
【NLP】【七】fasttext原始碼解析
【一】關於fasttext
fasttext是Facebook開源的一個工具包,用於詞向量訓練和文字分類。該工具包使用C++11編寫,全部使用C++11 STL(這裡主要是thread庫),不依賴任何第三方庫。具體使用方法見:https://fasttext.cc/ ,在Linux 使用非常方便。fasttext不僅提供了軟體原始碼,還提供了訓練好的一些模型(多語種的詞向量:英文、中文等150餘種)
原始碼地址:https://github.com/facebookresearch/fastText/
gensim也對該功能進行了封裝,可以直接使用。
fasttext的原始碼實現非常優雅,分析原始碼,帶來以下幾方面的收穫:
1. 如何組織文字資料?
2. CBOW和skip-gram是如何實現的?
3. 模型如何量化?
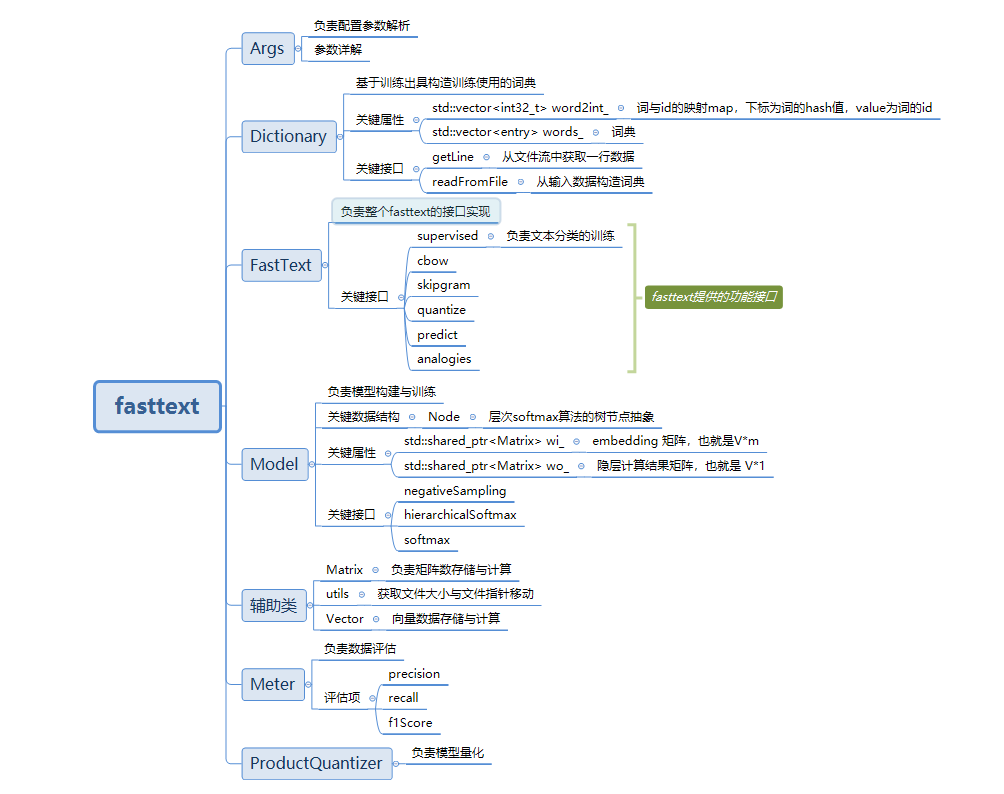
【二】fasttext整體結構
【三】fasttext引數配置
主要引數如下:

具體引數使用可以參考:https://fasttext.cc/docs/en/support.html
【四】dict相關原始碼分析
1. 從輸入資料構造詞典的整體流程
void Dictionary::readFromFile(std::istream& in) { std::string word; int64_t minThreshold = 1; // 1. 逐詞讀取 while (readWord(in, word)) { // 2. 將詞新增到詞典中 add(word); if (ntokens_ % 1000000 == 0 && args_->verbose > 1) { std::cerr << "\rRead " << ntokens_ / 1000000 << "M words" << std::flush; } // 如果超出詞典容量,則去除低頻詞 if (size_ > 0.75 * MAX_VOCAB_SIZE) { minThreshold++; // 去除低頻詞 threshold(minThreshold, minThreshold); } } // 去除低頻詞,並按照詞頻降序排序 threshold(args_->minCount, args_->minCountLabel); initTableDiscard(); // 基於n-gram,初始化sub-word initNgrams(); if (args_->verbose > 0) { std::cerr << "\rRead " << ntokens_ / 1000000 << "M words" << std::endl; std::cerr << "Number of words: " << nwords_ << std::endl; std::cerr << "Number of labels: " << nlabels_ << std::endl; } if (size_ == 0) { throw std::invalid_argument( "Empty vocabulary. Try a smaller -minCount value."); } }
2. 面對不同的語言,如何讀取一個詞?
