
機器學習-如何有效使用機器學習演算法
怎麼改進演算法
當使用訓練好的模型時,新樣本輸出的資料產生了巨大的誤差,如何改進演算法的效能。
- 使用更多的訓練樣本,但通常來講並沒有什麼卵用
- 嘗試選用更少的特徵集,來防止過擬合
- 或許也需要更多的特徵集,當目前的特徵集對你沒有多大用處時,可以從更多的特徵角度去收集更多的特徵
- 增加多項式特徵
- 減小正則化中的 的值
- 增大正則化中的 的值
我們不應該隨機選擇上面的某種方法來改進我們的演算法,而是運用一些機器學習診斷法來幫助我們知道上面哪些方法對我們的演算法是有效的。
怎麼評估演算法的效能(機器學習診斷法[machine learning diagnostics])
“診斷法”的意思是:這是一種測試法,你通過執行這種測試,能夠深入瞭解某種演算法到底是否有用。這通常也能夠告訴你,要想改進一種演算法的效果,什麼樣的嘗試,才是有意義的。
標準方法
-
將所有資料按照 7:3 的比例分成訓練集和測試集,使用 表示測試集資料。
如果所有的資料存在規律或順序,最好先打亂順序再按比例分割。
-
測試集評估在通過訓練集讓我們的模型學習得出其引數後,對測試集運用該模型,我們有兩種方式計算測試集誤差:
-
對於線性迴歸模型,我們利用測試集資料計算代價函式
-
對於邏輯迴歸模型,我們除了可以利用測試資料集來計算代價函式外:
誤分類的比率,對於每一個測試集樣本,計算:
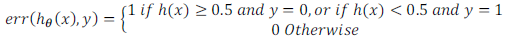
-
然後對計算結果求平均。
怎麼選擇模型
通過交叉驗證,選擇能最好的擬合數據的多項式次數的模型
-
定義多個模型,每個模型的次數不同,使用 表示模型的多項式最高次數。
-
將所有資料按照 6:2:2 的比例分成訓練集、交叉驗證集和測試集,使用 表示驗證集資料,使用 表示測試集資料。
如果所有的資料存在規律或順序,最好先打亂順序再按比例分割。
表示驗證集總數, 表示測試集總數。
同樣的,我們能夠定義訓練集誤差 、驗證集誤差 、測試集誤差
-
使用訓練集代入所有模型並通過訓練使得最終代價函式 最小,再使用驗證集代入訓練後的所有模型來算出 ,選出能最好的對交叉驗證集進行預測的模型( 最小的模型),確定最終模型的最高次數 。
-
使用測試集,預測或估計,通過學習演算法得出的模型的泛化誤差。
最好按比例分出三份不一樣的資料,如果只分為兩份,讓其中一份既作為驗證集又作為測試集,並不好。
模型出現問題,是欠擬合還是過擬合
- 偏差比較大(欠擬合)
- 方差比較大(過擬合)
高偏差(欠擬合): 當 訓練集資料 和 驗證集資料 出現的誤差都很大時,且兩個誤差可能很接近或者可能驗證誤差稍大一點。
高方差(過擬合): 當 訓練集資料 出現的誤差很小, 驗證集資料 出現的誤差很大時,且
誤差即 遠大於
如何選取正則化引數
之前通過交叉驗證後我們已經選擇了一個合適的模型,但是我們還沒有正則化項。
這次我們仍然通過交叉驗證,來進行選擇一個合適的正則化引數 。
-
定義多個正則化引數 ,每個模型的 不同。
-
將所有資料按照 6:2:2 的比例分成訓練集、交叉驗證集和測試集,使用 表示驗證集資料,使用 表示測試集資料。
如果所有的資料存在規律或順序,最好先打亂順序再按比例分割。
表示驗證集總數,