編解碼之後儘量保持原樣。因此,
encoder的更新準則是:編解碼前後圖片的方差儘可能小;編碼前圖片的分佈和解碼後圖片的分佈儘可能一致(分佈用KL散度描述);
decoder的更新準則是:編解碼前後圖片的方差儘可能小;解碼後的圖片得分儘量高,reconstructed產生的圖片的得分也儘量高
discriminator的更新準則是:要儘量能區分generator,reconstructed和realistic的圖片;因此對於原始影象的得分要儘量高,對於generator,reconstructed的圖片的得分要儘量低。
注意:上面的圖片有三種情況:1)原始圖片(分佈在database中,realistic) 2)原始圖片經過編解碼之後產生的圖片(generator) 3)從某個分佈中隨機取樣得到z,輸入解碼器中獲得的圖片(reconstructed)

二、BiGAN簡介
之前我們所遇到的auto-encoder都是這樣的結構:image1輸入到encoder中,產生輸出vector,這個vector在輸入到decoder中產生image2,然後最小化||image1-image2||
現在,我們換個思路,encoder和decoder將不再連線在一起,而是各自為政,加上一個discriminator後,就成了BiGAN。這種網路框架的思路如下:
- 輸入image x(x是realistic的image),經過編碼得到code z
- 從某個分佈(這個分佈可以是任意的,如高斯分佈等)中取樣z,經過解碼得到image x
- 通過上述兩步,我們可以得到一系列(x,z),這些(x,z)有的是encoder產生的,有的是decoder產生的,將這些(x,z)輸入到discriminator中,讓它判斷是encoder產生的還是decoder產生的;如果discriminator不能準確判斷,那麼就成功了。
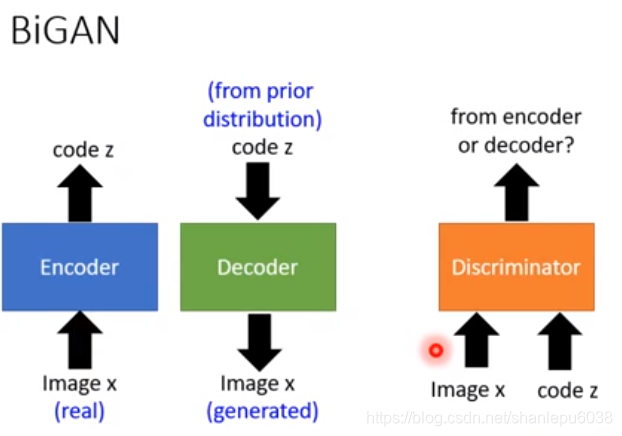
按照慣例,下面講一下具體的演算法流程:
- 初始化encoder,decoder,discriminator(就是三個獨立的神經網路)
- 依次迭代:
·從database中取樣x1,x2,xM
·將x1,x2,xM輸入到encoder中,產生輸出z = En(x)
·從某個分佈中取樣z’1,z’2,z’M
·將z’1,z’2,z’M輸入到decoder中,產生輸出 x’ = De(z)
·將(x,z)輸入到discriminator中,並更新discriminator(其中一種方式是增加Dis(x,z)的得分,降低Dis(x’,z’)的得分;也可以完全倒過來,無關緊要,因為這裡實質上是一個二分類問題,你把那個作為正例都無所謂)
·更新encoder和decoder(其中一種方式是降低Dis(x,z),增加Dis(x’,z’)。注意:這裡要和上面更新discriminator的方式相反。因為encode和decoderr做的事情是要儘量迷惑discriminator,所以上一步要降低Dis(x’,z’),這裡我們也要降低Dis(x,z),以此來達到一個平衡,不知道我說清楚沒有~~~)

那麼,說到這裡之後,我們就需要考慮一個問題了:如果encoder和decoder能達到一個平衡,那麼還需要discriminator嗎?
答案是顯然的。理想狀態即optimal encoder and decoder 的數學表達如下,如果能達到完全理想的狀態的話,確實不需要discriminator;而現實是,我們不可能達到理想狀態,這也就是為什麼auto-encoder模型產生的圖片都很模糊的原因了。正是因為不能達到理想狀態,所以我們需要discriminator的存在
