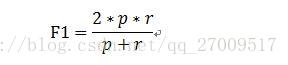基於機器學習的文字分類演算法的研究
1. 簡述
文字分類的方法屬於有監督的學習方法,分類過程包括文字預處理、特徵抽取、降維、分類和模型評價。本文首先研究了文字分類的背景,中文分詞演算法。然後是對各種各樣的特徵抽取進行研究,包括詞項頻率-逆文件頻率和word2vec,降維方法有主成分分析法和潛在索引分析,最後是對分類演算法進行研究,包括樸素貝葉斯的多變數貝努利模型和多項式模型,支援向量機和深度學習方法。深度學習方法包括多層感知機,卷積神經網路和迴圈神經網路。
2. 背景
目前,人工智慧發展迅猛,在多個領域取得了巨大的成就,比如自然語言處理,影象處理,資料探勘等。文字挖掘是其中的一個研究方向。根據維基百科的定義,文字挖掘也叫文字資料探勘,或是文字分析,是從文字中獲取高質量資訊的過程,典型的任務有文字分類、自動問答、情感分析、機器翻譯等。文字分類是將資料分成預先定義好的類別,一般流程為:1. 預處理,比如分詞,去掉停用詞;2. 文字表示及特徵選擇;3. 分類器構造;4. 分類器根據文字的特徵進行分類;5. 分類結果的評價。
由於近年來人工智慧的快速發展,文字分類技術已經可以很好的確定一個未知文件的類別,而且準確度也很好。藉助文字分類,可以方便進行海量資訊處理,節約大量的資訊處理費用。廣泛應用於過濾資訊,組織與管理資訊,數字圖書館、垃圾郵件過濾等社會生活的各個領域。
3. 文字分類的過程
文字分類(Text Classification)利用有監督或是無監督的機器學習方法對語料進行訓練,獲得一個分類模型,這個模型可以對未知類別的文件進行分類,得到預先定義好的一個或多個類別標籤,這個標籤就是這個文件的類別。

