
面向機器學習資料平臺的設計與搭建
機器學習作為近幾年的一項熱門技術,不僅憑藉眾多“人工智慧”產品而為人所熟知,更是從根本上增能了傳統的網際網路產品。在近期舉辦的2018 ArchSummit全球架構師峰會上,個推首席資料架構師袁凱,基於他在資料平臺的建設以及資料產品研發的多年經驗,分享了《面向機器學習資料平臺的設計與搭建》。
一、背景:機器學習在個推業務中的應用場景
作為獨立的智慧大資料服務商,個推主要業務包括開發者服務、精準營銷服務和各垂直領域的大資料服務。而機器學習技術在多項業務及產品中均有涉及:
1、個推能夠提供基於精準使用者畫像的智慧推送。其中使用者標籤主要是基於機器學習,通過訓練模型後對人群做預測分類;
2、廣告人群定向;
3、商圈景區人流量預測;
4、移動開發領域經常出現虛假裝置,機器學習能夠幫助開發者識別新增的使用者的真偽;
5、個性化內容推薦;
6、使用者流失以及留存週期的預測。
二、具體開展機器學習的過程

1、原始資料經過資料的ETL處理,入庫到資料倉裡。
2、上面藍色部分代表機器學習:首先把樣本資料與我們的自有資料進行匹配,然後洞察這份資料並生成特徵,這個過程叫特徵工程。接下來基於這些特徵,選擇合適的演算法訓練後得到模型,最終把模型具體應用到全量的資料中,輸出預測的結果。
標準的機器學習工作流:針對業務上產生的具體問題,我們把它轉化成資料問題,或者評估它能否用資料來解決。將資料匯入並過濾後,我們需要將資料與業務問題和目標進行相關性分析,並根據具體情況對資料做二次處理。
下一步我們進行特徵工程。從資料裡找出跟目標有關的特徵變數,從而構建或衍生出一些特徵,同時要把無意義的特徵剔除掉。我們大概需要花80%的時間在特徵工程這個環節。選出特徵之後,我們會用邏輯迴歸和RNN等演算法進行模型的訓練。接下來需要對模型做驗證,判斷其是否符合目標。不符合目標的原因有可能是資料和目標不相關,需要重新採集;也有可能是我們在探索的時候,工作不到位,因而需要對現有的資料重新探索,再進行特徵工程這些步驟。如果最終模型符合業務預期,我們會把它應用在業務線上面。

- 機器學習專案落地的常見問題
雖然上面的流程很清晰,但在具體落地的過程中也會遇到很多問題,這裡我就之前的實踐經驗談幾點。
1、現在大部分公司都已經進入大資料的時代,相比於以往的小資料級的階段,在機器學習或者資料探勘等工作方面,對我們的建模人員、演算法專家的技能要求變高,工作難度也大大地提升了。
以往大家自己在單機上就可以完成機器學習的資料預處理、資料分析以及最終機器學習的分析和上線。但在海量資料情況下,可能需要接觸到Hadoop生態圈。
2、做監督學習時,經常需要匹配樣本。資料倉庫裡面的資料可能是萬億級別,提取資料週期非常長,大把的時間要用於等待機器把這些資料抽取出來。
3、大多數情況下,很多業務由一兩個演算法工程師負責挖掘,因而經常會出現不同小組的建模工具不太統一或實現流程不規範的情況。不統一會造成很多程式碼重複率高,建模過程並沒有在團隊裡很好地沉澱下來。
