
MySQL鎖與事務的隔離級別
1. 概述
在資料庫中,除了傳統的計算資源(如CPU、RAM、I/O等)的爭用以外,資料也是一種供需要使用者共享的資源。如何保證資料併發訪問的一致性、有效性是所有資料庫必須解決的一個問題,鎖衝突也是影響資料庫併發訪問效能的一個重要因素。從這個角度來說,鎖對資料庫而言顯得尤其重要,也更加複雜。
(1)樂觀鎖:樂觀鎖,大多是基於資料版本( Version )記錄機制實現。
(2)悲觀鎖:是一種併發控制的方法。它可以阻止一個事務以影響其他使用者的方式來修改資料。如果一個事務執行的操作 給某行資料應用了鎖,那只有當這個事務把鎖釋放,其他事務才能夠執行與該鎖衝突的操作。
讀鎖(共享鎖):針對同一份資料,多個讀操作可以同時進行而不會互相影響
寫鎖(排它鎖):當前寫操作沒有完成前,它會阻斷其他寫鎖和讀鎖
2. 三鎖
表鎖偏向MyISAM儲存引擎,開銷小,加鎖快,無思索,鎖定粒度大,發生鎖衝突的概率最高,併發度最低。
建立測試表:
CREATE TABLE `mylock` (
`id` INT (11) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR (20) DEFAULT NULL,
) ENGINE = MyISAM DEFAULT CHARSET = utf8;
插入資料
INSERT INTO `mylock` (`id`, `NAME`
) VALUES ('1', 'a');INSERT INTO `mylock` (`id`, `NAME`) VALUES ('2', 'b');
手動增加表鎖
lock table 表名稱 read(write),表名稱2 read(write);
查看錶上加過的鎖
刪除表鎖
2.1.2 案例分析(加讀鎖)

當前session和其他session都可以讀該表

當前session中插入或者更新鎖定的表都會報錯,其他session插入或更新則會等待


2.1.3 案例分析(加寫鎖)