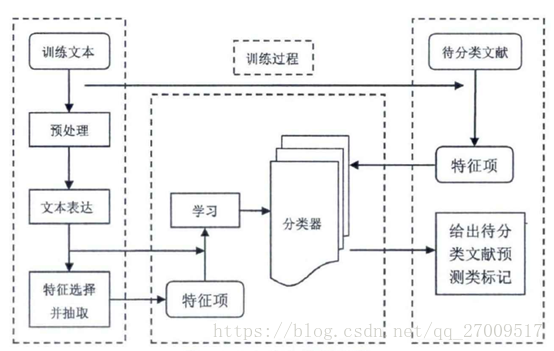
4. 預處理
本文處理的資料是文字,預處理是對文字資料進行處理,大都是非結構化的文字資訊。預處理就是去除沒用的資訊,同時把有用文字資訊用數字表示,這樣才可以為計算機處理。文字預處理主要包括分詞、去除停用詞和特殊符號。英文的基本單位是單詞,可以根據空格和標點符號進行分詞,然後再提取詞根和詞幹。中文的基本單位是字,需要一些演算法來進行分詞。現在主要的中文分詞方法有:
(1)基於字串匹配的分詞方法[2]
該方法是將待分詞的字串從頭或尾開始切分出子串,再與存有幾乎所有中文詞語的詞典匹配,若匹配成功,則子串是一個詞語。根據匹配位置的起點不同,分為正向最大匹配演算法(Forward Maximum Matching method,FMM)、逆向最大匹配演算法(Reverse Maximum Matching method,RMM)和雙向匹配演算法(Bi-direction Matching method,BM)。雙向匹配演算法利用了前兩者的優勢,有更好的效果。
(2)基於統計及機器學習的分詞方法[3]
主要有隱馬爾可夫模型(Hidden Markov Model,HMM)和條件隨機場(Conditional Random Field,CRF)。HMM假設任一時刻的狀態只依賴前一時刻的狀態和任意時刻的觀測值只與該時刻的狀態值有關。它是關於時序的概率圖模型,由一個不可觀測的狀態隨機序列,經過狀態轉移概率和發射概率生成觀測值的過程。如圖2.2所示,在分詞中,每個字(觀測值)都對應一個狀態,狀態集用B(詞開始)、E(詞的結束)、M(詞的中間)和S(單字成詞)表示,轉移矩陣(BEMS*BEMS)是狀態集裡的元素到其他元素的概率值大小,發射矩陣是從狀態到觀測的概率大小。最後用Viterbi演算法獲得一句話的最大概率的狀態,再根據狀態進行分詞。
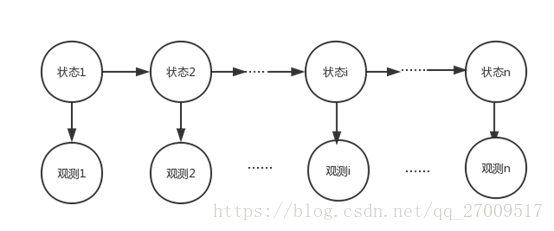
和隱馬爾科夫模型一樣,條件隨機場也是基於學習字的狀態來進行狀態分析,最後根據狀態分詞,但條件隨機場還利用了上下文的資訊,所以準確率高於隱馬爾可夫模型。
5. 特徵抽取和選擇
文件經過分詞和去除停用詞後,詞就表示文字的特徵項,所以訓練集中的全部特徵項構成的向量空間的維度相當高,能夠達到幾萬甚至幾十萬維,需要選擇和抽取重要的特徵。
文字經過預處理後,會得到一個一個的詞語,而中文的詞語的多種多樣的,造成維度很高的特徵向量,而且每個文件的維度不一定一致,給後面的分類產生影響。所以需要進行特徵選擇。
目前的特徵選擇演算法有好多,列舉以下幾種:
(1)詞項頻率-逆文件頻率(Term Frequency-Inverse Document Frequency,TF-IDF)
每個屬於文件d 的詞項t
的權重用公式2.2計算:
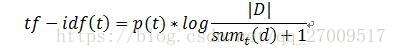
|D| 是文件集D 的文件個數,分母加1防止除數為零。在TF-IDF中詞項頻率(TF)用逆文件頻率(IDF)歸一化,這種歸一化降低了文件集裡詞項出現頻率大的權重,保證能夠區分文件的詞項有更大的權重,而這些詞項一般有比較低的頻率。
(2)互資訊(Mutual Information,MI)
互資訊測量的是兩個變數之間的相關程度,在文字分類中,計算的是特徵項t 和類別li
的相關程度,如公式2.3所示:
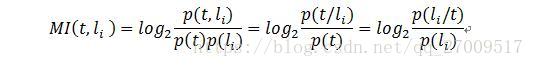
MI的值越大,相關度越高。在進行特徵選擇時,選擇高於某個閾值的k個特徵項作為表示這個文件的向量。
(3)CHI統計(CHI-square statistic)
CHI統計計算的是特徵項t 和類別
的相關程度,如公式2.4所示:

特徵選擇與MI一樣,他與MI的目的一樣,都是計算特徵項和類別的相關程度,只是計算公式不一樣。
常見的特徵提取方法有主成分分析,潛在語義索引,word2vec等。
(1)主成分分析(Principal Component Analysis ,PCA)
主成分分析通過線性變換,通常乘以空間中的一個基,將原始資料變換為一組各維度線性無關的矩陣,用於提取資料的主要特徵分量,常用於高維資料的降維。如公式2.5所示:
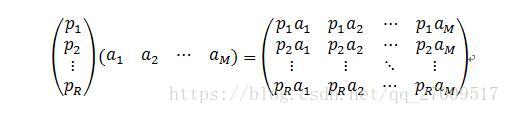

