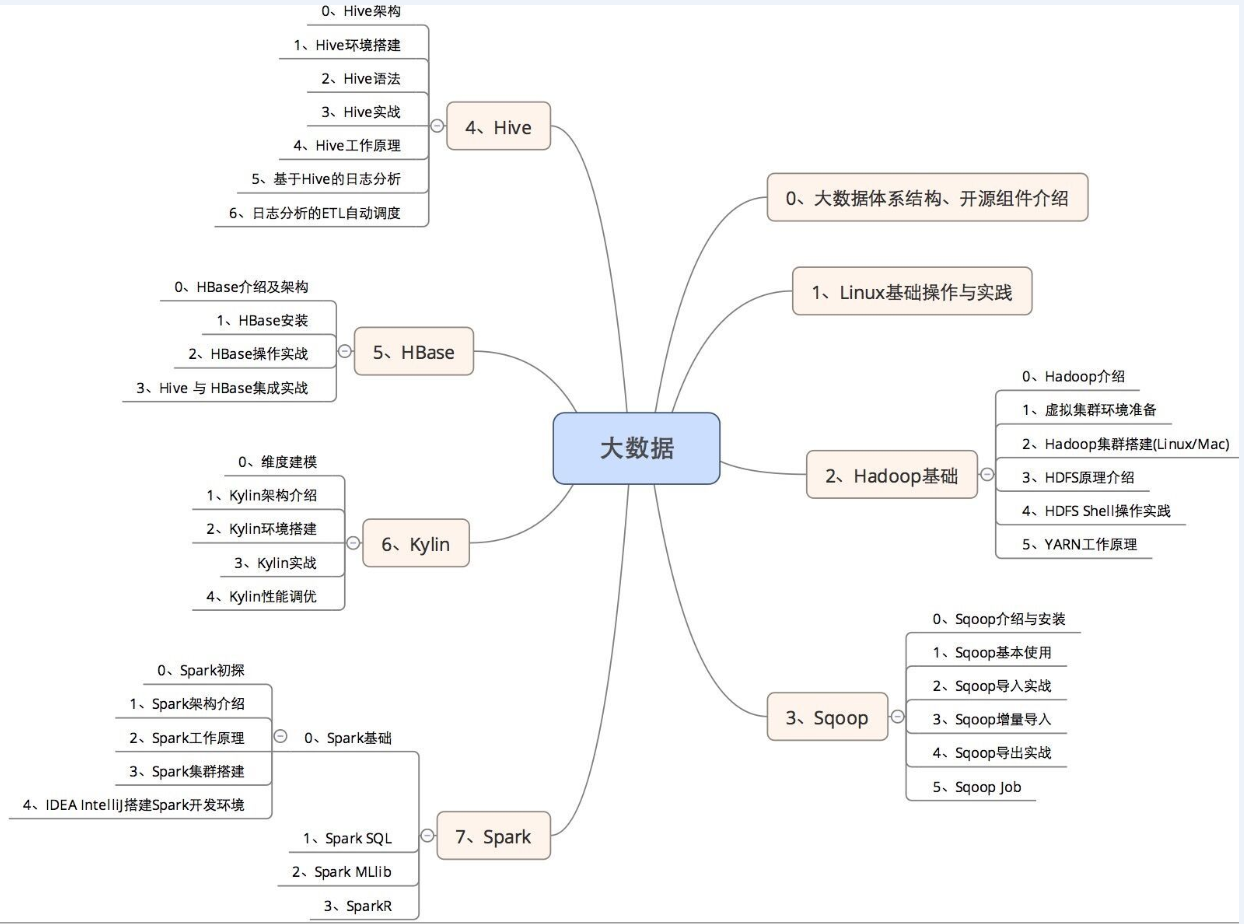
零基礎轉行大資料怎麼學習?大資料學習路線
大資料的領域非常廣泛,往往使想要開始學習大資料及相關技術的人望而生畏。大資料技術的種類眾多,這同樣使得初學者難以選擇從何處下手。希望能為你開始學習大資料的征程提供幫助,以及在大資料產業領域找到工作指明道路。
一、大資料技術基礎
1、linux操作基礎
· linux系統簡介與安裝
· linux常用命令–檔案操作
· linux常用命令–使用者管理與許可權
· linux常用命令–系統管理
· linux常用命令–免密登陸配置與網路管理
· linux上常用軟體安裝
· linux本地yum源配置及yum軟體安裝
· linux防火牆配置
· linux高階文字處理命令cut、sed、awk
· linux定時任務crontab
2、shell程式設計
· shell程式設計–基本語法
· shell程式設計–流程控制
· shell程式設計–函式
· shell程式設計–綜合案例–自動化部署指令碼
3、記憶體資料庫redis
· redis和nosql簡介
· redis客戶端連線
· redis的string型別資料結構操作及應用-物件快取
· redis的list型別資料結構操作及應用案例-任務排程佇列
· redis的hash及set資料結構操作及應用案例-購物車
· redis的sortedset資料結構操作及應用案例-排行榜
4、布式協調服務zookeeper
· zookeeper簡介及應用場景
· zookeeper叢集安裝部署
· zookeeper的資料節點與命令列操作
· zookeeper的java客戶端基本操作及事件監聽
· zookeeper核心機制及資料節點
· zookeeper應用案例–分散式共享資源鎖
· zookeeper應用案例–伺服器上下線動態感知
· zookeeper的資料一致性原理及leader選舉機制
5、java高階特性增強
· Java多執行緒基本知識
· Java同步關鍵詞詳解
· java併發包執行緒池及在開源軟體中的應用
· Java併發包訊息隊裡及在開源軟體中的應用
· Java JMS技術
· Java動態代理反射
6、輕量級RPC框架開發
· RPC原理學習
· Nio原理學習
· Netty常用API學習
· 輕量級RPC框架需求分析及原理分析
· 輕量級RPC框架開發
二、離線計算系統
1、hadoop快速入門
· hadoop背景介紹
· 分散式系統概述
· 離線資料分析流程介紹
· 叢集搭建
· 叢集使用初步
2、HDFS增強
· HDFS的概念和特性
· HDFS的shell(命令列客戶端)操作
· HDFS的工作機制
· NAMENODE的工作機制
· java的api操作
· 案例1:開發shell採集指令碼
3、MAPREDUCE詳解
· 自定義hadoop的RPC框架
· Mapreduce程式設計規範及示例編寫
· Mapreduce程式執行模式及debug方法
· mapreduce程式執行模式的內在機理
