
Java8並行http請求加快訪問速度
背景
1.通常我們在獲取到一個list列表後需要一個挨著一個的進行遍歷處理資料,如果每次處理都需要長時間操作,那整個流程下來時間就是每一次處理時間的總和。
2.Java8的stream介面極大地減少了for迴圈寫法的複雜性,stream提供了map/reduce/collect等一系列聚合介面,還支援併發操作:parallelStream。
例子
定義一個位置類和服務,其中建立10個地址位置
package cn.chinotan.dto; /** * @program: test * @description: 位置 * @author: xingcheng * @create: 2018-11-17 19:36 **/ public class Location { String name; public Location() { } public Location(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } }
package cn.chinotan.controller; import cn.chinotan.dto.Location; import org.apache.commons.lang3.StringUtils; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RestController; import java.util.ArrayList; import java.util.List; /** * @program: test * @description: 位置服務 * @author: xingcheng * @create: 2018-11-17 19:42 **/ @RestController public class LocationController { @GetMapping("/location") public List<Location> getLocations() { List<Location> locations = new ArrayList<>(); for (int i = 0; i < 10; i++) { locations.add(new Location(StringUtils.join("London", i))); } return locations; } }
定義一個溫度類和服務,其中溫度值介於30到50之間。 在實現中新增500 ms的延遲以模擬耗時操作
package cn.chinotan.dto; /** * @program: test * @description: 溫度 * @author: xingcheng * @create: 2018-11-17 19:35 **/ public class Temperature { private Double temperature; private String scale; public Double getTemperature() { return temperature; } public void setTemperature(Double temperature) { this.temperature = temperature; } public String getScale() { return scale; } public void setScale(String scale) { this.scale = scale; } }
package cn.chinotan.controller;
import cn.chinotan.dto.Temperature;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.util.Random;
/**
* @program: test
* @description: 溫度服務
* @author: xingcheng
* @create: 2018-11-17 19:45
**/
@RestController
