專案課---企業級Memcached服務應用實踐(八)
一, Memcached介紹
1.1 Memcached與常見同類軟體對比
(1)Memcached是什麼?
- Memcached是一個開源的,支援高效能,高併發的分散式記憶體快取系統,由C語言編寫,總共2000多行程式碼。從軟體名稱上看,前3個字元“Mem”就是記憶體的意思,而接下來的後面5個字元“cache”就是快取的意思,最後一個字元d,是daemon的意思,代表是伺服器端守護程序模式服務。
- Memcached服務分為伺服器端和客戶端兩部分,其中,伺服器端軟體的名字形如Memcached-1.4.24.tar.gz,客戶端軟體的名字形如Memcache-2.25.tar.gz
- Memcached軟體誕生於2003年,最初由LiveJournal的Brad Fitzpatrick開發完成。Memcache是整個專案的名稱,而Memcached是伺服器端的主程式名,因其協議簡單,應用部署方便,且支援高併發,因此被網際網路企業廣泛使用,直到現在仍然如此。其官方網站地址:http://memcached.org/.
(2)Memcached的作用
- 傳統場景中,多數Web應用都將資料儲存到關係型資料庫中(例如:MySQL),Web伺服器從中讀取資料並在瀏覽器中顯示。但隨著資料量的增大,訪問的集中,關係型資料庫的負擔就會出現加重,響應緩慢,導致網站開啟延遲等問題,影響使用者體驗。
- 這時就需要Memcached軟體出馬了。使用Memcached的主要目的是,通過在自身記憶體中快取關係型資料庫的查詢結果,減少資料庫被訪問的次數,以提高動態Web應用的速度,提高網站架構的併發能力和可擴充套件性。
- Memcached服務的執行原理是通過在事先規劃好的系統記憶體空間中臨時快取資料庫中的各類資料,以達到減少前端業務服務對資料庫的直接高併發訪問,從而提升大規模網站叢集中動態服務的併發訪問能力。
-生產場景的Memcached服務一般被用來儲存網站中經常被讀取的物件或資料,就像我們的客戶端瀏覽器也會把經常訪問的網頁快取起來一樣,通過記憶體快取來存取物件或資料要比磁碟存取快很多,因為磁碟是機械的,因此,在當今的IT企業中,Memcached的應用範圍很廣泛。
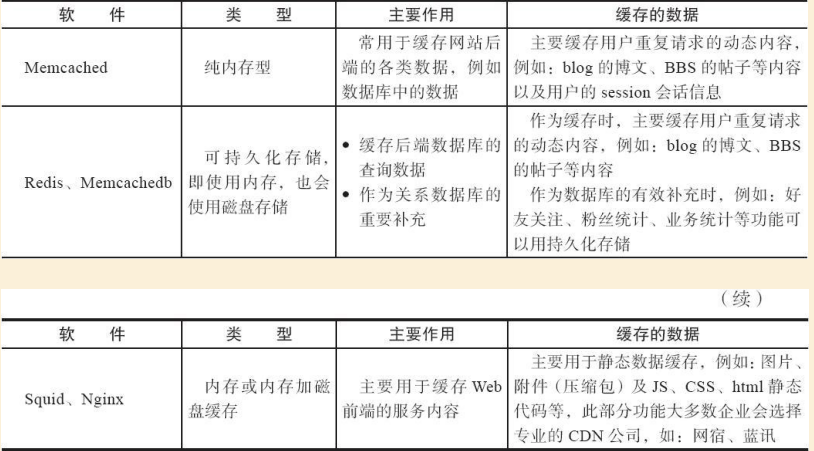
1.2 網際網路常見記憶體快取服務軟體
二,Memcached的用途與應用場景
2.1 Memcached常見用途工作流程
Memcached是一種記憶體快取軟體,在工作中經常用來快取資料庫的查詢資料,資料被快取在事先與分配的Memcached管理的記憶體中,可以通過API或命令的方式存取記憶體中快取的這些資料,Memcached服務記憶體中快取的資料就像一張巨大的hash表,每條資料都是以key-value對的形式存在。
2.1.1網站讀取Memcached資料時工作流程