// 1. 對於詞向量訓練,需要先分詞,然後詞之前用空格隔開 bool Dictionary::readWord(std::istream& in, std::string& word) const { int c; // 1. 獲取檔案流的data指標 std::streambuf& sb = *in.rdbuf(); word.clear(); // 2. 迴圈讀取,每次從檔案流中讀取一個char while ((c = sb.sbumpc()) != EOF) { // 3. 對c讀取的字元做不同的處理,如果不是空格等,則繼續讀取下一個字元 if (c == ' ' || c == '\n' || c == '\r' || c == '\t' || c == '\v' || c == '\f' || c == '\0') { if (word.empty()) { if (c == '\n') { word += EOS; return true; } continue; } else { if (c == '\n') sb.sungetc(); return true; } } // 4. 將char新增到word中,繼續讀取下一個字元 word.push_back(c); } // trigger eofbit in.get(); return !word.empty(); }
3. 如何將一個詞新增到詞典中?
void Dictionary::add(const std::string& w) {
// 1. 通過find獲取詞的hash值
int32_t h = find(w);
ntokens_++;
// 2. 通過hash值,查詢該詞是否在表word2int_中。
// 該表的下標為詞的hash值,value為詞的id,容量為 MAX_VOCAB_SIZE
if (word2int_[h] == -1) {
// 3. 新詞,將其新增到詞典 words_中
entry e;
e.word = w;
e.count = 1; // 新詞,詞頻為1
e.type = getType(w); // 詞的型別,分類則為label,詞向量則為word,即將所有的詞放在一個詞典中的
// 沒有分開儲存label與word
words_.push_back(e);
word2int_[h] = size_++; // 新增詞的id,id就是個順序值,和普通的for迴圈中的i作為id是一樣的
} else {
// 詞典中已存在的詞,僅增加詞頻
words_[word2int_[h]].count++;
}
}4. 如何去低頻詞?
void Dictionary::threshold(int64_t t, int64_t tl) {
// 1. 先對詞典中的詞按照詞頻排序,
sort(words_.begin(), words_.end(), [](const entry& e1, const entry& e2) {
if (e1.type != e2.type) {
return e1.type < e2.type;
}
// 詞頻降序排列
return e1.count > e2.count;
});
// 2. 將 word 詞頻小於t的刪除,將label詞頻小於t1的刪除
words_.erase(
remove_if(
words_.begin(),
words_.end(),
[&](const entry& e) {
return (e.type == entry_type::word && e.count < t) ||
(e.type == entry_type::label && e.count < tl);
}),
words_.end());
// 3. 詞典容量調整,前面刪除了部分詞。
words_.shrink_to_fit();
// 4. 重置詞典資料
size_ = 0;
nwords_ = 0;
nlabels_ = 0;
std::fill(word2int_.begin(), word2int_.end(), -1);
// 將詞典中的資料重新計算id值
for (auto it = words_.begin(); it != words_.end(); ++it) {
int32_t h = find(it->word);
word2int_[h] = size_++;
if (it->type == entry_type::word) {
nwords_++;
}
if (it->type == entry_type::label) {
nlabels_++;
}
}
}
5. initTableDiscard
void Dictionary::initTableDiscard() {
// 將 大小調整為詞典大小
pdiscard_.resize(size_);
for (size_t i = 0; i < size_; i++) {
// 計算概率,詞頻/詞總數
real f = real(words_[i].count) / real(ntokens_);
pdiscard_[i] = std::sqrt(args_->t / f) + args_->t / f;
}
}6. initNgrams
void Dictionary::initNgrams() {
for (size_t i = 0; i < size_; i++) {
// 1. 從詞典中獲取一個詞,並給該詞加上"<"與">",例如:北京---->"<北京>"
std::string word = BOW + words_[i].word + EOW;
words_[i].subwords.clear();
// 該詞的子詞列表,首先新增全詞的id,全詞也算一個子詞
words_[i].subwords.push_back(i);
if (words_[i].word != EOS) {
// 依據n-gram,計運算元詞
computeSubwords(word, words_[i].subwords);
}
}
}// word ---->原始的詞
// ngrams --->依據n-gram分割出的子詞,出參
// substrings --->預設值為nullptr
void Dictionary::computeSubwords(
const std::string& word,
std::vector<int32_t>& ngrams,
std::vector<std::string>* substrings) const {
// 1. 獲取詞的大小,一個詞可能是由多個字元組成的
// 例如:word = "<終南山>"
for (size_t i = 0; i < word.size(); i++) {