· mapreduce運算框架的主體工作流程
· 自定義物件的序列化方法
· MapReduce程式設計案例
4、MAPREDUCE增強
· Mapreduce排序
· 自定義partitioner
· Mapreduce的combiner
· mapreduce工作機制詳解
5、MAPREDUCE實戰
· maptask並行度機制-檔案切片
· maptask並行度設定
· 倒排索引
· 共同好友
6、federation介紹和hive使用
· Hadoop的HA機制
· HA叢集的安裝部署
· 叢集運維測試之Datanode動態上下線
· 叢集運維測試之Namenode狀態切換管理
· 叢集運維測試之資料塊的balance
· HA下HDFS-API變化
· hive簡介
· hive架構
· hive安裝部署
· hvie初使用
7、hive增強和flume介紹
· HQL-DDL基本語法
· HQL-DML基本語法
· HIVE的join
· HIVE 引數配置
· HIVE 自定義函式和Transform
· HIVE 執行HQL的例項分析
· HIVE最佳實踐注意點
· HIVE優化策略
· HIVE實戰案例
· Flume介紹
· Flume的安裝部署
· 案例:採集目錄到HDFS
· 案例:採集檔案到HDFS
三、流式計算
1、Storm從入門到精通
· Storm是什麼
· Storm架構分析
· Storm架構分析
· Storm程式設計模型、Tuple原始碼、併發度分析
· Storm WordCount案例及常用Api分析
· Storm叢集部署實戰
· Storm+Kafka+Redis業務指標計算
· Storm原始碼編譯
· Strom叢集啟動及原始碼分析
· Storm任務提交及原始碼分析
· Storm資料傳送流程分析
· Storm通訊機制分析
· Storm訊息容錯機制及原始碼分析
· Storm多stream專案分析
· 編寫自己的流式任務執行框架
2、Storm上下游及架構整合
· 訊息佇列是什麼
· Kakfa核心元件
· Kafka叢集部署實戰及常用命令
· Kafka配置檔案梳理
· Kakfa JavaApi學習
· Kafka檔案儲存機制分析
· Redis基礎及單機環境部署
· Redis資料結構及典型案例
· Flume快速入門
· Flume+Kafka+Storm+Redis整合
四、記憶體計算體系Spark
1、scala程式設計
· scala程式設計介紹
· scala相關軟體安裝
· scala基礎語法
· scala方法和函式
· scala函數語言程式設計特點
· scala陣列和集合
· scala程式設計練習(單機版WordCount)
· scala面向物件
· scala模式匹配
· actor程式設計介紹
· option和偏函式
· 實戰:actor的併發WordCount
· 柯里化
· 隱式轉換
2、AKKA與RPC
· Akka併發程式設計框架
· 實戰:RPC程式設計實戰
3、Spark快速入門
· spark介紹