從邏輯上來說,當程式訪問後端資料庫獲取資料時會優先訪問Memcached快取,如果快取中有資料就直接返回給客戶端使用者,如果沒有合適的資料(沒有命中),再去後端的資料庫讀取資料,讀取到需要的資料後,就會把資料返回給客戶端,同時還會把讀取到的資料快取到Memcached記憶體中,這樣客戶端使用者再次請求相同的資料時就會直接讀取Memcached快取的資料了,這就大大地減輕了後端資料庫的壓力,並提高了整個網站的響應速度,提升了使用者體驗。
展示了Memcached快取系統和後端資料庫系統的協作流程
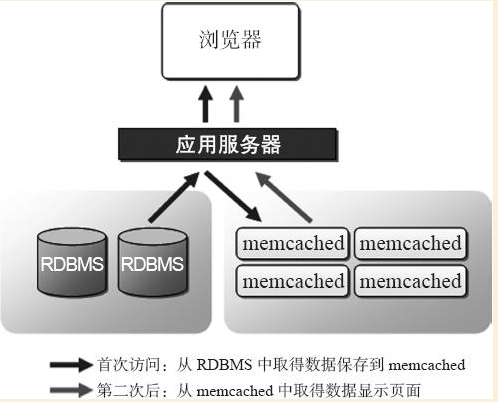
應用伺服器相當於RealServer
RDBMS相當於MySQL
如上圖所示:使用Memcached快取查詢的資料來減少資料庫壓力的具體工作流程如下:
(1)Web程式首先檢查客戶端請求的資料是否在Memcached快取中存在,如果存在,直接把請求的資料返回給客戶端,此時不再請求後端資料庫。
(2)如果請求的資料在Memcached快取中不存在,則程式會去請求資料庫服務,把從資料庫中取到的資料返回給客戶端,同時把新取到的資料快取一份到Memcached快取中。
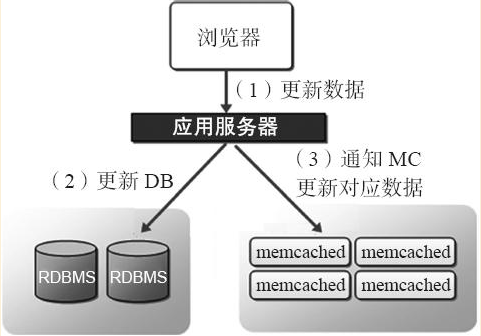
2.1.2 網站更新Memcached資料時的工作流程
(1)當程式更新或刪除資料時,會首先處理後端資料庫中的資料。
(2)在處理後端資料庫中資料的同時,也會通知Memcached,告訴它對應的舊資料失效,從而保證Memcached中快取的資料始終和資料庫中一致,這個資料一致性非常重要,也是大型網站分散式快取叢集最頭疼的問題所在。
(3)如果是在高併發讀寫場合,除了要程式通知Memcached過期的快取失效外,還可能要通過相關機制,例如在資料庫上部署相關程式(如在資料庫中設定觸發器使用UDFs),實現當資料庫有更新時就把資料更新到Memcached服務中,這樣一來,客戶端在訪問新資料時,因預先把更新過的資料庫資料複製到Memcached中快取起來了,所以可以減少第一次查詢資料庫帶來的訪問壓力,提升Memcached中快取的命中率,甚至新浪門戶還會把持久化儲存Redis做成MySQL資料庫的從庫,實現真正的主從複製。
下圖為Memcached網站作為快取應用更新資料的流程
下圖為Memcached服務作為快取應用通過相關軟體更新資料的流程
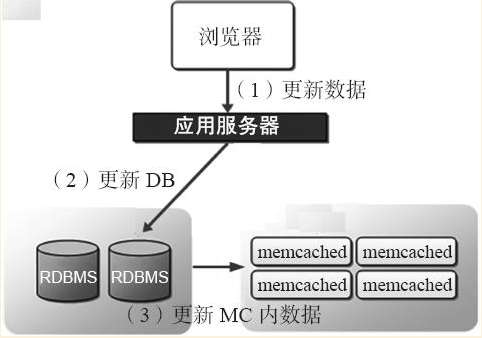
在生產工作中,網站Web伺服器作為快取應用更新資料的方案更為常用,即由網站程式負責更新Memcached快取。
2.2 Memcached在企業中的應用場景
2.2.1 作為資料庫的查詢資料快取
(1)完整資料快取
例如:電商的商品分類功能不是經常變動的,因此可以事先放到Memcached裡,然後再對外提供資料訪問。這個過程被稱之為“資料預熱”。
此時只需讀取快取,無需讀取資料庫就能得到Memcached快取裡的所有商品分類資料了,所以資料庫的訪問壓力就會大大降低。
為什麼商品分類資料可以事先放在快取裡呢?
