
HDFS(一)—— 使用 HDFS 的 WebConsole
當執行 啟動 HDFS 的時候,可以通過 WebConsole(網頁管理介面)來檢視 HDFS 的狀態,執行一些操作。
一些常用的 WebConsole 埠:
- 8088:Yarn
- 50070:NameNode
- 50090:SecondaryNameNode
以 50070 為例,簡單的瞭解一下頁面上的一些資訊:
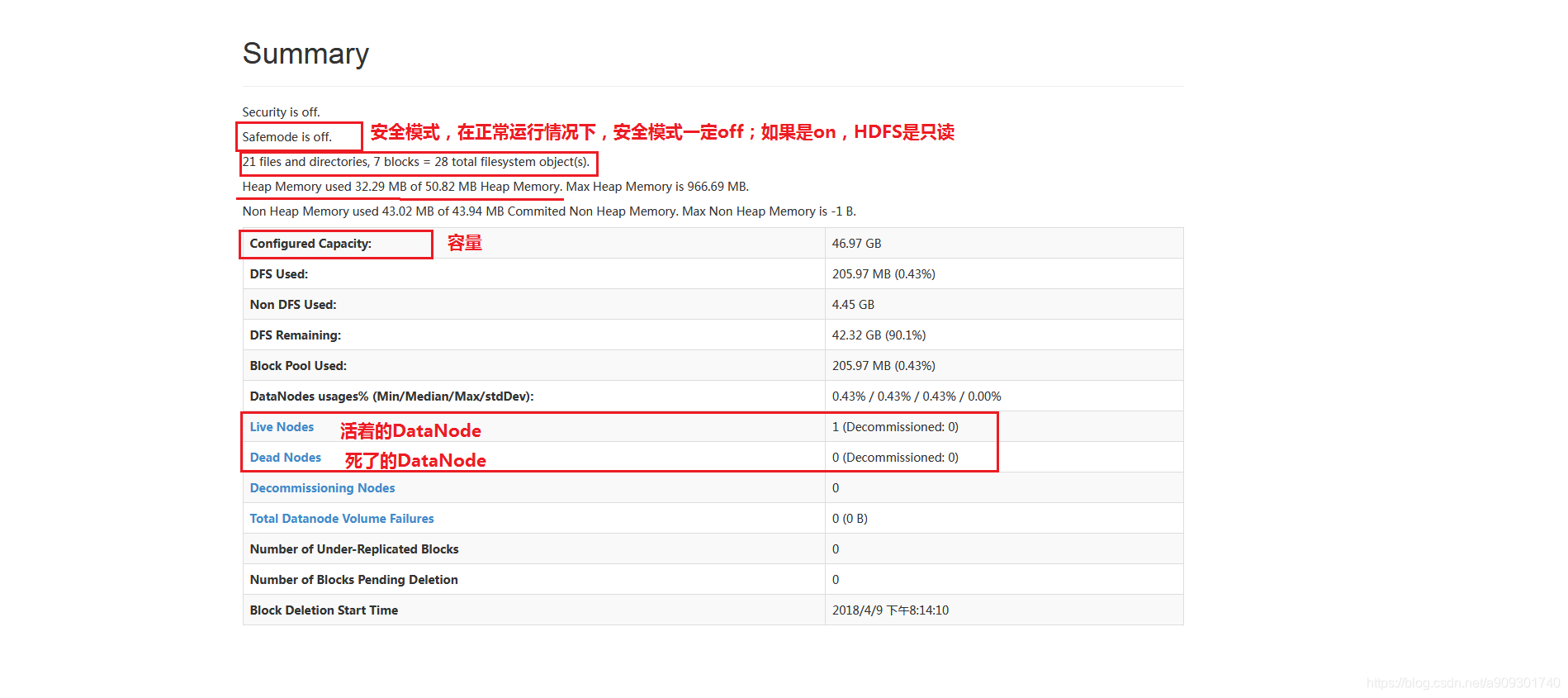
- Overview 選項卡下的截圖:
Startup Progress 選項卡上的一些資訊:
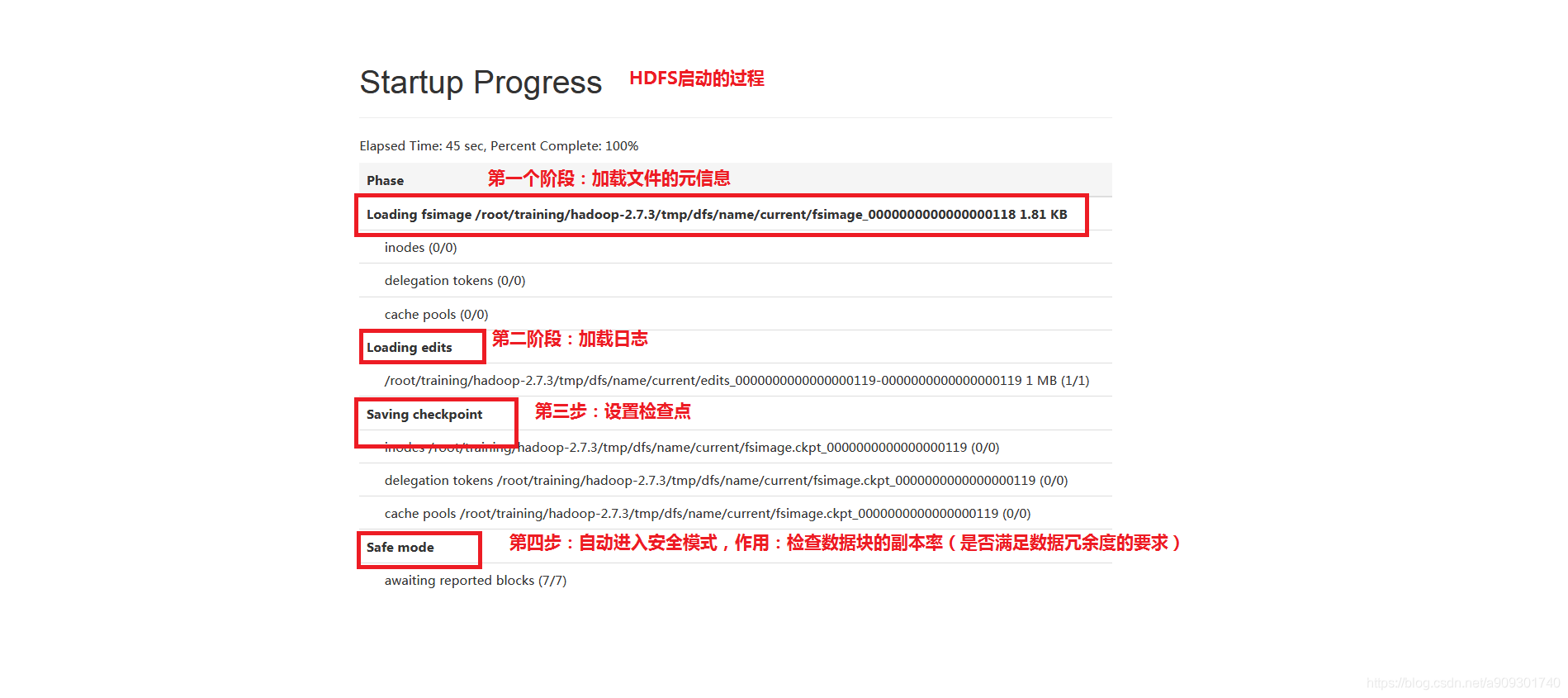
HDFS 的啟動過程:
-
載入 fsimage 檔案(HDFS 的元資訊)。
-
載入 edits 檔案(操作日誌)。
-
儲存檢查點(以後每次到了檢查點 SecondaryNameNode 就會將 edits 檔案合併到 fsimage 上)。
-
自動進入安全模式,作用:檢查資料塊的副本率(是否滿足資料冗餘度的要求)。
-
啟動完成後,會退出安全模式。
相關推薦
HDFS(一)—— 使用 HDFS 的 WebConsole
當執行 啟動 HDFS 的時候,可以通過 WebConsole(網頁管理介面)來檢視 HDFS 的狀態,執行一些操作。 一些常用的 WebConsole 埠: 8088:Yarn 50070:NameNode 50090:SecondaryNameNode
Hadoop源碼學習之HDFS(一)
-a node bsp ima 數據 layout 版本號 name 技術 Hadoop的HDFS可以分為NameNode與DataNode,NameNode存儲所有DataNode中數據的元數據信息。而DataNode負責存儲真正的數據(數據塊)信息以及數據塊的ID。
Mysql 流增量寫入 Hdfs(一) --從 mysql 到 kafka