std::string ngram;
// 2. 這裡是為了解決utf-8編碼問題
// 參考:https://stackoverflow.com/questions/3911536/utf-8-unicode-whats-with-0xc0-and-0x80
if ((word[i] & 0xC0) == 0x80) {
continue;
}
// args_->maxn --->配置引數,表示n-gram中的n的最大值,預設為maxn = 6;
// args_->minn --->配置引數,表示n-gram中的n的最小值,預設為minn = 3;
// args_->bucket--->配置引數,表示bucket = 2000000;
// 進行n-gram切分:例如:終南山---->終南、南山
for (size_t j = i, n = 1; j < word.size() && n <= args_->maxn; n++) {
ngram.push_back(word[j++]);
while (j < word.size() && (word[j] & 0xC0) == 0x80) {
ngram.push_back(word[j++]);
}
if (n >= args_->minn && !(n == 1 && (i == 0 || j == word.size()))) {
int32_t h = hash(ngram) % args_->bucket;
// 這裡面會建立一個sub-word的hash索引
pushHash(ngrams, h);
if (substrings) {
substrings->push_back(ngram);
}
}
}
}
}至此,依據資料資料構建詞典的流程已經完成。主要是完成了word的去重、詞頻統計、詞頻排序、基於n-gram的sub-word預處理、word2id等處理。
【五】train流程分析
1. train的主流程
void FastText::train(const Args args) {
args_ = std::make_shared<Args>(args);
dict_ = std::make_shared<Dictionary>(args_);
if (args_->input == "-") {
// manage expectations
throw std::invalid_argument("Cannot use stdin for training!");
}
std::ifstream ifs(args_->input);
if (!ifs.is_open()) {
throw std::invalid_argument(
args_->input + " cannot be opened for training!");
}
// 1. 詞典構造
dict_->readFromFile(ifs);
ifs.close();
// 2. 如果有與訓練的向量,則載入
if (args_->pretrainedVectors.size() != 0) {
loadVectors(args_->pretrainedVectors);
} else {
// 3. 構造輸入資料矩陣的大小,這裡也就是embidding的大小
// V*m
input_ =
std::make_shared<Matrix>(dict_->nwords() + args_->bucket, args_->dim);
// 初始化詞嵌入矩陣
input_->uniform(1.0 / args_->dim);
}
if (args_->model == model_name::sup) {
// 隱層輸出矩陣大小,分類: n*m,詞向量 V*m
output_ = std::make_shared<Matrix>(dict_->nlabels(), args_->dim);
} else {
output_ = std::make_shared<Matrix>(dict_->nwords(), args_->dim);
}
output_->zero();
// 啟動計算
startThreads();
model_ = std::make_shared<Model>(input_, output_, args_, 0);
if (args_->model == model_name::sup) {
model_->setTargetCounts(dict_->getCounts(entry_type::label));
} else {
model_->setTargetCounts(dict_->getCounts(entry_type::word));
}
}2. 單執行緒訓練流程
void FastText::trainThread(int32_t threadId) {
std::ifstream ifs(args_->input);
// 1. 按照執行緒數,將輸入資料平均分配給各個執行緒,
// 各個執行緒之間不存在資料競爭,英雌不需要加鎖
utils::seek(ifs, threadId * utils::size(ifs) / args_->thread);
// 2. 初始化一個model
Model model(input_, output_, args_, threadId);
// 3. setTargetCounts 介面內部會完成tree或者負取樣的資料初始化
if (args_->model == model_name::sup) {
model.setTargetCounts(dict_->getCounts(entry_type::label));
} else {
model.setTargetCounts(dict_->getCounts(entry_type::word));
}
const int64_t ntokens = dict_->ntokens();
int64_t localTokenCount = 0;
std::vector<int32_t> line, labels;
while (tokenCount_ < args_->epoch * ntokens) {
// 計算處理進度,動態調整學習率
real progress = real(tokenCount_) / (args_->epoch * ntokens);
real lr = args_->lr * (1.0 - progress);
// 每次讀取一行資料,依據模型不同,呼叫不同介面處理
if (args_->model == model_name::sup) {
// 文字分類
localTokenCount += dict_->getLine(ifs, line, labels);