· spark環境搭建
· RDD簡介
· RDD的轉換和動作
· 實戰:RDD綜合練習
· RDD高階運算元
· 自定義Partitioner
· 實戰:網站訪問次數
· 廣播變數
· 實戰:根據IP計算歸屬地
· 自定義排序
· 利用JDBC RDD實現資料匯入匯出
· WorldCount執行流程詳解
4、RDD詳解
· RDD依賴關係
· RDD快取機制
· RDD的Checkpoint檢查點機制
· Spark任務執行過程分析
· RDD的Stage劃分
5、Spark-Sql應用
· Spark-SQL
· Spark結合Hive
· DataFrame
· 實戰:Spark-SQL和DataFrame案例
6、SparkStreaming應用實戰
· Spark-Streaming簡介
· Spark-Streaming程式設計
· 實戰:StageFulWordCount
· Flume結合Spark Streaming
· Kafka結合Spark Streaming
· 視窗函式
· ELK技術棧介紹
· ElasticSearch安裝和使用
· Storm架構分析
· Storm程式設計模型、Tuple原始碼、併發度分析
· Storm WordCount案例及常用Api分析
7、Spark核心原始碼解析
· Spark原始碼編譯
· Spark遠端debug
· Spark任務提交行流程原始碼分析
· Spark通訊流程原始碼分析
· SparkContext建立過程原始碼分析
· DriverActor和ClientActor通訊過程原始碼分析
· Worker啟動Executor過程原始碼分析
· Executor向DriverActor註冊過程原始碼分析
· Executor向Driver註冊過程原始碼分析
· DAGScheduler和TaskScheduler原始碼分析
· Shuffle過程原始碼分析
· Task執行過程原始碼分析
五、機器學習演算法
1、python及numpy庫
· 機器學習簡介
· 機器學習與python
· python語言–快速入門
· python語言–資料型別詳解
· python語言–流程控制語句
· python語言–函式使用
· python語言–模組和包
· phthon語言–面向物件
· python機器學習演算法庫–numpy
· 機器學習必備數學知識–概率論
2、常用演算法實現
· knn分類演算法–演算法原理
· knn分類演算法–程式碼實現
· knn分類演算法–手寫字識別案例
· lineage迴歸分類演算法–演算法原理
· lineage迴歸分類演算法–演算法實現及demo
· 樸素貝葉斯分類演算法–演算法原理
· 樸素貝葉斯分類演算法–演算法實現
· 樸素貝葉斯分類演算法–垃圾郵件識別應用案例
· kmeans聚類演算法–演算法原理
· kmeans聚類演算法–演算法實現
· kmeans聚類演算法–地理位置聚類應用
· 決策樹分類演算法–演算法原理
· 決策樹分類演算法–演算法實現
以上大資料學習線路圖僅供大家參考