一. 概述 在大資料的靜態資料處理中,目前普遍採用的是用 Spark + Hdfs (Hive / Hbase) 的技術架構來對資料進行處理。 但有時候有其他的需求,需要從其他不同資料來源不間斷得采集資料,然後儲存到 Hdfs 中進行處理。而追加(append)這種操作在 Hdfs 裡面明顯是比較麻煩的一件事
(一)HDFS總體架構
1、背景 海量的非結構化資料,幾乎沒法梳理成一個個的欄位,來儲存在關係型資料庫中。所以實際應用中,對於這類資料需要考慮資料如何儲存。資料如何計算的問題。 2、hadoop兩個核心 HDFS(以分散式方式來儲存海量資料) MapReduce(以HDFS上的資料為基礎進行計算
從零開始學Hadoop----淺析HDFS(一)
之前,我們簡單介紹了一下Hadoop,知道他是一個處理大資料的框架。今天我們來看看Hadoop的核心構成之一—-HDFS. 一、基礎概念 1、是什麼
《Hadoop》"呶呶不休"(一)HDFS概述
一、HDFS簡介 1、簡單介紹 HDFS(Hadoop Distributed FileSystem),是Hadoop專案的兩大核心之一,源自於Google於2003年10月發表的GFS論文,是對GFS的開源實現。HDFS在最開始是作為Apache Nutch搜尋引擎
HDFS(一) 高級特性
分鐘 創建 ace tor tsp 設定 -a 災難恢復 interval 三個高級特性——快照、配額、回收站 一、快照(snapshot):是一種備份,默認關閉 1、應用場景: 防止用戶錯誤操作 備份 試驗/測試 災難恢復 2
淺談HDFS(一)
產生背景及定義 HDFS:分散式檔案系統,用於儲存檔案,主要特點在於其分散式,即有很多伺服器聯合起來實現其功能,叢集中的伺服器各有各的角色 隨著資料量越來越大,一個作業系統存不下所有的資料,那麼就分配到更多的作業系統管理的磁碟中,但是管理和維護極不方便,於是迫切需要一種系統來管理多臺機器上的檔案,這就是
HDFS(七)—— HDFS 的高階功能