因為,商品分類幾乎都是由內部人員管理的,如果需要更新資料,更新資料庫後,就可以把資料同時更新到Memcached裡。
如果把商品分類資料做成靜態化檔案,然後,通過在前端Web快取或者使用CDN加速效果更好。
(2)熱點資料快取
熱點資料快取一般是用於由使用者更新的商品,例如淘寶的賣家,在賣家新增商品後,網站程式就會把商品寫入後端資料庫,同時把這部分資料,放入Memcached記憶體中,下一次訪問這個商品的請求就直接從Memcached記憶體中取走了。這種方法用來快取網站熱點的資料,即利用Memcached快取經常被訪問的資料。
提示:
這個過程可以通過程式實現,也可以在資料庫上安裝相關軟體進行設定,直接由資料庫把內容更新到Memcached中,就相當於Memcached是MySQL的從庫一樣。
如果碰到電商雙11,秒殺高併發的業務場景,必須要事先預熱各種快取,包括前端的Web快取和後端的資料庫快取。
也就是先把資料放入記憶體預熱,然後逐步動態更新。此時,會先讀取快取,如果快取裡沒有對應的資料,再去讀取資料庫,然後把讀到的資料放入快取。如果資料庫裡的資料更新,需要同時觸發快取更新,防止給使用者過期的資料,當然對於百萬級別併發還有很多其他的工作要做。
絕大多數的網站動態資料都是儲存在資料庫當中的,每次頻繁地存取資料庫,會導致資料庫效能急劇下降,無法同時服務更多的用過戶(比如MySQL特別頻繁的鎖表就存在此問題),那麼,就可以讓Memcached來分擔資料庫的壓力。增加Memcached服務的好處除了可以分擔資料庫的壓力以外,還包括無須改動整個網站架構,只須簡單地修改下程式邏輯,讓程式先讀取Memcached快取查詢資料即可,當然別忘了,更新資料時也要更新Memcached快取。
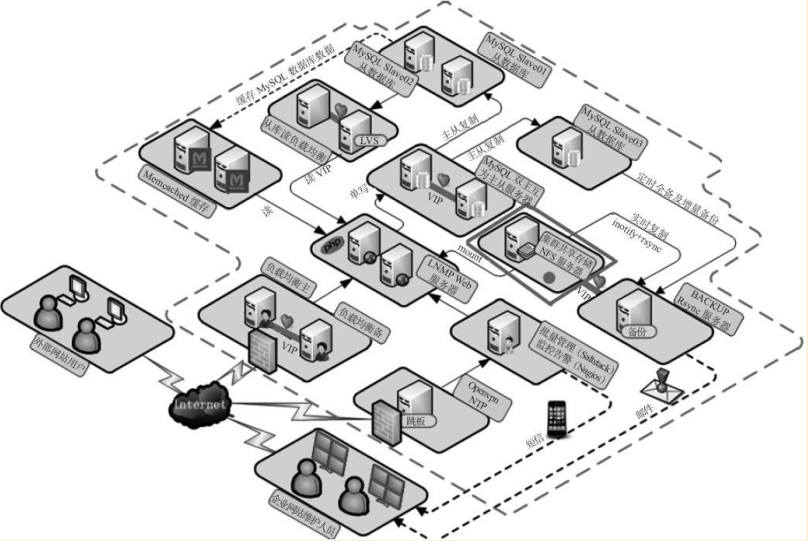
2.2.2 作為叢集節點的session會話共享儲存
即把客戶端使用者請求多個前端應用服務叢集產生的session會話資訊,統一儲存到一個Memcached快取中。由於session會話資料是儲存在記憶體中的,所以速度很快。
下圖為Memcached服務在企業叢集架構中的常見工作位置:
三,Memcached的特點與工作機制
3.1 Memcached的特點
Memcached作為高併發,高效能的快取服務,具有如下特點:
-
協議簡單。Memcached的協議實現很簡單,採用的是基於文字行的協議,能通過telnet/nc等命令直接操作memcached服務儲存資料。
-
支援epoll/kqueue非同步I/O模型,使用libevent作為事件處理通知機制。
-
簡單的說,libevent是一套利用c開發的程式庫,它將BSD系統的kqueue,Linux系統的epoll等事件處理功能封裝成一個介面,確保即使伺服器端的連線數增加也能發揮很好的效能。Memcached就是利用這個libevent庫進行非同步事件處理的。
-
採用key/value鍵值資料型別。被快取的資料以key/value鍵值形式存在,例如
benet-->36,key=benet,value=36yunjisuan-->28,key=yunjisuan,value=28#通過benet key可以獲取到36值,同理通過yunjisuan key可以獲取28值
-
全記憶體快取,效率高。Memcached管理記憶體的方式非常高效,即全部的資料都存放於Memcached服務事先分配好的記憶體中,無持久化儲存的設計,和系統的實體記憶體一樣,當重啟系統或Memcached服務時,Memcached記憶體中的資料就會丟失。
-
如果希望重啟後,資料依然能保留,那麼就可以採用redis這樣的永續性記憶體快取系統。
-
當記憶體中快取的資料容量達到服務啟動時設定的記憶體值時,就會自動使用LRU演算法(最近最少被使用的)刪除過期的快取資料。也可以在存放資料時對儲存的資料設定過期時間,這樣過期後資料就自動被清除,Memcached服務本身不會監控資料過期,而是在訪問的時候檢視key的時間戳判斷是否過期。
-
可支援分散式叢集
Memcached沒有像MySQL那樣的主從複製方式,分散式Memcached叢集的不同伺服器之間是互不通訊的,每一個節點都獨立存取資料,並且資料內容也不一樣。通過對Web應用端的程式設計或者通過支援hash演算法的負載均衡軟體,可以讓Memcached支援大規模海量分散式快取叢集應用。
下面是利用Web端程式實現Memcached分散式的簡單程式碼:
"memcached_servers" ==>array('10.4.4.4:11211','10.4.4.5:11211','10.4.4.6:11211',