public class TemperatureController {
@GetMapping("/temperature/{city}")
public Temperature getAverageTemperature(@PathVariable("city") String city) {
Temperature temperature = new Temperature();
temperature.setTemperature((double) (new Random().nextInt(20) + 30));
temperature.setScale("Celsius");
try {
Thread.sleep(500);
} catch (InterruptedException ignored) {
}
return temperature;
}
}
定義一個天氣預報類和響應
package cn.chinotan.dto.response;
import cn.chinotan.dto.Forecast;
import java.util.ArrayList;
import java.util.List;
/**
* @program: test
* @description: 服務響應
* @author: xingcheng
* @create: 2018-11-17 19:39
**/
public class ServiceResponse {
private long processingTime;
private List<Forecast> forecasts = new ArrayList<>();
public void setProcessingTime(long processingTime) {
this.processingTime = processingTime;
}
public ServiceResponse forecasts(List<Forecast> forecasts) {
this.forecasts = forecasts;
return this;
}
public long getProcessingTime() {
return processingTime;
}
public List<Forecast> getForecasts() {
return forecasts;
}
public void setForecasts(List<Forecast> forecasts) {
this.forecasts = forecasts;
}
}
package cn.chinotan.controller;
import cn.chinotan.dto.Forecast;
import cn.chinotan.dto.Location;
import cn.chinotan.dto.Temperature;
import cn.chinotan.dto.response.ServiceResponse;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.HttpEntity;
import org.springframework.http.HttpMethod;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
import rx.Observable;
import java.util.Comparator;
import java.util.List;
import java.util.stream.Collectors;
/**
* @program: test
* @description: 天氣預報
* @author: xingcheng
* @create: 2018-11-17 19:47
**/
@RestController
public class ForecastController {
@Autowired
RestTemplate restTemplate;
private final static String SERVER_ADDRESS = "http://localhost:9000";