當前session對該表的增刪改查都沒有問題,其他session對該表的所有操作被阻塞

2.1.4 案例結論
MyISAM在執行查詢語句(SELECT)前,會自動給涉及的所有表加讀鎖,在執行增刪改操作前,會自動給涉及的表加寫鎖。
1、對MyISAM表的讀操作(加讀鎖) ,不會阻寒其他程序對同一表的讀請求,但會阻賽對同一表的寫請求。只有當讀鎖釋放後,才會執行其它程序的寫操作。
2、對MylSAM表的寫操作(加寫鎖) ,會阻塞其他程序對同一表的讀和寫操作,只有當寫鎖釋放後,才會執行其它程序的讀寫操作
簡而言之,就是讀鎖會阻塞寫,但是不會阻塞讀。而寫鎖則會把讀和寫都阻塞。
2.2 行鎖(偏寫)
行鎖偏向InnoDB儲存引擎,開銷大,加鎖慢,會出現死鎖,鎖定粒度最小,發生鎖衝突的概率最低,併發度也最高。InnoDB與MYISAM的最大不同有兩點:一是支援事務(TRANSACTION);二是採用了行級鎖。
事務是由一組SQL語句組成的邏輯處理單元,事務具有以下4個屬性,通常簡稱為事務的ACID屬性。
原子性(Atomicity) :事務是一個原子操作單元,其對資料的修改,要麼全都執行,要麼全都不執行。
一致性(Consistent) :在事務開始和完成時,資料都必須保持一致狀態。這意味著所有相關的資料規則都必須應用於事務的修改,以保持資料的完整性;事務結束時,所有的內部資料結構(如B樹索引或雙向連結串列)也都必須是正確的。
隔離性(Isolation) :資料庫系統提供一定的隔離機制,保證事務在不受外部併發操作影響的“獨立”環境執行。這意味著事務處理過程中的中間狀態對外部是不可見的,反之亦然。
永續性(Durable) :事務完成之後,它對於資料的修改是永久性的,即使出現系統故障也能夠保持。
當兩個或多個事務選擇同一行,然後基於最初選定的值更新該行時,由於每個事務都不知道其他事務的存在,就會發生丟失更新問題–最後的更新覆蓋了由其他事務所做的更新。
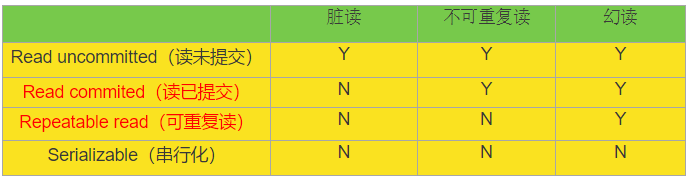
一個事務正在對一條記錄做修改,在這個事務完成並提交前,這條記錄的資料就處於不一致的狀態;這時,另一個事務也來讀取同一條記錄,如果不加控制,第二個事務讀取了這些“髒”資料,並據此作進一步的處理,就會產生未提交的資料依賴關係。這種現象被形象的叫做“髒讀”。
一句話:事務A讀取到了事務B已經修改但尚未提交的資料,還在這個資料基礎上做了操作。此時,如果B事務回滾,A讀取的資料無效,不符合一致性要求。
一個事務在讀取某些資料後的某個時間,再次讀取以前讀過的資料,卻發現其讀出的資料已經發生了改變、或某些記錄已經被刪除了!這種現象就叫做“不可重複讀”。
一句話:事務A讀取到了事務B已經提交的修改資料,不符合隔離性
一個事務按相同的查詢條件重新讀取以前檢索過的資料,卻發現其他事務插入了滿足其查詢條件的新資料,這種現象就稱為“幻讀”。
在MySQL資料庫中,支援上面四種隔離級別,預設的為Repeatable read (可重複讀);而在Oracle資料庫中,只支援Serializable (序列化)級別和Read committed (讀已提交)這兩種級別,其中預設的為Read committed級別。
髒讀”、“不可重複讀”和“幻讀”,其實都是資料庫讀一致性問題,必須由資料庫提供一定的事務隔離機制來解決。
資料庫的事務隔離越嚴格,併發副作用越小,但付出的代價也就越大,因為事務隔離實質上就是使事務在一定程度上“序列化”進行,這顯然與“併發”是矛盾的。
同時,不同的應用對讀一致性和事務隔離程度的要求也是不同的,比如許多應用對“不可重複讀"和“幻讀”並不敏感,可能更關心資料併發訪問的能力。
常看當前資料庫的事務隔離級別: show variables like 'tx_isolation';
設定事務隔離級別:set tx_isolation='REPEATABLE-READ';
建立InnoDB型別的測試表測試行鎖和資料據的隔離級別
CREATE TABLE `account` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`balance` int(11) DEFAULT NULL,
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `account` (`name`, `balance`) VALUES ('ls', '1000');
INSERT INTO `account` (`name`, `balance`) VALUES ('zs', '10000');
INSERT INTO `account` (`name`, `balance`) VALUES ('ww', '1000');
2.2.2 行鎖案例分析

2.2.3 隔離級別案例分析
1、讀未提交:
(1)開啟一個客戶端A,並設定當前事務模式為read uncommitted(未提交讀),查詢表account的初始值:
set tx_isolation='read-uncommitted';

髒讀:sesion1中讀到了session2中還沒有提交的資料

分析:
一旦session2的事務因為某種原因回滾,所有的操作都將會被撤銷,那session1查詢到的資料其實就是髒資料.
在session1執行更新語句update account set balance = balance - 100 where id =1,ls的balance沒有變成800,居然是900,是不是很奇怪,資料不一致啊,如果你這麼想就太天真 了,在應用程式中,我們會用400-50=350,並不知道其他會話回滾了,要想解決這個問題可以採用讀已提交的隔離級別

2、讀已提交(在客戶端A讀到客戶端B提交的資料)
(1)開啟一個客戶端A,並設定當前事務模式為read committed(未提交讀),
set tx_isolation='read-committed';

查詢表account的所有記錄

(2)在客戶端A的事務提交之前,開啟另一個客戶端B,更新表account:

(3)這時,客戶端B的事務還沒提交,客戶端A不能查詢到B已經更新的資料,解決了髒讀問題:

