
對基於深度神經網路的Auto Encoder用於異常檢測的一些思考
一、前言
現實中,大部分資料都是無標籤的,人和動物多數情況下都是通過無監督學習獲取概念,故而無監督學習擁有廣闊的業務場景。舉幾個場景:網路流量是正常流量還是攻擊流量、視訊中的人的行為是否正常、運維中伺服器狀態是否異常等等。有監督學習的做法是給樣本標出label,那麼標label的過程肯定是基於某一些規則(圖片除外),既然有了規則,何必要機器學習?基於規則寫程式就得了,到底是先有雞,還是先有蛋?如果計算機可以自己在資料中發現規律,就解決了這個爭論。那麼基於深度神經網路的auto encoder,可以解決一部分問題。
二、Auto Encoder介紹
Auto Encoder實際上是一個資訊壓縮的過程,把高維資料壓縮至低維度,先來看一下PCA。(以下圖片來自於臺大李巨集毅教授的ppt)
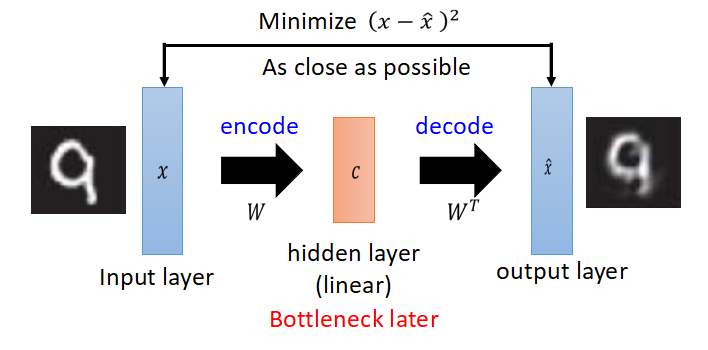
PCA的解釋:原向量x乘以矩陣W得到中間編碼c,再乘以W的轉置,得到x head,得到的x head希望與原x越接近越好,有一點要注意,從x到c的變換過程是線性的。
Deep Auto Encoder和PCA類似,只是網路層數更深,變換是非線性的(因為可以加入一些非線性的啟用函式),Deep Auto Encoder變成成了如下的樣子:
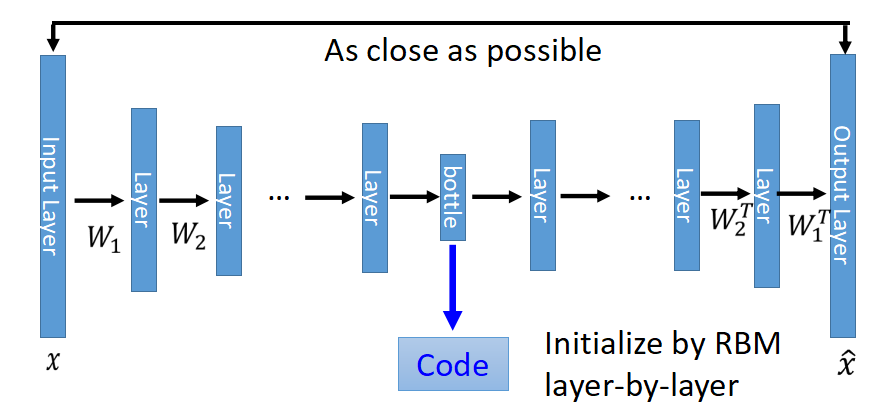
中間有個很窄的hidden layer的輸出就是壓縮之後的code,當然以bottle layer對稱的W不必要互為轉置,也不要求一定要用RBM初始化引數,直接train,效果也很好。
下面來看一下,對於MNIST手寫數字資料集用畫素點、PCA、Deep Auto Encoder三種方式分別做tSNE的展現圖
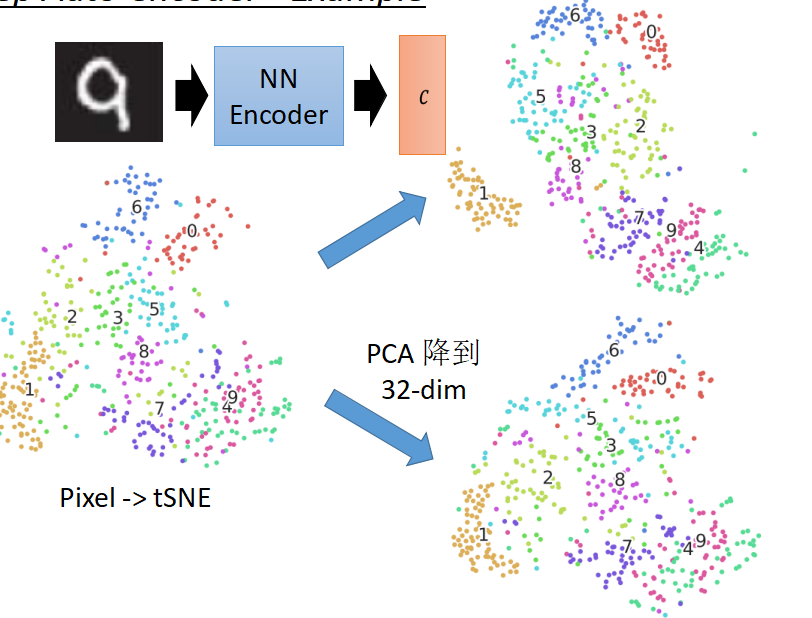
右上角為deep auto encoder之後做tSNE,所有的數字都分的很開,效果比較好。
總結一下,PCA和Deep auto encoder所做的事都類似,就是把原資料壓縮到一個低維向量,讓後再反解回來,反解回來的值希望與原來的值越接近越好。
三、Auto Encoder用於異常檢測
對於自動編碼器用於異常檢測,可以參考《Variational Autoencoder based Anomaly Detection using Reconstruction Probability》這篇論文 ,論文地址:
文中不是直接從變分自動編碼器切入,而是先介紹自動編碼器,論文言簡意賅,我們先來看看論文中對Auto Encoder的訓練過程的描述

說明:
1、編碼器fφ,decoder gθ
2、損失函式說明:這裡用二範數來表示了,二範數實際上是歐幾里得距離,也就是均方誤差,也就是希望解碼出來的值和原值月接近越好。
下面來看,如果將Auto Encoder用於異常檢測,還是先看公式

說明:
1、先用正常的資料集訓練一個Auto Encoder
2、用訓練出的Auto Encoder計算異常資料的重建誤差,重建誤差大於某個閥值α,則為異常,否則則正常。
文中有這樣一段描述:
Autoencoder based anomaly detection is a deviation based anomaly detection method using semi-supervised learning. It uses the reconstruction error as the anomaly score. Data points with high reconstruction are considered to be anomalies.Only data with normal instances are used to train the autoencoder
