詳解如何用爬蟲採集視訊播放量資料(以騰訊視訊為例)
現代社會提到大資料大家都知道這是近幾年才形成的對於資料相關的新名詞,在1980年,著名未來學家阿爾文·托夫勒便在 《第三次浪潮》一書中,將大資料熱情地讚頌為“第三次浪潮的 華彩樂章”。在 20 世紀 80 年代我國已經有一些專家學者談到了海量資料的加工和管理,但是由於計算機技術和網路技術的限制大資料未能引起足夠的重視,它蘊藏的巨大資訊資源也暫時隱藏了起來。隨著雲端計算技術的發展,網際網路的應用越來越廣泛,以微博和部落格為代表的新型社交網路的出現和快速發展,以及以智慧手機、平板電腦為代表的新型移動裝置的出現, 計算機應用產生的資料量呈現了爆炸性增長的趨勢。2012年末出版的《大資料時代》的作者英國牛津大學網路學院網際網路 研究所治理與監管專業教授維克托·爾耶·舍恩伯格在書的引言中說,大資料正在改變人們的生活以及理解世界的方式,而更多的改變正蓄勢待發。
大資料蘊含著巨大的價值,對社會、經濟、科學研究等各個方面都具有重要的戰略意義。目前,大資料已經在政府公共管理、醫療服務、零售業、製造業,以及涉及個人的位置服務等領域得到了廣泛應用,併產生了巨大的社會價值和產業空間。麥肯錫公司在一份研究報告中,根據西方產業資料預測,大資料的應用將能為歐洲發達國家的政府節省1000億歐元以上的運作成本,使美國醫療保健行業的成本降低8%,約每年3000多億美元,並使得零售商的營業利潤率提高60%以上。市場調研機構IDC的“數字宇宙”研究報告中則預測,大資料技術與服務市場在2015年將達到169億美元,實現40%的年增長率,為IT與通訊產業增長率的7倍。大資料中蘊含的巨大商業價值、科學研究價值、社會管理與公共服務價值以及支撐科學決策的價值正在被認知與開發利用。