@GetMapping("/v1/forecast")
public ServiceResponse getLocationsWithTemperatureV1() {
long startTime = System.currentTimeMillis();
ServiceResponse response = new ServiceResponse();
List<Location> locations = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/location"), HttpMethod.GET,
HttpEntity.EMPTY, new ParameterizedTypeReference<List<Location>>() {
}).getBody();
locations.forEach(location -> {
Temperature temperature = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/temperature/", location.getName()),
HttpMethod.GET, HttpEntity.EMPTY, Temperature.class).getBody();
response.getForecasts().add(new Forecast(location).setTemperature(temperature));
});
long endTime = System.currentTimeMillis();
response.setProcessingTime(endTime - startTime);
return response;
}
@GetMapping("/v2/forecast")
public ServiceResponse getLocationsWithTemperatureV2() {
long startTime = System.currentTimeMillis();
ServiceResponse response = new ServiceResponse();
List<Location> locations = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/location"), HttpMethod.GET,
HttpEntity.EMPTY, new ParameterizedTypeReference<List<Location>>() {
}).getBody();
List<Forecast> collect = locations.parallelStream().map(location -> {
Temperature temperature = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/temperature/", location.getName()),
HttpMethod.GET, HttpEntity.EMPTY, Temperature.class).getBody();
return new Forecast(location).setTemperature(temperature);
}).collect(Collectors.toList());
long sortStart = System.currentTimeMillis();
List<Forecast> collectResponse = collect.parallelStream().sorted().collect(Collectors.toList());
long sortEnd = System.currentTimeMillis();
System.out.println("排序花費時間:" + (sortEnd - sortStart));
response.setForecasts(collectResponse);