這段描述指出了兩點:
1、半監督,用正常的資料訓練一個Auto Encoder
2、重建誤差高的資料為異常資料
普通Deep Auto Encoder有個缺陷,通俗的話來講就是模型看過的類似的資料它知道,模型沒看過的資料,幾乎不可能能知道,那變分編碼器,就可能解決了一部分問題,通過用分佈相似來解釋這個問題,請看下面的公式:

整個訓練的過程用通俗的話說明一下,首先從標準正態分佈中隨機L個數據和原x經過hφ函式後得到隱含變數z,注意這裡是為每一個樣本x都隨機L個數據來生成z,loss函式告訴我們兩件事情,
第一件,希望z的分佈和給定了x的條件下z的分佈越接近越好,第二件,希望給定了z的條件下反解回來的x和原分佈越接近越好。本質上而言,VAE是給原x加上了隨機噪聲,同時希望可以反解回原來的值,
中間隱含變數就非常神奇了,可以是高斯分佈,也可以是伯努利分佈,用概率分佈來編碼,在自動生成中有妙用。
那麼VAE是如何用於異常檢測的呢?請繼續往下看。

上面的訓練過程,可以這樣解釋,給定x的條件下獲取z的分佈的平均值和方差,就得到了一個基於x的分佈,從該分佈中得到L個隱含變數z,通過z反解回x,得到重建概率,
重建概率小於某個閥值為異常,否則則為正常。
四、一些思考
論文中只給出了可以這樣做以及這樣做的效果,但是論文中沒有解釋為什麼這樣做。
其實這個問題比較好類比,訓練資料都是正常的,就好比一個人生活的圈子裡只有貓,突然來了一條狗,他就肯定不認識了,只知道和貓不同,那麼通過數學中的線性迴歸來類推一下,根據一批正常點擬合了一條直線,有一個遊離於這個群體的點,自然離這條直線很遠。同樣的可以用資料邊界來解釋,神經網路見過了大量的正常資料,便學習到了資料的邊界,遊離於邊界外的資料,自然也可以摘出來。
但是同樣有一個問題,既然原始樣本集裡已經有正常資料和異常資料了,通過有監督訓練一個分類模型就夠了。但是真實的場景裡,我們是不知道怎麼標註資料的,如果說可以標註,肯定是基於人工指定的規則,既然有了規則,就基於規則寫if else(這裡是針對資料維度比較小的場景)了,何必要機器來學習,但是規則制定的是否正確還兩說,比方說金融領域常見的風險評估,某個使用者是否可以放貸給他,已知該使用者的各種資訊,例如:年齡、性別、職業、收入、信用卡賬單等等,這裡只是舉一個小例子。
以上的疑問,總結起來就兩點
1、如何標註資料,到底是先有雞還是先有蛋
2、基於定死的規則標註的資料是否正確可用
那麼,能不能完全無監督的讓機器學習出識別這些異常資料的規則,我覺得通過Auto Encoder是可以做到的,首先,對於異常識別的場景,正常的樣本數肯定佔大多數,異常的只是少數,把整個樣本集完全扔給Deep Auto Encoder,讓他去學習,同樣可以找出異常資料。
我寫了一個小例子來驗證我的觀點。
框架:DL4J
我們有經典的資料集,根據天氣判斷是否打球,這裡是從weka的data中複製的,
@attribute outlook {sunny, overcast, rainy}
@attribute temperature {hot, mild, cool}
@attribute humidity {high, normal}
@attribute windy {TRUE, FALSE}
@attribute play {yes, no}
@data
sunny,hot,high,FALSE,no
sunny,hot,high,TRUE,no
overcast,hot,high,FALSE,yes
rainy,mild,high,FALSE,yes
rainy,cool,normal,FALSE,yes
rainy,cool,normal,TRUE,no
overcast,cool,normal,TRUE,yes
sunny,mild,high,FALSE,no
sunny,cool,normal,FALSE,yes