4、很多機器學習演算法工程師的背景存在專業的侷限性,他們可能在程式碼工程化意識和經驗上相對會薄弱一些。常見的做法是:演算法工程師會在實驗階段把特徵生成程式碼和訓練程式碼寫好,交給做工程開發的同學,但這些程式碼無法在全量資料上執行起來。之後工程開發同學會把程式碼重新實現一遍,保證它的高可用和高效。但即便如此,也常常出現翻譯不到位的情況,導致溝通成本高,上線應用週期長
5.機器學習領域的一大難題在於對資料的使用,它的成本非常高,因為我們把大量時間用於探索資料了。
6、個推有多項業務在使用機器學習,但並不統一,會造成重複開發,缺少平臺來沉澱和共享。這就導致已經衍生出來的一些比較好用的特徵,沒有得到廣泛的應用。
四、個推針對機器學習問題的解決方案
首先說一下我們這個平臺的目標:
第一點,我們希望內部的建模流程規範化。
第二點,我們希望提供一個端到端的解決方案,覆蓋從模型的開發到上線應用整個流程。
第三點,我們希望平臺的資料,特別是開發出的特徵資料可以運營起來並在公司內不同團隊間共享使用。
第四點,這個平臺不是面向機器學習零基礎的開發人員,更多的是面向專家和半專家的演算法工程師,讓他們提高建模的效率。同時這個平臺要支援多租戶,確保保障資料安全。
以下是我們自己的整體方案,主要分成兩大塊:
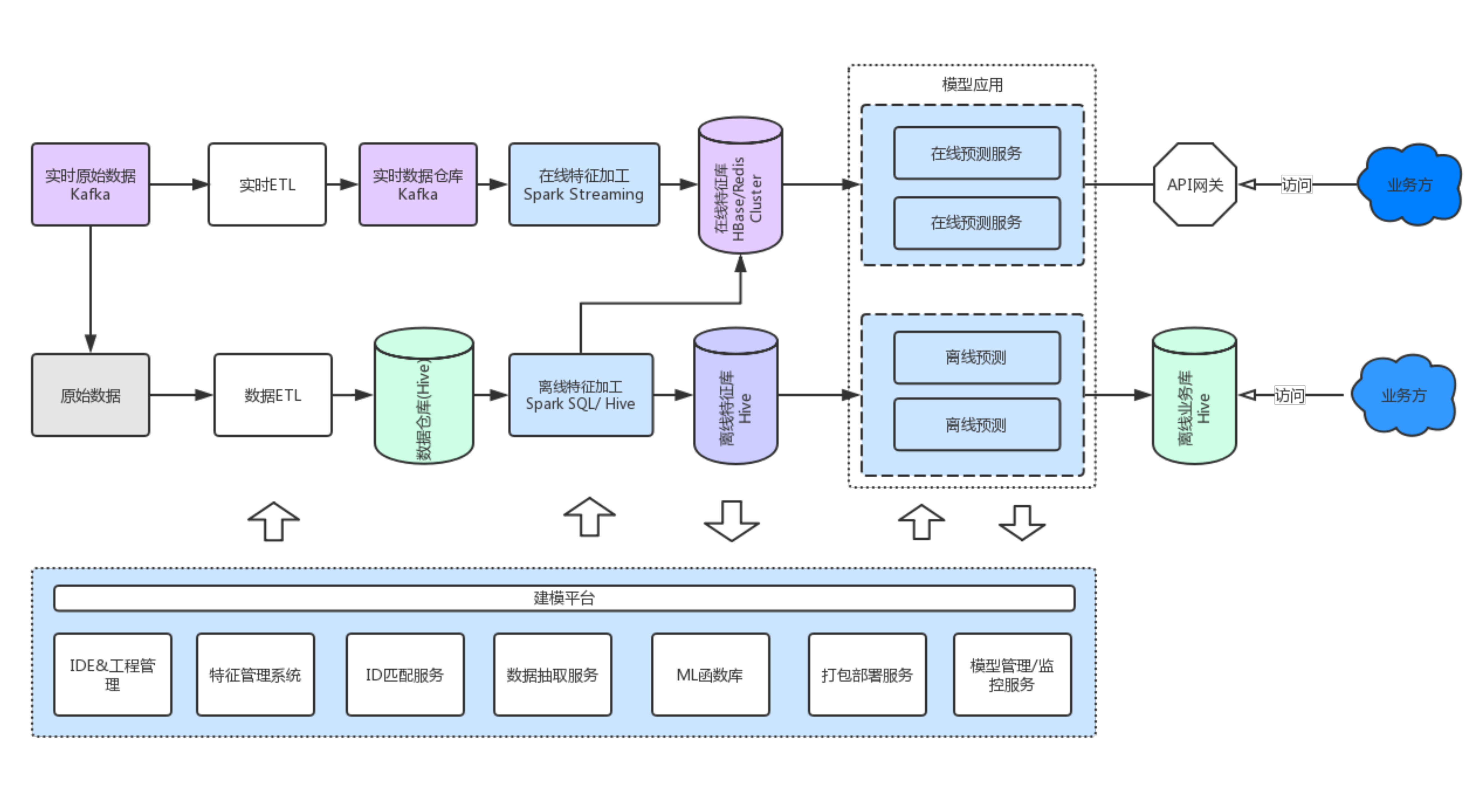
下半部分是建模平臺,也叫實驗平臺,它主要供演算法工程師使用,建模平臺包含:
1、對應IDE。在這個平臺上進行資料探索、做資料的實驗,並且它能支援專案的管理和共享。
2、我們希望把已經開發好的特徵資料管理起來,方便所有平臺使用者看到資料資產的情況。
3、樣本匹配時候,樣本ID可能與內部ID不統一,這個時候需要做統一的ID匹配服務。
4、幫助演算法工程師從萬億級資料裡快速地抽取所需資料,這也是非常重要的一點。
5、做機器學習的過程中,除了基本的演算法,實際上還有很多程式碼是重複或者相似的,我們需要把這些常用程式碼進行函式化封裝。
6、支援對模型服務進行打包部署。
7、模型還要支援版本管理。
8、在實際業務中應用模型,需要實時監控起來,跟進模型的可用性、準確性等。
上半部分是生產環境,執行著資料處理pipeline,同時與資料建模平臺對接著。
在生產環境中,模型對應的特徵資料分兩類:
一類是實時特徵資料,比如資料實時採集,生成一些實時的特徵,根據不同的業務需求儲存在不同的叢集裡。
另一類是離線特徵資料,離線資料加工後存到Hive,供模型應用側進行使用。
在生產環境中,我們可以提供線上的預測API或 離線預測好的資料 供業務線使用。
五、方案實踐具體要點
第一點,我們講講jupyter這塊:
選擇Jupyter作為主要建模IDE而不是自研視覺化拖拽建模工具,這樣的好處是可以做互動式的分析,建模效率也很高,擴充套件方便,研發成本低。當然類似微軟Azure這樣的視覺化拖拽建模平臺,可以非常清晰地看到整個流程,適合入門級同學快速上手。但我們的目標使用者是專家和半專家群體,所以我們選擇了最合適的Jupyter。