下面使用Tengine反向代理負載均衡的一致性雜湊演算法實現分散式Memcached的配置。
http {upstream test {consistent_hash $request_uri;server 127.0.0.1:11211 id=1001 weight=3;server 127.0.0.1:11212 id=1002 weight=10;server 127.0.0.1:11213 id=1003 weight=20;}}
下面使用Tengine反向代理負載均衡的一致性雜湊演算法實現分散式Memcached的配置。
http {upstream test {consistent_hash $request_uri;server 127.0.0.1:11211 id=1001 weight=3;server 127.0.0.1:11212 id=1002 weight=10;server 127.0.0.1:11213 id=1003 weight=20;}}
提示:
Tengine是淘寶網開源的Nginx的分支,上述程式碼來自:
http://tengine.taobao.org/document_cn/http_upstream_consistent_hash_cn.html
3.2 Memcached工作原理與機制
3.2.1 Memcached工作原理
Memcached是一套類似C/S模式架構的軟體,在伺服器端啟動Memcached服務守護程序,可以指定監聽本地的IP地址,埠號,併發訪問連線數,以及分配了多少記憶體來處理客戶端請求。
3.2.2 Socket事件處理機制
Memcached軟體是由C語言來實現的,全部程式碼僅有2000多行,採用的是非同步epoll/kqueue非阻塞I/O網路模型,其實現方式是基於非同步的libevent事件單程序,單執行緒模式。使用libevent作為事件通知機制,應用程式端通過指定伺服器的IP地址及埠,就可以連線Memcached服務進行通訊。
3.2.3 資料儲存機制
需要被快取的資料以key/value鍵值對的形式儲存在伺服器端預分配的記憶體區中,每個被快取的資料都有唯一的標識key,操作Memcached中的資料就是通過這個唯一標識的key進行的。快取到Memcached中的資料僅放置在Memcached服務預分配的記憶體中,而非儲存在Memcached伺服器所在的磁碟上,因此存取速度非常快。
由於Memcached服務自身沒有對快取的資料進行持久化儲存的涉及,因此,在伺服器端的Memcached服務程序重啟之後,儲存在記憶體中的這些資料就會丟失。且當記憶體中快取的資料容量達到啟動時設定的記憶體值時,也會自動使用LRU演算法刪除過期的資料。
開發Memcached的初衷僅是通過記憶體快取提升訪問效率,並沒有過多考慮資料的永久儲存問題。因此,如果使用Memcached作為快取資料服務,要考慮資料丟失後帶來的問題,例如:是否可以重新生成資料,還有,在高併發場合下快取宕機或重啟會不會導致大量請求直接到資料庫,導致資料庫無法承受,最終導致網站架構雪崩等。
3.2.4 記憶體管理機制
Memcached採用瞭如下機制:
-
採用slab(動態)記憶體分配機制
-
採用LRU(演算法)物件清除機制
-
採用hash機制快速檢索item(通過MySQL索引查詢資料)
3.2.5 多執行緒處理機制
-
多執行緒處理時採用的是pthread(POSIX)執行緒模式。
-
若要啟用多執行緒,可在編譯時指定:./configure --enable-threads
-
鎖機制不夠完善
-
負載過重時,可以開啟多執行緒(-t 執行緒數為CPU核數)
3.3 Memcached預熱理念及叢集節點的正確重啟方法
3.3.1 Memcached預熱理念
- 當需要大面積重啟Memcached時,首先要在前端控制網站入口的訪問流量,然後,重啟Memcached叢集並進行資料預熱,所有資料都預熱完畢之後,再逐步放開前端網站入口的流量。
- 為了滿足Memcached服務資料可以持久化儲存的需求,在較早時期,新浪網基於Memcached服務開發了一款NoSQL軟體,名字為MemcacheDB,實現了在快取的基礎上增加了持久儲存的特性,不過目前逐步被更優秀的Redis軟體取代了。
3.3.2 如何正確開啟網站叢集伺服器
如果由於機房斷電或者搬遷伺服器叢集到新機房,那麼啟動叢集伺服器時,一定要從網站叢集的後端依次往前端開啟,特別是開啟Memcached快取伺服器時要提前預熱。
四,Memcached記憶體管理
4.1 Memcached記憶體管理機制深入剖析