(4)客戶端B的事務提交,客戶端A執行與上一步相同的查詢,結果 與上一步不一致,即產生了不可重複讀的問題。

3、可重複讀
(1)開啟一個客戶端A,並設定當前事務模式為repeatable read,查詢表account的所有記錄
set tx_isolation='repeatable-read';

(2)在客戶端A的事務提交之前,開啟另一個客戶端B,更新表account並提交

(3)在客戶端A查詢表account的所有記錄,與步驟(1)查詢結果一致,沒有出現不可重複讀的問題

(4)在客戶端A,接著執行update balance = balance - 100 where id = 1,balance沒有變成900-100=800,ls的balance值用的是步驟(2)中的800來算的,所以是700,資料的一致性倒是沒有被破壞。
可重複讀的隔離級別下使用了MVCC(Multi-Version Concurrency Control 多版本併發)機制,select操作不會更新版本號,是快照讀(歷史版本);insert、update和delete會更新版本號,是當前讀(當前版本)。mysql的innodb採用的是行鎖,而且採用了多版本併發控制來提高讀操作的效能。

(5)重新開啟客戶端B,插入一條新資料後提交(幻讀的驗證)

(6)在客戶端A查詢表account的所有記錄,沒有 查出 新增資料,但出現幻讀

分析:資料庫的隔離級別可提交讀,會產生幻讀,那為什麼我們在客服端查詢不到客戶端B新增並且cimmit的新紀錄呢,其實前面我們已經說過了,MySQL的InnoDB採用mvcc(多版本控制)機制的,我們讀取的都時快照版本(歷史版本),只有insert,update,delete才會使用當前版本的。
(7)驗證幻讀
在客戶端A執行update account set balance=888 where id = 4;能更新成功,再次查詢能查到客戶端B新增的資料

4.序列化
(1)開啟一個客戶端A,並設定當前事務模式為serializable,查詢表account的初始值:
set tx_isolation='serializable';

(2)開啟一個客戶端B,並設定當前事務模式為serializable,插入一條記錄報錯,表被鎖了插入失敗,mysql中事務隔離級別為serializable時會鎖表,因此不會出現幻讀的情況,這種隔離級別併發性極低,開發中很少會用到。

- Mysql預設級別是repeatable-read,有辦法解決幻讀問題嗎?
要避免幻讀可以用間隙鎖在客戶端A下面執行update account set name = 'cym' where id > 10 and id <=20;,則其他客戶端沒法插入這個範圍內的資料

2.2.4 案例結論
Innodb儲存引擎由於實現了行級鎖定,雖然在鎖定機制的實現方面所帶來的效能損耗可能比表級鎖定會要更高一下,但是在整體併發處理能力方面要遠遠優於MYISAM的表級鎖定的。當系統併發量高的時候,Innodb的整體效能和MYISAM相比就會有比較明顯的優勢了。
但是,Innodb的行級鎖定同樣也有其脆弱的一面,當我們使用不當的時候,可能會讓Innodb的整體效能表現不僅不能比MYISAM高,甚至可能會更差。
通過檢查InnoDB_row_lock狀態變數來分析系統上的行鎖的爭奪情況
show status like'innodb_row_lock%';
Innodb_row_lock_current_waits: 當前正在等待鎖定的數量
Innodb_row_lock_time: 從系統啟動到現在鎖定總時間長度
Innodb_row_lock_time_avg: 每次等待所花平均時間
Innodb_row_lock_time_max:從系統啟動到現在等待最長的一次所花時間
Innodb_row_lock_waits:系統啟動後到現在總共等待的次數
Innodb_row_lock_time_avg (等待平均時長)
尤其是當等待次數很高,而且每次等待時長也不小的時候,我們就需要分析系統中為什麼會有如此多的等待,然後根據分析結果著手製定優化計劃。
set tx_isolation='repeatable-read';
Session_1執行:select * from account where id=1 for update;
Session_2執行:select * from account where id=2 for update;
Session_1執行:select * from account where id=2 for update;
Session_2執行:select * from account where id=1 for update;
檢視近期死鎖日誌資訊:show engine innodb status\G;
大多數情況mysql可以自動檢測死鎖並回滾產生死鎖的那個事務,但是有些情況mysql沒法自動檢測死鎖