long endTime = System.currentTimeMillis();
response.setProcessingTime(endTime - startTime);
return response;
}
@GetMapping("/v3/forecast")
public ServiceResponse getLocationsWithTemperatureV3() {
long startTime = System.currentTimeMillis();
ServiceResponse response = new ServiceResponse();
List<Location> locations = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/location"), HttpMethod.GET,
HttpEntity.EMPTY, new ParameterizedTypeReference<List<Location>>() {
}).getBody();
locations.parallelStream().forEachOrdered(location -> {
Temperature temperature = restTemplate.exchange(StringUtils.join(SERVER_ADDRESS, "/temperature/", location.getName()),
HttpMethod.GET, HttpEntity.EMPTY, Temperature.class).getBody();
response.getForecasts().add(new Forecast(location).setTemperature(temperature));
});
long endTime = System.currentTimeMillis();
response.setProcessingTime(endTime - startTime);
return response;
}
}
其中,v1介面是普通的list遍歷實現,介面響應:
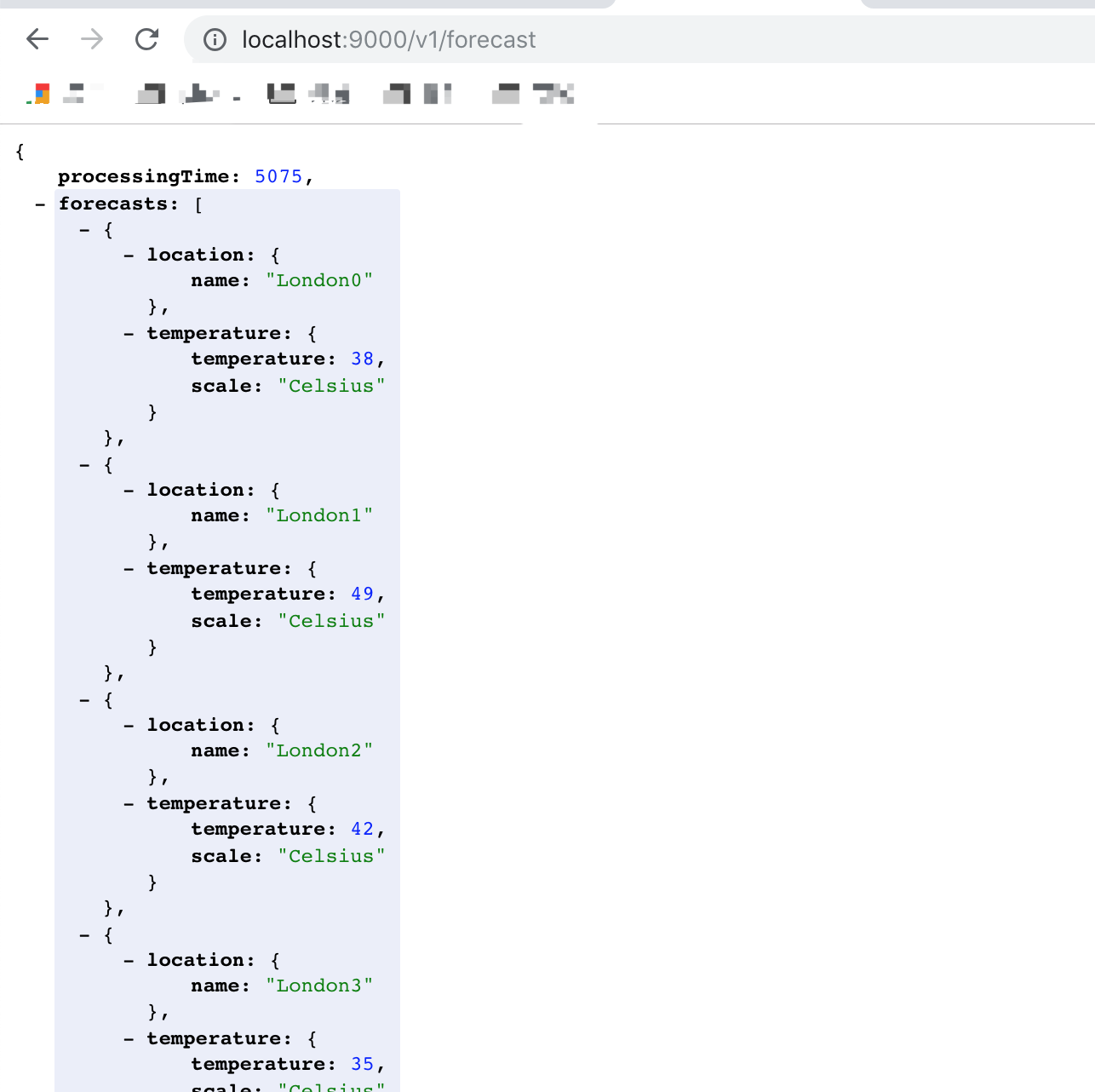
可以看到介面響應時間是每次http呼叫的時間(500毫秒)總和多一些
接下來呼叫v2介面:
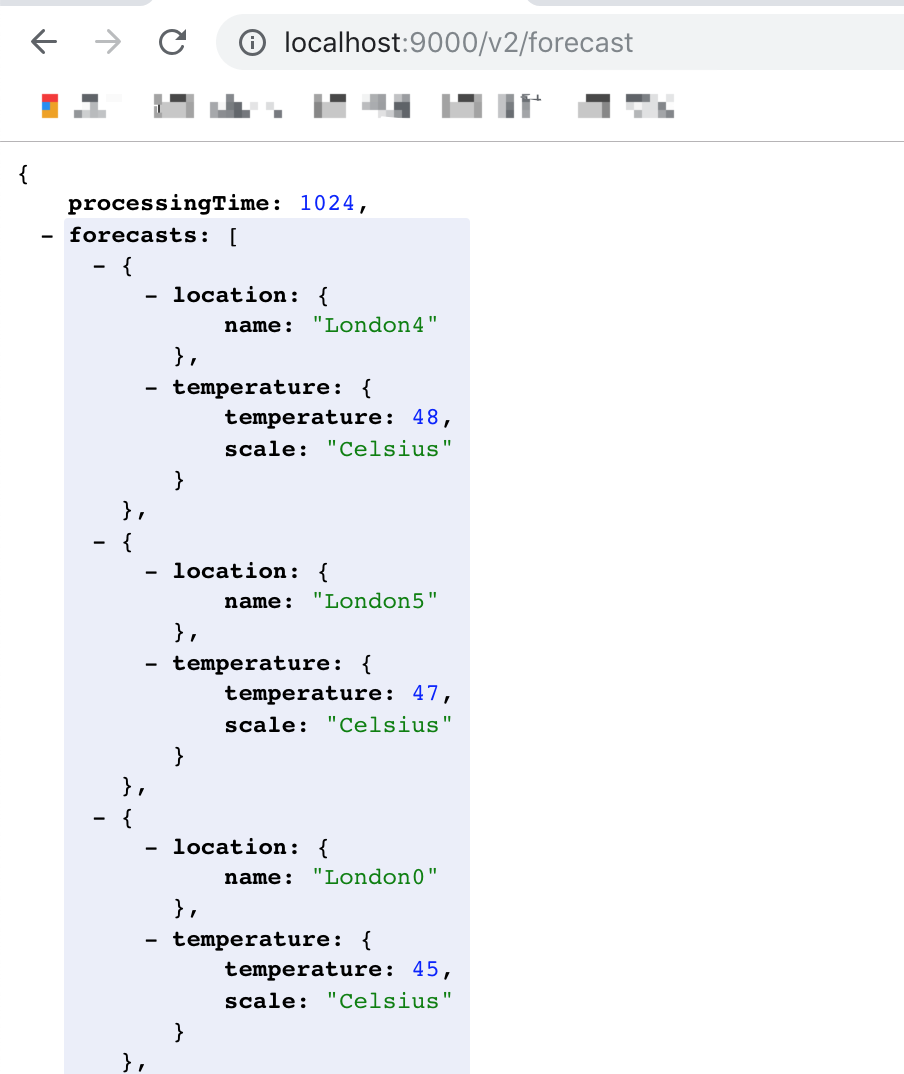
可以看到時間縮短了5倍
分析
先了解什麼是流?
Stream是java8中新增加的一個特性, 統稱為流.
Stream 不是集合元素,它不是資料結構並不儲存資料,它是有關演算法和計算的,它更像一個高階版本的 Iterator。原始版本的 Iterator,使用者只能顯式地一個一個遍歷元素並對其執行某些操作;高階版本的 Stream,使用者只要給出需要對其包含的元素執行什麼操作,比如 “過濾掉長度大於 10 的字串”、“獲取每個字串的首字母”等,Stream 會隱式地在內部進行遍歷,做出相應的資料轉換。
Stream 就如同一個迭代器(Iterator),單向,不可往復,資料只能遍歷一次,遍歷過一次後即用盡了,就好比流水從面前流過,一去不復返。
而和迭代器又不同的是,Stream 可以並行化操作,迭代器只能命令式地、序列化操作。顧名思義,當使用序列方式去遍歷時,每個 item 讀完後再讀下一個 item。而使用並行去遍歷時,資料會被分成多個段,其中每一個都在不同的執行緒中處理,然後將結果一起輸出。Stream 的並行操作依賴於 Java7 中引入的 Fork/Join 框架(JSR166y)來拆分任務和加速處理過程。Java 的並行 API 演變歷程基本如下:
-
.0-1.4 中的 java.lang.Thread
-
5.0 中的 java.util.concurrent
-
6.0 中的 Phasers 等
-
7.0 中的 Fork/Join 框架
-
8.0 中的 Lambda
parallelStream是什麼
parallelStream其實就是一個並行執行的流.它通過預設的ForkJoinPool,可能提高你的多執行緒任務的速度.