(1)Malloc記憶體管理機制
在講解Memcached記憶體管理機制前,先來了解malloc
malloc的全稱是memory allocation,中文名稱動態記憶體分配,當無法知道記憶體具體位置的時候,想要繫結真正的記憶體空間,就需要用到動態分配記憶體。
早期的Memcached記憶體管理是通過malloc分配的記憶體實現的1,使用完後通過free來回收記憶體。這種方式容易產生記憶體碎片並降低作業系統對記憶體的管理效率。因此,也會加重作業系統記憶體管理器的負擔,最壞的情況下,會導致作業系統比Memcached程序本身還慢,為了解決上述問題,Slab Allocator記憶體分配機制就誕生了。
(2)Slab記憶體管理機制
現在的Memcached是利用Slab Allocation機制來分配和管理記憶體的,過程如下:
1)提前將大記憶體分配大小為1MB的若干個slab,然後針對每個slab再進行小物件填充,這個小物件稱為chunk,避免大量重複的初始化和清理,減輕了記憶體管理器的負擔。
Slab Allocation記憶體分配的原理是按照預先規定的大小,將分配給Memcached服務的記憶體預先分割成特定長度的記憶體塊(chunk),再把尺寸相同的記憶體塊(chunk)分成組(chunks slab class),這些記憶體塊不會釋放,可以重複利用,如下圖所示。

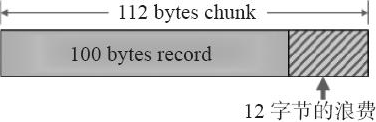
2)新增資料物件儲存時。因Memcached伺服器中儲存著slab內空閒chunk的列表,他會根據該列表選擇chunk,然後將資料緩存於其中。當有資料存入時,Memcached根據接收到的資料大小,選擇最適合資料大小的slab分配一個能存下這個資料的最小記憶體塊(chunk)。例如:有100位元組的一個數據,就會被分配存入下面112位元組的一個記憶體塊中,這樣會有12位元組被浪費,這部分空間就不能被使用了,這也是Slab Allocator機制的一個缺點。
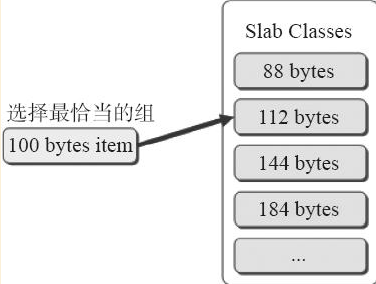
Slab Allocator還可重複使用已分配的記憶體,即分配到的記憶體不釋放,而是重複利用。
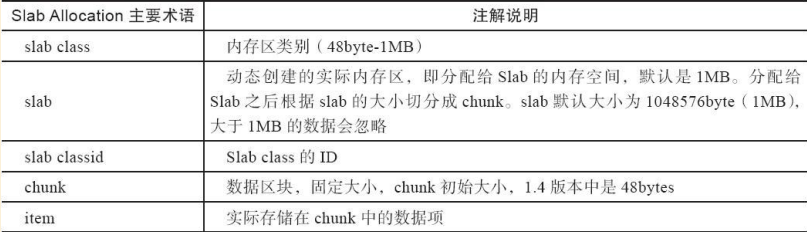
(3)Slab Allocation的主要術語
(4)Slab 記憶體管理機制特點
-
提前分配大記憶體Slab 1MB,再進行小物件填充chunk。
-
避免大量重複的初始化和清理,減輕記憶體管理器負擔。
-
避免頻繁malloc/free記憶體分配導致的碎片
下面對Mc的記憶體管理機制進行一個小結
-
Mc的早期記憶體管理機制為malloc(動態記憶體分配)
-
malloc(動態記憶體分配)產生記憶體碎片,導致作業系統效能急劇下降。
-
Slab記憶體分配機制可以解決記憶體碎片的問題
-
Memcached服務的記憶體預先分割成特定長度的記憶體塊,稱為chunk,用於快取資料的記憶體空間或記憶體塊,相當於磁碟的block,只不過磁碟的每一個block都是相等的,而chunk只有在同一個Slab Class內才是相等的。
-
Slab Class指特定大小(1MB)的包含多個chunk的集合或組,一個Memcached包含多個Slab Class,每個Slab Class包含多個相同大小的chunk。
-
Slab機制也有缺點,例如,Chunk的空間會有浪費等。
4.2 Memcached Slab Allocator記憶體管理機制的缺點
(1)chunk儲存item浪費空間
Slab Allocator解決了當初的記憶體碎片問題,但新的機制也給Memcached帶來了新的問題。這個問題就是,由於分配的是特定長度的記憶體,因此無法有效利用分配的記憶體。例如,將100位元組的資料快取到128位元組的chunk中,剩餘的28位元組就浪費了,如下圖所示:
避免浪費記憶體的辦法是,預先計算出應用存入的資料大小,或把同一業務型別的資料存入一個Memcached伺服器中,確保存入的資料大小相對均勻,這樣就可以減少記憶體的浪費。
還有一種辦法是,在啟動時指定“-f”引數,能在某種程度上控制記憶體組之間的大小差異。在應用中使用Memcached時,通常可以不重新設定這個引數,即使用預設值1.25進行部署即可。如果想優化Memcached對記憶體的使用,可以考慮重新計算資料的預期平均長度,調整這個引數來獲得合適的設定值,命令如下:
-f <factor>chunk size growth factor (default:1.25)!