資料中蘊含的寶貴价值成為人們儲存和處理大資料的驅動力。Mayer-Schonberger 在《大資料時代》一書中指出了大資料時代處理資料理念的三大轉變,即要全體不要抽樣,要效率不要絕對精確,要相關不要因果。因此,大資料的處理對於當前存在的技術來說是一種極大的挑戰。
那麼我們如何獲取這些資料呢,有沒有什麼高效的辦法可以幫助我們獲取這些高價值的資料,畢竟人工的複製黏貼不僅複雜而且非常的低效,因此後羿工程師團隊不斷的摸索和開發,終於研究出一款基於人工智慧技術的爬蟲工具,只需要在軟體中輸入網址就能夠自動識別網頁資料,無需配置即可完成資料採集,是業內首家支援三種作業系統(包括Windows、Mac和Linux)的採集軟體。同時這是一款真正免費的資料採集軟體,對採集結果匯出沒有任何限制,即使是沒有程式設計基礎的小白使用者也可輕鬆實現資料採集要求。
現在我們就以騰訊視訊為例,為大家演示如何使用此款軟體。
首先,複製需要採集的網址,開啟軟體輸入網址,新建智慧採集任務。

在智慧模式下,我們輸入網址後軟體即可自動識別出頁面上的資料並生成採集結果,每一類資料對應一個採集欄位,我們可以右擊欄位進行相關設定,包括修改欄位名稱、增減欄位、處理資料等。

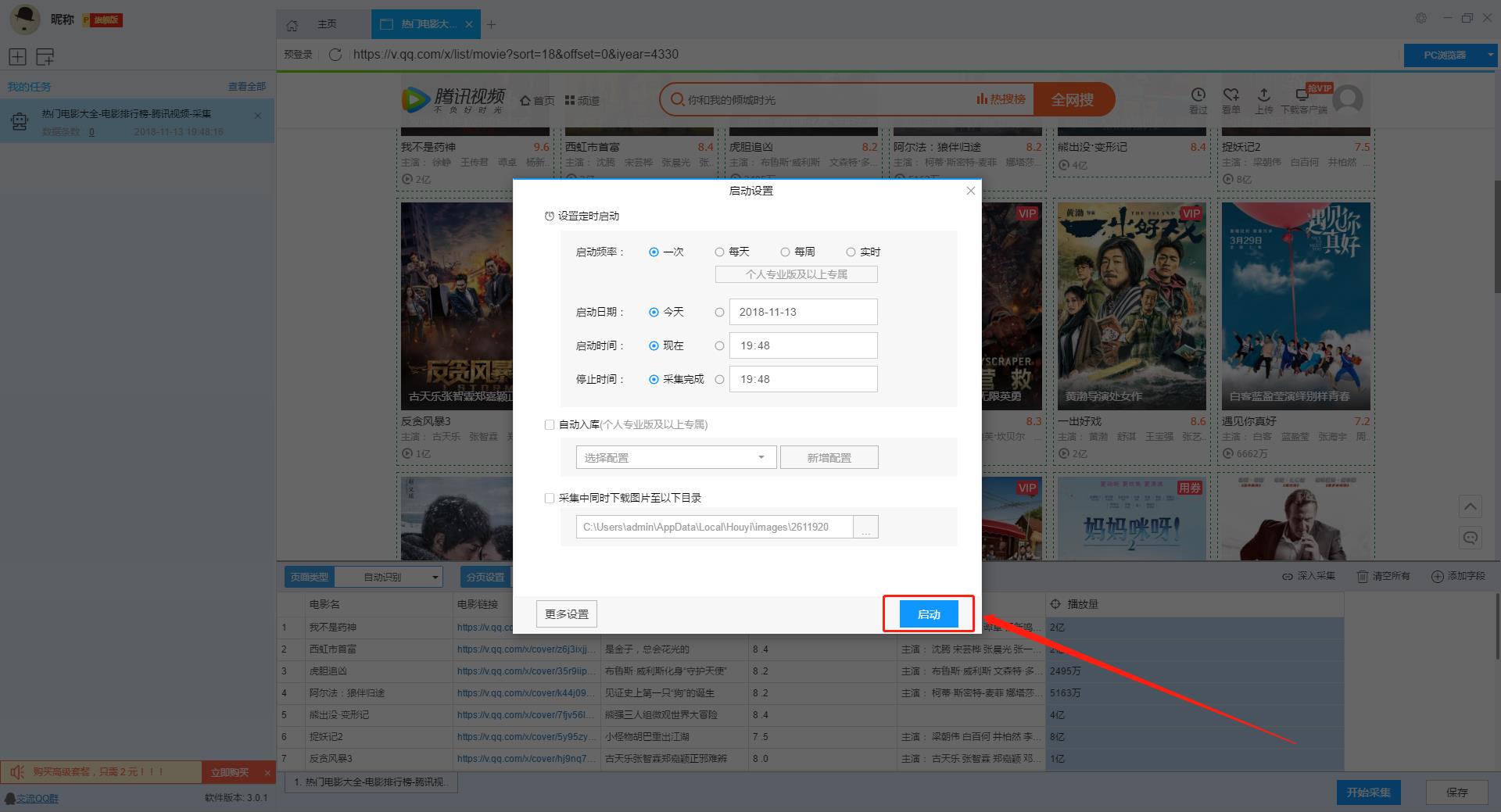
接著我們點選“儲存並啟動”按鈕,可在彈出的頁面中進行一些高階設定,包括定時啟動、自動入庫和下載圖片,本次示例中未使用到這些功能,直接點選“啟動”執行爬蟲工具。
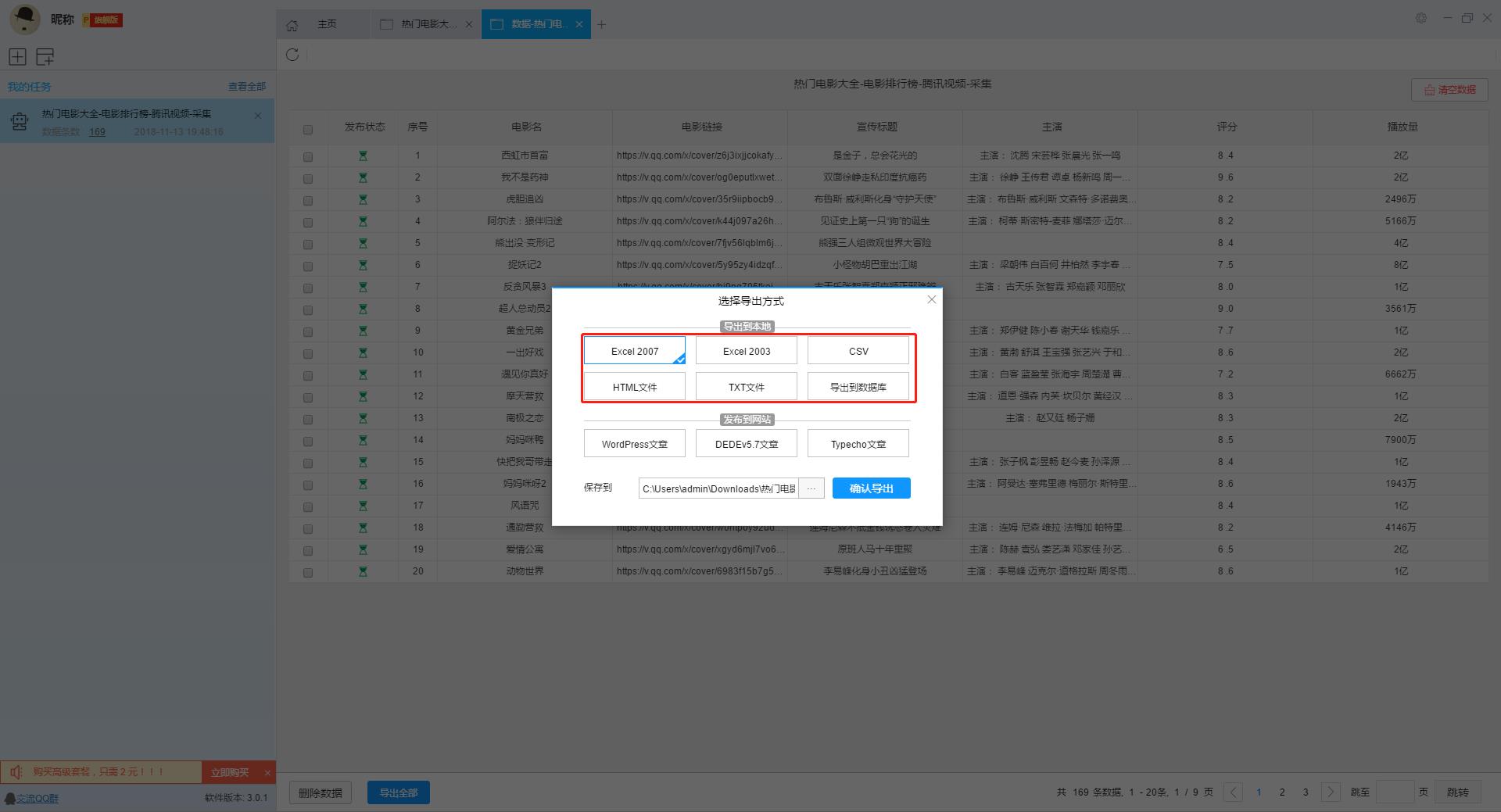
資料採集完畢後,我們可以匯出資料,軟體提供多種匯出方式,大家可以自由選擇匯出方式。
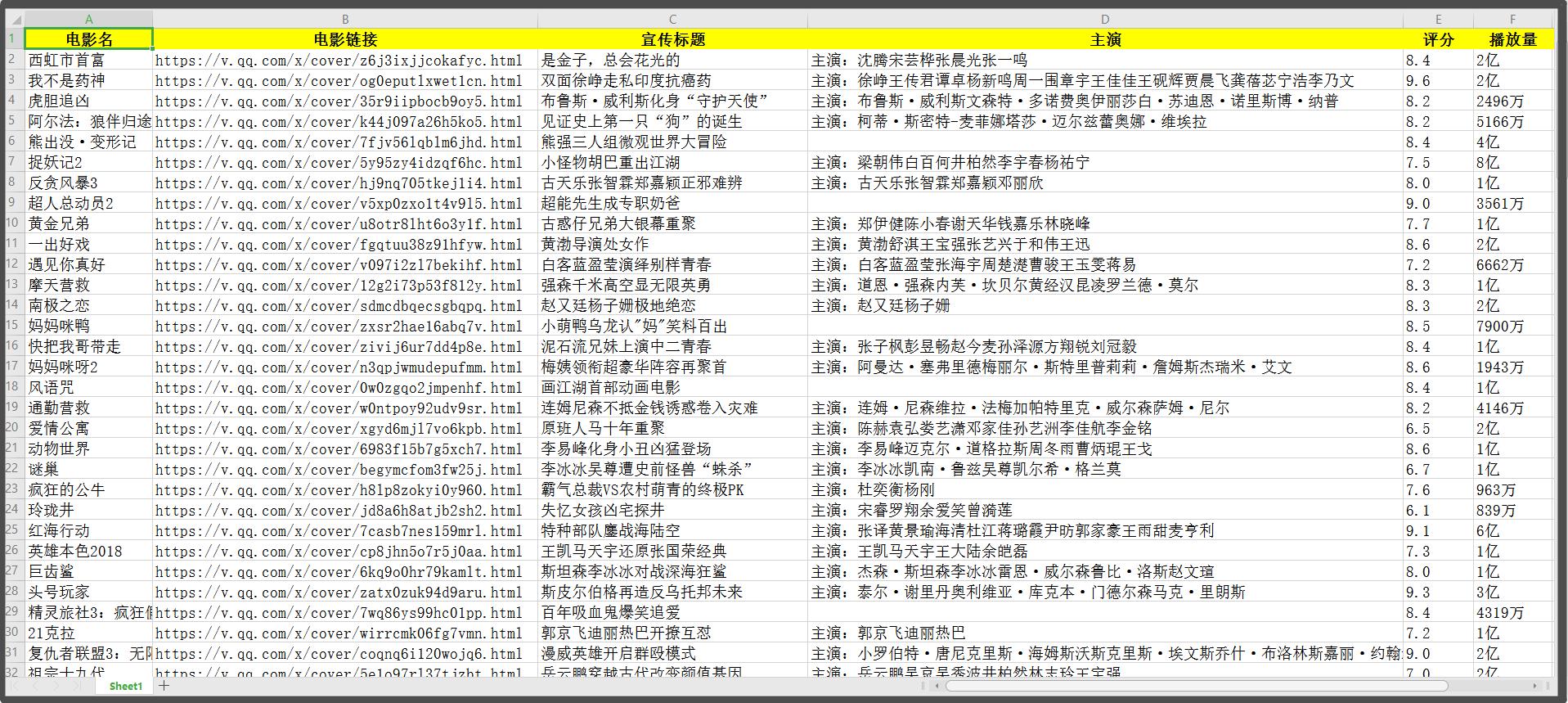
我們匯出了一個Excel表格的檔案,在這個表格上我們可以看到資料都完整的採集出來了,大家可以直接使用這些資料,也可以在這個基礎上對資料進行加工處理。