parallelStream的作用
Stream具有平行處理能力,處理的過程會分而治之,也就是將一個大任務切分成多個小任務,這表示每個任務都是一個操作,因此像以下的程式片段:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEach(out::println);你得到的展示順序不一定會是1、2、3、4、5、6、7、8、9,而可能是任意的順序,就forEach()這個操作來講,如果平行處理時,希望最後順序是按照原來Stream的資料順序,那可以呼叫forEachOrdered()。例如:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEachOrdered(out::println);
注意:如果forEachOrdered()中間有其他如filter()的中介操作,會試著平行化處理,然後最終forEachOrdered()會以原資料順序處理,因此,使用forEachOrdered()這類的有序處理,可能會(或完全失去)失去平行化的一些優勢,實際上中介操作亦有可能如此,例如sorted()方法。
例如:執行v3介面:

可以看到執行時間和普通的流一樣。。。
parallelStream細節探祕: ForkJoinPool
要想深入的研究parallelStream之前,那麼我們必須先了解ForkJoin框架和ForkJoinPool.因為兩種關係甚密,故在此簡單介紹一下ForkJoinPool,如有興趣可以更深入的去了解下ForkJoin***(當然,如果你想真正的搞透parallelStream,那麼你依然需要先搞透ForkJoinPool).*
ForkJoin框架是從jdk7中新特性,它同ThreadPoolExecutor一樣,也實現了Executor和ExecutorService介面。它使用了一個無限佇列來儲存需要執行的任務,而執行緒的數量則是通過建構函式傳入,如果沒有向建構函式中傳入希望的執行緒數量,那麼當前計算機可用的CPU數量會被設定為執行緒數量作為預設值。
ForkJoinPool主要用來使用分治法(Divide-and-Conquer Algorithm)來解決問題。典型的應用比如快速排序演算法。這裡的要點在於,ForkJoinPool需要使用相對少的執行緒來處理大量的任務。比如要對1000萬個資料進行排序,那麼會將這個任務分割成兩個500萬的排序任務和一個針對這兩組500萬資料的合併任務。以此類推,對於500萬的資料也會做出同樣的分割處理,到最後會設定一個閾值來規定當資料規模到多少時,停止這樣的分割處理。比如,當元素的數量小於10時,會停止分割,轉而使用插入排序對它們進行排序。那麼到最後,所有的任務加起來會有大概2000000+個。問題的關鍵在於,對於一個任務而言,只有當它所有的子任務完成之後,它才能夠被執行。
所以當使用ThreadPoolExecutor時,使用分治法會存在問題,因為ThreadPoolExecutor中的執行緒無法像任務佇列中再新增一個任務並且在等待該任務完成之後再繼續執行。而使用ForkJoinPool時,就能夠讓其中的執行緒建立新的任務,並掛起當前的任務,此時執行緒就能夠從佇列中選擇子任務執行。
那麼使用ThreadPoolExecutor或者ForkJoinPool,會有什麼效能的差異呢?
首先,使用ForkJoinPool能夠使用數量有限的執行緒來完成非常多的具有父子關係的任務,比如使用4個執行緒來完成超過200萬個任務。但是,使用ThreadPoolExecutor時,是不可能完成的,因為ThreadPoolExecutor中的Thread無法選擇優先執行子任務,需要完成200萬個具有父子關係的任務時,也需要200萬個執行緒,顯然這是不可行的。
工作竊取演算法
forkjoin最核心的地方就是利用了現代硬體裝置多核,在一個操作時候會有空閒的cpu,那麼如何利用好這個空閒的cpu就成了提高效能的關鍵,而這裡我們要提到的工作竊取(work-stealing)演算法就是整個forkjion框架的核心理念,工作竊取(work-stealing)演算法是指某個執行緒從其他佇列裡竊取任務來執行。
那麼為什麼需要使用工作竊取演算法呢?
假如我們需要做一個比較大的任務,我們可以把這個任務分割為若干互不依賴的子任務,為了減少執行緒間的競爭,於是把這些子任務分別放到不同的佇列裡,併為每個佇列建立一個單獨的執行緒來執行佇列裡的任務,執行緒和佇列一一對應,比如A執行緒負責處理A佇列裡的任務。但是有的執行緒會先把自己佇列裡的任務幹完,而其他執行緒對應的佇列裡還有任務等待處理。幹完活的執行緒與其等著,不如去幫其他執行緒幹活,於是它就去其他執行緒的佇列裡竊取一個任務來執行。而在這時它們會訪問同一個佇列,所以為了減少竊取任務執行緒和被竊取任務執行緒之間的競爭,通常會使用雙端佇列,被竊取任務執行緒永遠從雙端佇列的頭部拿任務執行,而竊取任務的執行緒永遠從雙端佇列的尾部拿任務執行。