rainy,mild,normal,FALSE,yes
sunny,mild,normal,TRUE,yes
overcast,mild,high,TRUE,yes
overcast,hot,normal,FALSE,yes
rainy,mild,high,TRUE,no利用DL4J構建一個多層全連線神經網路,程式碼如下
public class OneHotEncoder {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("sunny", 0);
map.put("overcast", 1);
map.put("rainy", 2);
map.put("hot", 3);
map.put("mild", 4);
map.put("cool", 5);
map.put("high", 6);
map.put("normal", 7);
map.put("TRUE", 8);
map.put("FALSE", 9);
map.put("yes", 0);
map.put("no", 1);
String data = new StringBuilder().append("sunny,hot,high,FALSE,no").append("\n")
.append("sunny,hot,high,TRUE,no").append("\n").append("overcast,hot,high,FALSE,yes").append("\n")
.append("rainy,mild,high,FALSE,yes").append("\n").append("rainy,cool,normal,FALSE,yes").append("\n")
.append("rainy,cool,normal,TRUE,no").append("\n").append("overcast,cool,normal,TRUE,yes").append("\n")
.append("sunny,mild,high,FALSE,no").append("\n").append("sunny,cool,normal,FALSE,yes").append("\n")
.append("rainy,mild,normal,FALSE,yes").append("\n").append("sunny,mild,normal,TRUE,yes").append("\n")
.append("overcast,mild,high,TRUE,yes").append("\n").append("overcast,hot,normal,FALSE,yes").append("\n")
.append("rainy,mild,high,TRUE,no").toString();
INDArray feature = Nd4j.zeros(new int[] { 9, 10 });
INDArray featureTest = Nd4j.zeros(new int[] { 5, 10 });
INDArray label = Nd4j.zeros(14, 2);
String[] rows = data.split("\n");
int index=0;
int indexTest=0;
for (int i = 0; i < rows.length; i++) {
String[] cols = rows[i].split(",");
if(cols[cols.length-1].equals("yes")){
for (int j = 0; j < cols.length - 1; j++) {
feature.putScalar(index, map.get(cols[j]), 1.0);
}
index++;
}else{
for (int j = 0; j < cols.length - 1; j++) {