(2)Slab尾部剩餘空間
- 假設在classid=40中,兩個chunk佔用了1009384byte,那麼就有1048576-1009384=39192byte會被浪費掉。解決辦法:規劃slab大小=chunk大小*n整數倍。
4.3 使用Growth Factor對Slab Allocator記憶體管理機制調優
在啟動Memcached時指定Growth Factor因子(通過 -f 選項),就可以在某種程度上控制每組Slab之間的差異。預設值1.25。但是,在該選項出現之前,這個因子曾經被固定為2,稱為2“powers of 2”策略。讓我們用以前的設定,以verbose模式啟動Memcached試試看:
#memcached -f 2 w
下面是啟動後的verbose輸出:
slab class 1:chunk size 128 perslab 8192slab class 2:chunk size 256 perslab 4096slab class 3:chunk size 512 perslab 2048slab class 4:chunk size 1024 perslab 1024slab class 5:chunk size 2048 perslab 512slab class 6:chunk size 4096 perslab 256slab class 7:chunk size 8192 perslab 128slab class 8:chunk size 16384 perslab 64slab class 9:chunk size 32768 perslab 32slab class 10:chunk size 65536 perslab 16slab class 11:chunk size 131072 perslab 8slab class 12:chunk size 262144 perslab 4slab class 13:chunk size 524288 perslab 2
可見,從128位元組的組開始,組的大小依次增大為原來的2倍。這樣設定的問題是,Slab之間的差別比較大,有些情況下就相當浪費記憶體。因此,為儘量減少記憶體浪費,兩年前追加了growth factor這個選項。
來看看現在的預設設定(f=1.25)時的輸出:
slab class 1:chunk size 88 perslab 11915 <---88*11915=1048520slab class 2:chunk size 112 perslab 9362slab class 3:chunk size 144 perslab 7281slab class 4:chunk size 184 perslab 5698slab class 5:chunk size 232 perslab 4519slab class 6:chunk size 296 perslab 3542slab class 7:chunk size 376 perslab 2788slab class 8:chunk size 472 perslab 2221slab class 9:chunk size 592 perslab 1771slab class 10:chunk size 744 perslab 1409 <---744*1409=1048520
此時每個Slab的大小是一樣的,即1048520,1MB。組間的差距比因子為2時小得多,可見,這個值越小,Slab中chunk size的差距就越小,記憶體浪費也就越小。可見,預設值1.25更適合快取幾百位元組的物件。從上面的輸出結果來看,可能會覺得有些計算誤差,這些誤差是為了保持位元組數的對齊而故意設定的。
當使用Memcached或是直接使用預設值進行部署時,最好是重新計算一下資料的預期平均長度,調整growth factor,以獲得最恰當的設定。記憶體是珍貴的資源,浪費就太可惜了。
4.4 Memcached的檢測過期與刪除機制
(1)Memcached懶惰檢測物件過期機制
首先要知道,Memcached不會主動檢測item物件是否過期,而是在進行get操作時檢查item物件是否過期以及是否應該刪除!
因為不會主動檢測item物件是否過期,自然也就不會釋放已分配給物件的記憶體空間了,除非為新增的資料設定過期時間或記憶體快取滿了,在資料過期後,客戶端不能通過key取出它的值,其儲存空間將被重新利用。
Memcached使用的這種策略為懶惰檢測物件過期策略,即自己不監控存入的key/value對是否過期,而是在獲取key值時檢視記錄的時間戳(sed key flag exptime bytes),從而檢查key/value對空間是否過期。這種策略不會在過期檢測上浪費CPU資源。