工作竊取演算法的優點是充分利用執行緒進行平行計算,並減少了執行緒間的競爭,其缺點是在某些情況下還是存在競爭,比如雙端佇列裡只有一個任務時。並且消耗了更多的系統資源,比如建立多個執行緒和多個雙端佇列。
用看forkjion的眼光來看ParallelStreams
上文中已經提到了在Java 8引入了自動並行化的概念。它能夠讓一部分Java程式碼自動地以並行的方式執行,也就是我們使用了ForkJoinPool的ParallelStream。
Java 8為ForkJoinPool添加了一個通用執行緒池,這個執行緒池用來處理那些沒有被顯式提交到任何執行緒池的任務。它是ForkJoinPool型別上的一個靜態元素,它擁有的預設執行緒數量等於執行計算機上的處理器數量。當呼叫Arrays類上新增的新方法時,自動並行化就會發生。比如用來排序一個數組的並行快速排序,用來對一個數組中的元素進行並行遍歷。自動並行化也被運用在Java 8新新增的Stream API中。
對於列表中的元素的操作都會以並行的方式執行。forEach方法會為每個元素的計算操作建立一個任務,該任務會被前文中提到的ForkJoinPool中的通用執行緒池處理。以上的平行計算邏輯當然也可以使用ThreadPoolExecutor完成,但是就程式碼的可讀性和程式碼量而言,使用ForkJoinPool明顯更勝一籌。
對於ForkJoinPool通用執行緒池的執行緒數量,通常使用預設值就可以了,即執行時計算機的處理器數量。我這裡提供了一個示例的程式碼讓你瞭解jvm所使用的ForkJoinPool的執行緒數量, 你可以可以通過設定系統屬性:-Djava.util.concurrent.ForkJoinPool.common.parallelism=N (N為執行緒數量),來調整ForkJoinPool的執行緒數量,可以嘗試調整成不同的引數來觀察每次的輸出結果。
但是它會將執行forEach本身的執行緒也作為執行緒池中的一個工作執行緒。因此,即使將ForkJoinPool的通用執行緒池的執行緒數量設定為1,實際上也會有2個工作執行緒。因此在使用forEach的時候,執行緒數為1的ForkJoinPool通用執行緒池和執行緒數為2的ThreadPoolExecutor是等價的。
所以當ForkJoinPool通用執行緒池實際需要4個工作執行緒時,可以將它設定成3,那麼在執行時可用的工作執行緒就是4了。
小結
1. 當需要處理遞迴分治演算法時,考慮使用ForkJoinPool。
2. 仔細設定不再進行任務劃分的閾值,這個閾值對效能有影響。
3. Java 8中的一些特性會使用到ForkJoinPool中的通用執行緒池。在某些場合下,需要調整該執行緒池的預設的執行緒數量。
ParallelStreams 的陷阱
上文中我們已經看到了ParallelStream他強大無比的特性,但這裡我們就講告訴你ParallelStreams不是萬金油,而是一把雙刃劍,如果錯誤的使用反倒可能傷人傷己.
可能有很多朋友在jdk7用future配合countDownLatch自己實現的這個功能,但是jdk8的朋友基本都會用上面的實現方式,那麼自信深究一下究竟自己用future實現的這個功能和利用jdk8的parallelStream來實現這個功能有什麼不同點呢?坑又在哪裡呢?
讓我們細思思考一下整個功能究竟是如何運轉的。首先我們的集合元素engines 由ParallelStreams並行的去進行map操作(ParallelStreams使用JVM預設的forkJoin框架的執行緒池由當前執行緒去執行並行操作).
然而,這裡需要注意的一地方是我們在呼叫第三方的api請求是一個響應略慢而且會阻塞操作的一個過程。所以在某時刻所有執行緒都會呼叫 get() 方法並且在那裡等待結果返回.
再回過頭仔細思考一下這個功能的實現過程是我們一開始想要的嗎?我們是在同一時間等待所有的結果,而不是遍歷這個列表按順序等待每個回答.然而,由於ForkJoinPool workders的存在,這樣平行的等待相對於使用主執行緒的等待會產生的一種副作用.
現在ForkJoin pool (關於forkjion的更多實現你可以去搜索引擎中去看一下他的具體實現方式) 的實現是: 它並不會因為產生了新的workers而抵消掉阻塞的workers。那麼在某個時間所有 ForkJoinPool.common() 的執行緒都會被用光.也就是說,下一次你呼叫這個查詢方法,就可能會在一個時間與其他的parallel stream同時執行,而導致第二個任務的效能大大受損。或者說,例如你在這個功能裡是用來快速返回呼叫的第三方api的,而在其他的功能裡是用於一些簡單的資料平行計算的,但是假如你先呼叫了這個功能,同一時間之後呼叫計算的函式,那麼這裡forkjionPool的實現會讓你計算的函式大打折扣.