featureTest.putScalar(indexTest, map.get(cols[j]), 1.0);
}
indexTest++;
}
label.putScalar(i, map.get(cols[cols.length - 1]), 1.0);
}
DataSet dataSet = new DataSet( Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature), Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature));
DataSet dataSetTest = new DataSet(featureTest, featureTest);
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder().seed(123).activation(Activation.TANH)
.weightInit(WeightInit.XAVIER).updater(new Sgd(0.1)).l2(1e-4).list()
.layer(0, new DenseLayer.Builder().nIn(10).nOut(20).build())
.layer(1, new DenseLayer.Builder().nIn(20).nOut(2).build())
.layer(2, new DenseLayer.Builder().nIn(2).nOut(20).build())
.layer(3, new OutputLayer.Builder(LossFunctions.LossFunction.MSE).activation(Activation.IDENTITY)
.nIn(20).nOut(10).build())
.backprop(true).pretrain(false).build();
// run the model
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
model.setListeners(new ScoreIterationListener(1));
LayerWorkspaceMgr mgr = LayerWorkspaceMgr.noWorkspaces();
for (int i = 0; i < 10000; i++) {
model.fit(dataSet);
System.out.println(model.score(dataSetTest));
}
}
}
上面有一段特殊程式碼如下,這裡是把正常樣本的數量加大,造成正負樣本的不均衡
DataSet dataSet = new DataSet( Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature), Nd4j.vstack(feature,featureTest,feature,feature,feature,feature,feature,feature));
訓練之後的結果如下:
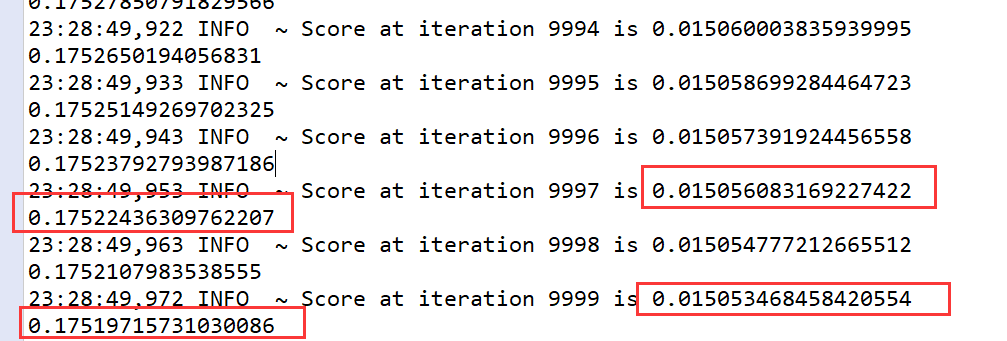
對於異常樣本,Loss和整體的Loss有一個數量級的偏差,完全可以作為異常的檢測,這裡沒有刻意的用正樣本來訓練,而是用正負樣本一起訓練,完全無監督,就達到了異常檢測的效果,當然這適用於正負樣本非常不均衡的場景。
為什麼可以這樣做,我想了一個不用數學公式推導的解釋,將寫在下次部落格中。
最後,DL4J是一個非常優秀的Deeplearning框架,對於Java系的小夥伴想了解Deeplearning的,可以看看DL4J的例子。
快樂源於分享。
此部落格乃作者原創, 轉載請註明出處