(2)Memcached懶惰刪除物件機制
當刪除item物件時,一般不會釋放記憶體空間,而是做刪除標記,將指標放入slot回收插槽,下次分配的時候直接使用。
Memcached在分配空間時,會優先使用已經過期的key/value對空間;若分配的記憶體空間佔滿,Memcached就會使用LRU演算法來分配空間,刪除最近最少使用的key/value對,從而將其空間分配給新的key/value對。在某些情況下(完整快取),如果不想使用LRU演算法,那麼可以通過“-M”引數來啟動Memcached,這樣,Memcached在記憶體耗盡時,會返回一個報錯資訊,如下
-M rerurn error on memory exhausted(rather than removing items)
下面針對Memcached刪除機制進行一個小結
-
不主動檢測item物件是否過期,而是在get時才會檢查item物件是否過期以及是否應該刪除。
-
當刪除item物件時,一般不釋放記憶體空間,而是做刪除標記,將指標放入slot回收插槽,下次分配的時候直接使用。
-
當記憶體空間滿的時候,將會根據LRU(最近最少使用)演算法把最近最少使用的item物件刪除。
-
資料存入可以設定過期時間,但是資料過期後不會被立即刪除,而是在get時檢查item物件是否過期以及是否應該刪除。
-
如果不希望系統使用LRU演算法清除資料,可以用使用-M引數。
五,Memcached服務安裝
Memcached的安裝比較簡單,支援Memcached的平臺常見的有Linux,FreeBSD,Solaris,Windows。這裡以Centos6.5為例進行講解。
Memcached所有包下載地址
連結:https://pan.baidu.com/s/16uvApZWz_E8_0mbiB5bZog
提取碼:lgxd
5.1 安裝libevent及連線Memcached工具nc
系統安裝環境
cat /etc/redhat-release
uname -r
hostname -I
安裝Memcached相關軟體包
安裝Memcached前需要先安裝libevent,有關libevent的內容在前文已經介紹,此處用yum命令安裝libevent。操作命令如下:
yum -y install libevent libevent-devel nc --->自帶光盤裡沒有,需要公網yum源
rpm -qa libevent libevent-devel nc

5.2 安裝Memcached
yum -y install memcached --->可通過光碟安裝
提示:
形如“memcache-2.2.7.tgz”檔名的軟體為客戶端原始碼軟體,而形如“memcached-1.4.24.tar.gz”的檔案為伺服器端的原始碼軟體。
六,Memcached服務的基本管理
6.1 啟動Memcached
which memcached --->檢視Memcached命令路徑
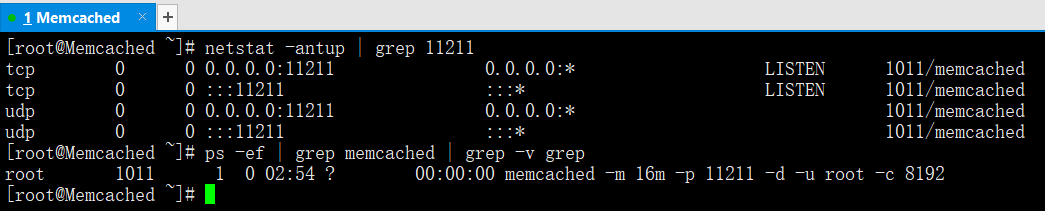
memcached -m 16m -p 11211 -d -u root -c 8192
-m 啟動16兆記憶體 -p 預設埠11211 -d 啟動守護程序 -u 指定使用者 -c 指定連線數
啟動第一個Memcached例項
netstat -antup | grep 11211 --->檢視啟動情況
ps -ef | grep memcached | grep -v grep
啟動第二個Memcached例項
memcached -m 16m -p 11212 -d -u root -c 8192
ps -ef | grep memcached | grep -v grep

可把上述兩個例項的啟動命令放入/etc/rc.local,以便下次開機可以自啟動
tail -2 /etc/rc.local
memcached -m 16m -p 11211 -d -u root -c 8192
memcached -m 16m -p 11212 -d -u root -c 8192
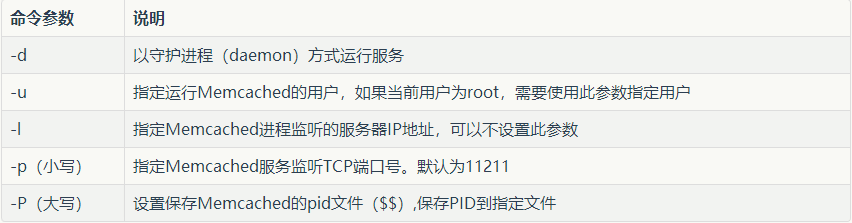
6.2 Memcached啟動命令相關引數說明
程序與連線設定:
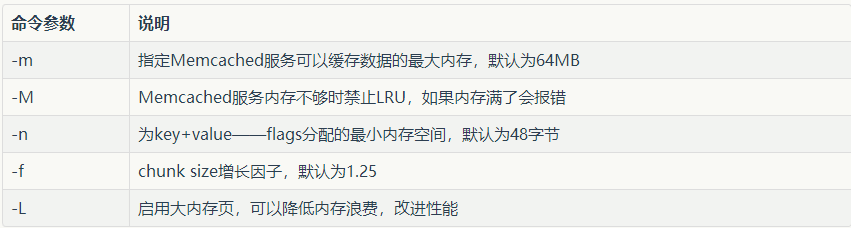
記憶體相關設定:
併發連線設定:

測試引數:

其他選項可通過“memcached -h”命令來顯示。
6.3 向Memcached中寫入資料並檢查
