
樸素貝葉斯進行新聞主題分類,有程式碼和資料,可以跑通
阿新 • • 發佈:2018-11-25
folder_path = '/Users/apple/Documents/七月線上/NLP/第2課/Lecture_2/Naive-Bayes-Text-Classifier/Database/SogouC/Sample'
stopwords_file = '/Users/apple/Documents/七月線上/NLP/第2課/Lecture_2/Naive-Bayes-Text-Classifier/stopwords_cn.txt'
下載地址:連結:https://pan.baidu.com/s/1O5mW04PlulaCW5TUd93OUg 密碼:ubkq
然後切換Python2.7,跑下面程式碼就可以進行自然語言入門了
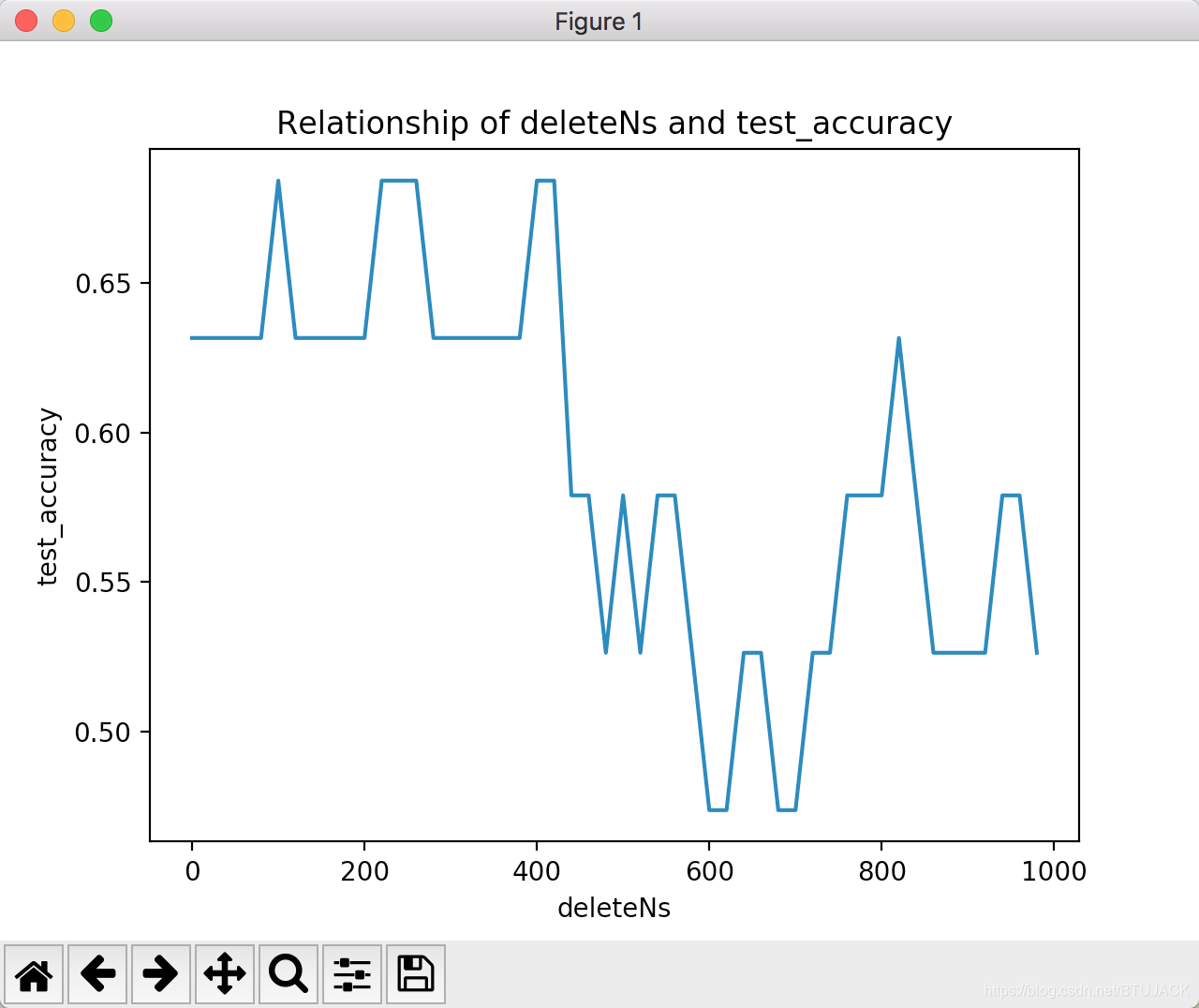
#coding: utf-8 #python 2.7 執行正確 ''' 經典的新聞主題分類,用樸素貝葉斯做。 #2018-06-10 June Sunday the 23 week, the 161 day SZ 資料來源:連結:https://pan.baidu.com/s/1_w7wOzNkUEaq3KAGco19EQ 密碼:87o0 樸素貝葉斯與應用 文字分類問題 經典的新聞主題分類,用樸素貝葉斯做。 樸素貝葉斯進行文字分類的基本思路是先區分好訓練集與測試集,對文字集合進行分詞、去除標點符號等特徵預處理的操作,然後使用條件獨立假設, 將原概率轉換成詞概率乘積,再進行後續的處理。 貝葉斯公式 + 條件獨立假設 = 樸素貝葉斯方法 基於對重複詞語在訓練階段與判斷(測試)階段的三種不同處理方式,我們相應的有伯努利模型、多項式模型和混合模型。 在訓練階段,如果樣本集合太小導致某些詞語並未出現,我們可以採用平滑技術對其概率給一個估計值。 而且並不是所有的詞語都需要統計,我們可以按相應的“停用詞”和“關鍵詞”對模型進行進一步簡化,提高訓練和判斷速度。 ''' import os import time import random import jieba #處理中文 #import nltk #處理英文 import sklearn from sklearn.naive_bayes import MultinomialNB import numpy as np import pylab as pl import matplotlib.pyplot as plt #粗暴的詞去重 def make_word_set(words_file): words_set = set() with open(words_file, 'r') as fp: for line in fp.readlines(): word = line.strip().decode("utf-8") if len(word)>0 and word not in words_set: # 去重 words_set.add(word) return words_set # 文字處理,也就是樣本生成過程 def text_processing(folder_path, test_size=0.2): folder_list = os.listdir(folder_path) data_list = [] class_list = [] # 遍歷資料夾 for folder in folder_list: new_folder_path = os.path.join(folder_path, folder) files = os.listdir(new_folder_path) # 讀取檔案 j = 1 for file in files: if j > 100: # 怕記憶體爆掉,只取100個樣本檔案,你可以註釋掉取完 break with open(os.path.join(new_folder_path, file), 'r') as fp: raw = fp.read() ## 是的,隨處可見的jieba中文分詞 jieba.enable_parallel(4) # 開啟並行分詞模式,引數為並行程序數,不支援windows word_cut = jieba.cut(raw, cut_all=False) # 精確模式,返回的結構是一個可迭代的genertor word_list = list(word_cut) # genertor轉化為list,每個詞unicode格式 jieba.disable_parallel() # 關閉並行分詞模式 data_list.append(word_list) #訓練集list class_list.append(folder.decode('utf-8')) #類別 j += 1 ## 粗暴地劃分訓練集和測試集 data_class_list = zip(data_list, class_list) random.shuffle(data_class_list) index = int(len(data_class_list)*test_size)+1 train_list = data_class_list[index:] test_list = data_class_list[:index] train_data_list, train_class_list = zip(*train_list) test_data_list, test_class_list = zip(*test_list) #其實可以用sklearn自帶的部分做 #train_data_list, test_data_list, train_class_list, test_class_list = sklearn.cross_validation.train_test_split(data_list, class_list, test_size=test_size) # 統計詞頻放入all_words_dict all_words_dict = {} for word_list in train_data_list: for word in word_list: if all_words_dict.has_key(word): all_words_dict[word] += 1 else: all_words_dict[word] = 1 # key函式利用詞頻進行降序排序 all_words_tuple_list = sorted(all_words_dict.items(), key=lambda f:f[1], reverse=True) # 內建函式sorted引數需為list all_words_list = list(zip(*all_words_tuple_list)[0]) return all_words_list, train_data_list, test_data_list, train_class_list, test_class_list def words_dict(all_words_list, deleteN, stopwords_set=set()): # 選取特徵詞 feature_words = [] n = 1 for t in range(deleteN, len(all_words_list), 1): if n > 1000: # feature_words的維度1000 break if not all_words_list[t].isdigit() and all_words_list[t] not in stopwords_set and 1<len(all_words_list[t])<5: feature_words.append(all_words_list[t]) n += 1 return feature_words # 文字特徵 def text_features(train_data_list, test_data_list, feature_words, flag='nltk'): def text_features(text, feature_words): text_words = set(text) ## ----------------------------------------------------------------------------------- if flag == 'nltk': ## nltk特徵 dict features = {word:1 if word in text_words else 0 for word in feature_words} elif flag == 'sklearn': ## sklearn特徵 list features = [1 if word in text_words else 0 for word in feature_words] else: features = [] ## ----------------------------------------------------------------------------------- return features train_feature_list = [text_features(text, feature_words) for text in train_data_list] test_feature_list = [text_features(text, feature_words) for text in test_data_list] return train_feature_list, test_feature_list # 分類,同時輸出準確率等 def text_classifier(train_feature_list, test_feature_list, train_class_list, test_class_list, flag='nltk'): ## ----------------------------------------------------------------------------------- if flag == 'nltk': ## 使用nltk分類器 train_flist = zip(train_feature_list, train_class_list) test_flist = zip(test_feature_list, test_class_list) classifier = nltk.classify.NaiveBayesClassifier.train(train_flist) test_accuracy = nltk.classify.accuracy(classifier, test_flist) elif flag == 'sklearn': ## sklearn分類器 classifier = MultinomialNB().fit(train_feature_list, train_class_list) test_accuracy = classifier.score(test_feature_list, test_class_list) else: test_accuracy = [] return test_accuracy print "start" ## 文字預處理 folder_path = '/Users/apple/Documents/七月線上/NLP/第2課/Lecture_2/Naive-Bayes-Text-Classifier/Database/SogouC/Sample' all_words_list, train_data_list, test_data_list, train_class_list, test_class_list = text_processing(folder_path,test_size=0.2) # 生成stopwords_set stopwords_file = '/Users/apple/Documents/七月線上/NLP/第2課/Lecture_2/Naive-Bayes-Text-Classifier/stopwords_cn.txt' stopwords_set = make_word_set(stopwords_file) ## 文字特徵提取和分類 # flag = 'nltk' flag = 'sklearn' deleteNs = range(0, 1000, 20) test_accuracy_list = [] for deleteN in deleteNs: # feature_words = words_dict(all_words_list, deleteN) feature_words = words_dict(all_words_list, deleteN, stopwords_set) train_feature_list, test_feature_list = text_features(train_data_list, test_data_list, feature_words, flag) test_accuracy = text_classifier(train_feature_list, test_feature_list, train_class_list, test_class_list, flag) test_accuracy_list.append(test_accuracy) print test_accuracy_list # 結果評價 #plt.figure() plt.plot(deleteNs, test_accuracy_list) plt.title('Relationship of deleteNs and test_accuracy') plt.xlabel('deleteNs') plt.ylabel('test_accuracy') plt.show() #plt.savefig('result.png') print "finished" ''' 輸出 start Building prefix dict from the default dictionary ... Loading model from cache /var/folders/4k/5k587rhs73n7z73g0ssc81km0000gn/T/jieba.cache Loading model cost 0.364 seconds. Prefix dict has been built succesfully. [0.5263157894736842, 0.5263157894736842, 0.47368421052631576, 0.47368421052631576, 0.47368421052631576, 0.47368421052631576, 0.5263157894736842, 0.5789473684210527, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.47368421052631576, 0.47368421052631576, 0.47368421052631576, 0.47368421052631576, 0.47368421052631576, 0.47368421052631576, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.5263157894736842, 0.47368421052631576, 0.42105263157894735, 0.42105263157894735, 0.42105263157894735, 0.42105263157894735, 0.3684210526315789, 0.3684210526315789, 0.3684210526315789, 0.3684210526315789, 0.3684210526315789, 0.3684210526315789, 0.42105263157894735, 0.42105263157894735, 0.42105263157894735, 0.47368421052631576, 0.42105263157894735, 0.47368421052631576, 0.47368421052631576, 0.47368421052631576, 0.42105263157894735, 0.47368421052631576, 0.47368421052631576, 0.5263157894736842] '''
輸出影象:
認識你是我們的緣分,同學,等等,學習人工智慧,記得關注我。
微信掃一掃
關注該公眾號
《灣區人工智慧》
回覆《人生苦短,我用Python》便可以獲取下面的超高清電子書和程式碼