使用Jupyter時候,為了支援多租戶,我們採用Jupyterhub。底層機器學習框架我們用了Tensorflow、Pyspark、Sklearn等。資料處理探索時候,結合sparkmagic,可以非常方便地將寫在Jupyter上的Spark程式碼執行到Spark叢集上。
對於Jupyter沒有現成的版本管理控制和專案管理, 我們結合git來解決。
另外為了提高建模人員在Jupyter上的效率,我們引入了比較多的外掛,例如:把一些典型挖掘pipeline做成Jupyter模板,這樣需要再做一個類似業務的時候只需要基於模板再擴充套件開發,比較好地解決了不規範的問題,避免了很多重複程式碼,也為實驗程式碼轉化為生產程式碼做好了基礎。
第二點,說下工具函式:
我們內部提供了主要機器學習相關的函式庫和工具:
1)標準化的ID Mapping服務API。
2)建立資料抽取的API,無論是哪種儲存,分析人員只要統一調這個API就可。3)視覺化做了標準化的函式庫和工具類。
4)Jupyter2AzkabanFlow: 可以把原本在Jupyter上寫好的程式碼或者指令碼自動轉化成AzkabanFlow,解決了特徵工程階段的程式碼複用問題。
第三點,關於使用Tensorflow:
使用Tensorflow時,我們的選型是TensorflowOnSpark,原生的Tensorflow的分散式支援不夠好,需要去指定一些節點資訊,使用難度較大。
TensorflowOnSpark能夠解決原生Tensorflow Cluster分散式問題,程式碼也很容易遷移到TensorflowOnSpark上,基本不用改。
同時利用yarn可以支援GPU和CPU混部叢集,資源易複用。
第四點,關於模型交付應用:
在模型交付的問題上,我們把整個預測程式碼框架化了,提供了多種標準的框架供分析人員直接選用。對輸出的模型檔案有格式進行要求,例如:只能選擇 pmml格式或者tensorflow pb格式。標準化之後,只要使用標準的預測函式庫,就可以把建模人員的工作和系統開發人員的工作解藕出來。
最後分享下我們的一些經驗:
第一,TensorflowOnSpark上的PS數量有限制,而且Worker和PS節點資源分配不是很靈活,都是等大。
第二,Jupyter在使用的時候,需要自己做一些改造,一些開源庫版本相容性有問題。
第三,使用PMML有效能瓶頸,一些是java物件反覆重建,還有一些是格式轉化損耗,具體大家可以抓取下jvm資訊分析優化。
第四,在落地過程使用Spark、Hive的問題上,需要提供易於使用的診斷工具,建模人員並不是Spark、Hive的專家,不一定熟悉如何診斷優化。
第五,要把模型和特徵庫當成一個資產來看待,對它的價值定期做評估,要管理好它的生命週期。
第六,一些更偏底層的問題,比如: 硬體的選型可能要注意頻寬、記憶體、GPU平衡。
最後,需要平衡技術棧增加和維護代價,避免引入太多新工具新技術,導致運維困難。
以上就是我在機器學習方面的一些心得經驗,希望對你有幫助。也歡迎在留言區針對相關的問題與我交流!