(2)潛在語義分析(Latent Semantic Analysis,LSA)[5]
又稱潛在語義索引(Latent Semantic Indexing,LSI),本質上是把高維的詞頻矩陣進行降維,降維方法是用奇異值分解(Singular Value Decomposition, SVD),假設詞-文件矩陣如2.7所示:

(3)word2vec
word2vec的作用是將由one-hot編碼獲得的高維向量轉換為低維的連續值向量,也就是稠密向量,又稱分散式表示,可以很好的度量詞與詞之間的相似性,是一個淺層的神經網路,用的是CBoW模型和skip-gram模型。而奠定word2vec基礎的是用神經網路建立統計語言模型的神經網路語言模型[10](Neural Network Language Model, NNLM),整個模型如下圖2.3:
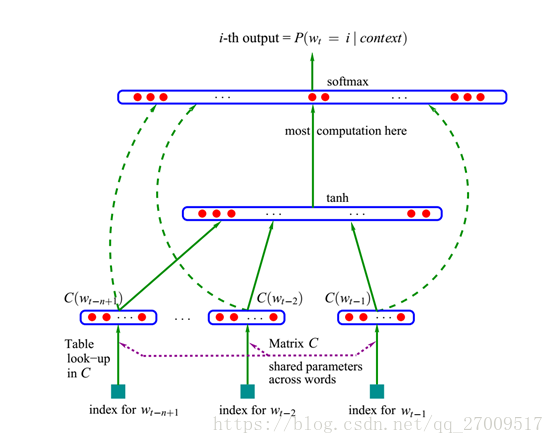
首先是一個線性的嵌入式層,將輸入的one-hot詞向量通過 D×V 的矩陣 C 對映為 N-1 個詞向量, V 是詞典的大小, D 是詞向量的維度,而 C 矩陣就儲存了要學習的詞向量。
接下來是一個前向反饋神經網路,由tanh隱藏層和softmax輸出層組成,將嵌入層輸出的 N-1 個詞向量對映為長度為V 的概率分佈向量,從而對詞典中輸入的詞Wt 在context下進行預測,公式如下:
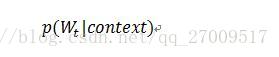
由於NNLM只能處理定長序列,而且訓練速度太慢,所以需要改進,移除tanh層,忽略上下文的序列資訊,得到的模型稱為CBoW[11](Continuous Bag-of-Words Model),作用是將詞袋模型的向量乘以嵌入式矩陣,得到連續的嵌入向量,它是在上下文學習以得到詞向量的表達。而Skip-gram模型則是對上下文裡的詞進行取樣[11],即從詞的上下文獲得詞向量,如圖2.4所示。
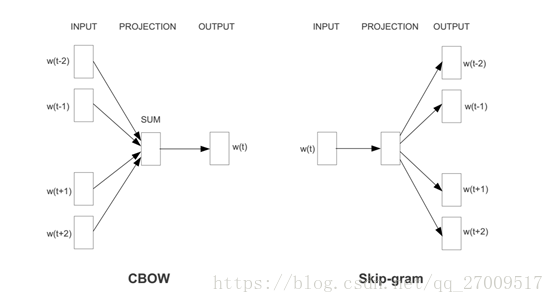
改進後的神經網路僅三層,其中隱藏層的權重即是要訓練的詞向量。
6. 對語料進行分類後,要對分類結果進行評價
(1)準確率(precision)和召回率(recall)
準確率,是分類結果中的某類別判斷正確的文件中有多少是真正的正樣本的比例,是針對預測結果而言的,衡量的是分類系統的查準率。計算公式如下:
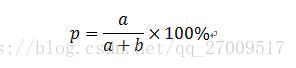
召回率,是原來某個類別的文字的分類結果中有多少被預測為正確的比例,是針對原來樣本而言的,衡量的是分類系統的查全率。計算公式如下:
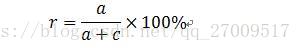
但是,準確率和召回率不總是正相關,有時是負相關,需要F測度來平衡。
(2)F測度(F-measure)
是正確率和召回率的的加權調和平均,公式如下:

當 時,就是F1,即