6.3.1 Memcached中的資料形式及與MySQL相關語句對比
向Memcached中新增資料時,注意新增的資料一般為鍵值對的形式,例如:key1-->values1,key2-->values2
這裡把Memcached新增,查詢,刪除等的命令和MySQL資料庫做一個基本類比,見下表:

6.3.2 向Memcached中寫入資料實踐
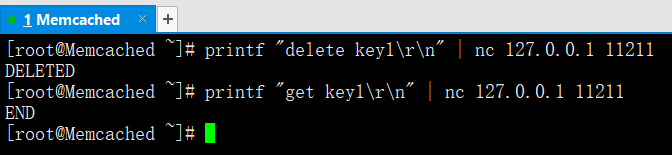
(1)通過printf配合nc向Memcached中寫入資料,命令如下:**
printf "set key1 0 0 5\r\nbenet\r\n" | nc 127.0.0.1 11211
STORED --->出現STORED表示成功新增key1及對應的資料
printf和echo的區別是printf不會輸出換行符 nc是連線memcached的

如果set命令的位元組是5,那麼後面就要5個字元(位元組)。否則插入資料就會不成功
printf "set key1 0 0 4\r\nbenet\r\n" | nc 127.0.0.1 11211

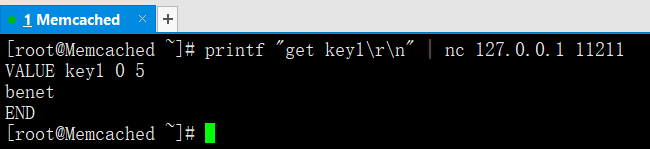
通過printf配置nc從Memcached中讀取資料
printf "get key1\r\n" | nc 127.0.0.1 11211
VALUE key1 0 5
benet #這就是讀取到的key1對應額值
通過printf配合nc從Memcached中刪除資料
printf "delete key1\r\n" | nc 127.0.0.1 11211
printf "get key1\r\n" | nc 127.0.0.1 11211
提示:
推薦使用上述方法測試操作Memcached,只支援鍵值的讀取方式別的不支援
(2)通過telnet命令寫入資料時,具體步驟如下
1)安裝telnet工具
yum -y install telnet
2)通過telnet向Memcached中寫入資料
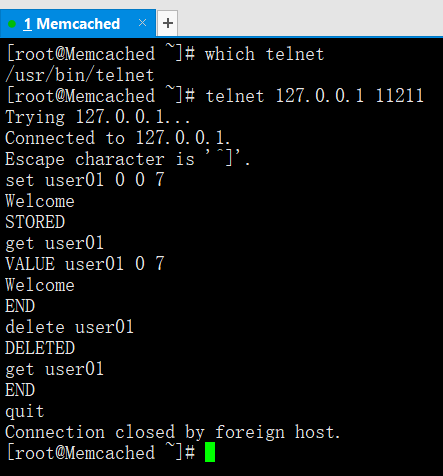
which telnet
telnet 127.0.0.1 11211
Trying 127.0.0.1... --->如果到這裡代表未成功
Escape character is '^]'. --->連線成功
set user01 0 0 7 --->寫入資料
user01 --->鍵
get user01 --->瀏覽資料
delete user01 --->刪除資料
get user01 --->再瀏覽資料,資料被刪除
quit --->退出
Connection closed by foreign host. --->退出提示
6.4 操作Memcached相關命令的語法
以下為操作Memcached的相關命令基本語法
set key1 0 0 6 \r\n benet \r\n<command name><key><flags><exptime><bytes><datablock><string><datablock>STORED<status>
下表為操作Memcached相關命令的詳細說明

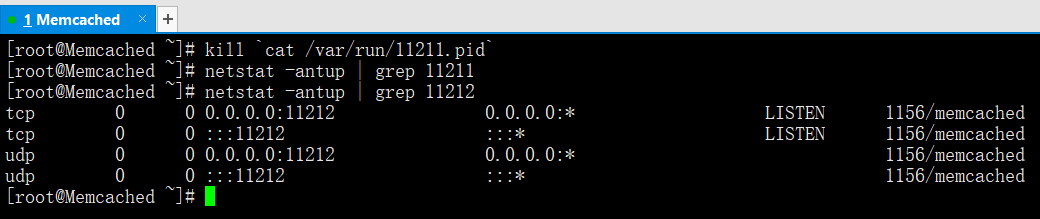
6.5 關閉Memcached
單例項關閉Memcached的方法(直接殺主程序方式)
ps -ef | grep memcached | grep -v grep
killall memcached或pkill memcached
netstat -antup | grep 11211

若啟動了多個例項Memcached,使用killall或pkill方式就會同時關閉這些例項!因此最好在啟動時增加-P引數指定固定的pid檔案,這樣便於管理不同的例項。
memcached -m 16m -p 11211 -d -u root -c 8192 -P /var/run/11211.pid
memcached -m 16m -p 11212 -d -u root -c 8192 -P /var/run/11212.pid
ps -ef | grep memcached | grep -v grep
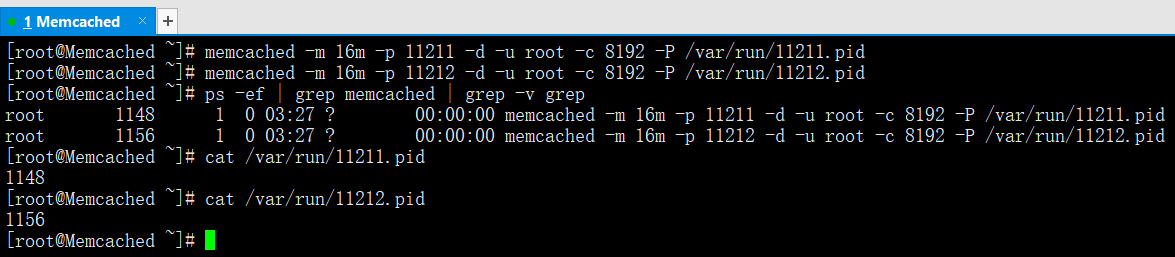
此時,即可通過kill命令關閉Memcached
kill `cat /var/run/11211.pid`
netstat -antup | grep 11211
netstat -antup | grep 11212