supervised(model, lr, line, labels);
} else if (args_->model == model_name::cbow) {
// cbow
localTokenCount += dict_->getLine(ifs, line, model.rng);
cbow(model, lr, line);
} else if (args_->model == model_name::sg) {
// sg
localTokenCount += dict_->getLine(ifs, line, model.rng);
skipgram(model, lr, line);
}
if (localTokenCount > args_->lrUpdateRate) {
tokenCount_ += localTokenCount;
localTokenCount = 0;
if (threadId == 0 && args_->verbose > 1)
loss_ = model.getLoss();
}
}
if (threadId == 0)
loss_ = model.getLoss();
ifs.close();
}3. 層次softmax的tree的構造
void Model::buildTree(const std::vector<int64_t>& counts) {
tree.resize(2 * osz_ - 1);
for (int32_t i = 0; i < 2 * osz_ - 1; i++) {
tree[i].parent = -1;
tree[i].left = -1;
tree[i].right = -1;
tree[i].count = 1e15;
tree[i].binary = false;
}
for (int32_t i = 0; i < osz_; i++) {
tree[i].count = counts[i];
}
int32_t leaf = osz_ - 1;
int32_t node = osz_;
for (int32_t i = osz_; i < 2 * osz_ - 1; i++) {
int32_t mini[2];
for (int32_t j = 0; j < 2; j++) {
if (leaf >= 0 && tree[leaf].count < tree[node].count) {
mini[j] = leaf--;
} else {
mini[j] = node++;
}
}
tree[i].left = mini[0];
tree[i].right = mini[1];
tree[i].count = tree[mini[0]].count + tree[mini[1]].count;
tree[mini[0]].parent = i;
tree[mini[1]].parent = i;
tree[mini[1]].binary = true;
}
for (int32_t i = 0; i < osz_; i++) {
std::vector<int32_t> path;
std::vector<bool> code;
int32_t j = i;
while (tree[j].parent != -1) {
// 節點路徑,即從root到label的路徑
// 路徑哈夫曼編碼,即從root到label的路徑的哈夫曼編碼
// 後面會借用這兩個變數,計算loss
path.push_back(tree[j].parent - osz_);
code.push_back(tree[j].binary);
j = tree[j].parent;
}
paths.push_back(path);
codes.push_back(code);
}
}4. 負取樣
void Model::initTableNegatives(const std::vector<int64_t>& counts) {
real z = 0.0;
for (size_t i = 0; i < counts.size(); i++) {
z += pow(counts[i], 0.5);
}
for (size_t i = 0; i < counts.size(); i++) {
real c = pow(counts[i], 0.5);
for (size_t j = 0; j < c * NEGATIVE_TABLE_SIZE / z; j++) {
negatives_.push_back(i);
}
}
std::shuffle(negatives_.begin(), negatives_.end(), rng);
}5. 引數更新
void Model::update(const std::vector<int32_t>& input, int32_t target, real lr) {
assert(target >= 0);
assert(target < osz_);
if (input.size() == 0) {
return;
}
// 1. 計算隱層的輸出值。如果是分類,則是labels_number * 1
// 如果是word2vec,則是V*1
computeHidden(input, hidden_);
// 依據模型型別呼叫不同的介面計算loss
if (args_->loss == loss_name::ns) {
loss_ += negativeSampling(target, lr);
} else if (args_->loss == loss_name::hs) {
loss_ += hierarchicalSoftmax(target, lr);
} else {
loss_ += softmax(target, lr);
}
nexamples_ += 1;
// 梯度計算,引數更新
if (args_->model == model_name::sup) {
grad_.mul(1.0 / input.size());
}
for (auto it = input.cbegin(); it != input.cend(); ++it) {
wi_->addRow(grad_, *it, 1.0);
}
}具體計算的程式碼這裡就不分析了。
【六】總結
其餘部分的程式碼(如:預測、評估等),這裡就不分析了,順著程式碼看就可以了。fasttext的程式碼結構還是比較簡單的。程式碼閱讀的難點在於演算法的理解。後續再結合演算法,對程式碼細節做分析。
fasttext是一個很好的工具,但要訓練出一個合適的模型,需要對模型的引數有所理解,然而一般情況下,預設的引數就能滿足要求了。