不過也不要急著去吐槽ForkJoinPool的實現,在不同的情況下你可以給它一個ManagedBlocker例項並且確保它知道在一個阻塞呼叫中應該什麼時候去抵消掉卡住的workers.現在有意思的一點是,在一個parallel stream處理中並不一定是阻塞呼叫會拖延程式的效能。任何被用於對映在一個集合上的長時間執行的函式都會產生同樣的問題.
正如我們上面那個列子的情況分析得知,lambda的執行並不是瞬間完成的,所有使用parallel streams的程式都有可能成為阻塞程式的源頭,並且在執行過程中程式中的其他部分將無法訪問這些workers,這意味著任何依賴parallel streams的程式在什麼別的東西佔用著common ForkJoinPool時將會變得不可預知並且暗藏危機.
此外,parallelStream是並行操作,不是執行緒安全的,那麼是不是在其中的進行的非原子操作都要加鎖呢?
答案是:paralleStream的forEach介面確實不能保證同步,同時也提出瞭解決方案:使用collect和reduce介面,Collections框架提供了同步的包裝,使得其中的操作執行緒安全。
即程式碼中的:

怎麼正確使用parallelStream
如果你正在寫一個其他地方都是單執行緒的程式並且準確地知道什麼時候你應該要使用parallel streams,這樣的話你可能會覺得這個問題有一點膚淺。然而,我們很多人是在處理web應用、各種不同的框架以及重量級應用服務。一個伺服器是怎樣被設計成一個可以支援多種獨立應用的主機的?誰知道呢,給你一個可以並行的卻不能控制輸入的parallel stream.
很抱歉,請原諒我用的標註[怎麼正確使用parallelStream],因為目前為止我也沒有發現一個好的方式來讓我真正的正確使用parallelStream.下面的網上寫的兩種方式:
一種方式是限制ForkJoinPool提供的並行數。可以通過使用-Djava.util.concurrent.ForkJoinPool.common.parallelism=1 來限制執行緒池的大小為1。不再從並行化中得到好處可以杜絕錯誤的使用它(其實這個方式還是有點搞笑的,既然這樣搞那我還不如不去使用並行流)。
另一種方式就是,一個被稱為工作區的可以讓ForkJoinPool平行放置的 parallelStream() 實現。不幸的是現在的JDK還沒有實現。
Parallel streams 是無法預測的,而且想要正確地使用它有些棘手。幾乎任何parallel streams的使用都會影響程式中無關部分的效能,而且是一種無法預測的方式。。但是在呼叫stream.parallel() 或者parallelStream()時候在我的程式碼裡之前我仍然會重新審視一遍他給我的程式究竟會帶來什麼問題,他能有多大的提升,是否有使用他的意義.
stream or parallelStream?
上面我們也看到了parallelStream所帶來的隱患和好處,那麼,在從stream和parallelStream方法中進行選擇時,我們可以考慮以下幾個問題:
1. 是否需要並行?
2. 任務之間是否是獨立的?是否會引起任何競態條件?
3. 結果是否取決於任務的呼叫順序?
對於問題1,在回答這個問題之前,你需要弄清楚你要解決的問題是什麼,資料量有多大,計算的特點是什麼?並不是所有的問題都適合使用併發程式來求解,比如當資料量不大時,順序執行往往比並行執行更快。畢竟,準備執行緒池和其它相關資源也是需要時間的。但是,當任務涉及到I/O操作並且任務之間不互相依賴時,那麼並行化就是一個不錯的選擇。通常而言,將這類程式並行化之後,執行速度會提升好幾個等級。
對於問題2,如果任務之間是獨立的,並且程式碼中不涉及到對同一個物件的某個狀態或者某個變數的更新操作,那麼就表明程式碼是可以被並行化的。
對於問題3,由於在並行環境中任務的執行順序是不確定的,因此對於依賴於順序的任務而言,並行化也許不能給出正確的結果。
參考文章:https://blog.csdn.net/u011001723/article/details/52794455