HDFS 的高階功能主要包括: 回收站:便於找到誤刪的資料。 快照:對資料的備份。 配額:限制目錄中檔案的數量和大小。 一、回收站(trash) 預設回收站是關閉的,可以通過在 core-site.xml 中新增 fs.trash.inte
HDFS(六)—— HDFS 檔案下載的過程
一、客戶端發出下載檔案的請求 客戶端執行hdfs dfs -get /movie/a.avi命令請求 HDFS 下載檔案到本地。 二、DFSClient 接收請求,建立 DistributedFileSystem 物件 DFSClient 接收下載檔案的請求,並且建立
HDFS(五)—— HDFS 檔案上傳的過程
一、客戶端傳送請求 客戶端執行上傳檔案的命令:hdfs dfs -put a.avi /movie。 二、DFSClient.java 建立 DistributedFileSystem 請求首先被 DFSClient.java 這個類獲取到,由該類建立 Distribu
HDFS(二)——HDFS 常用命令
操作 HDFS 的命令主要分兩種:操作命令,管理命令。 一、操作命令 操作命令以 hdfs dfs ****開頭。 -mkdir:建立目錄。 例 1:hdfs dfs -mkdir /aaa—> 在 HDFS 的根目錄下建立一個目錄aaa。 例 2:hdfs
centos7下Hadoop2.8.4全分佈搭建之HDFS叢集搭建(一)
1)搭建前的準備 注意:(以下操作可以先配置一臺,然後通過scp命令傳送到其他兩臺虛擬機器上 傳送到其他機器 scp -r 主機名: 注意:載入環境變數 source /etc/profile
HDFS基本原理與工作機制(一)——初識HDFS
HDFS簡介 HDFS 源於 Google 在2003年10月份發表的GFS(Google File System) 論文。 是 GFS 的一個克隆版本 HDFS(Hadoop Distributed File System)是Hadoop專案的核心子專案,是分散式計算中資料
【spark】儲存資料到hdfs,自動判斷合理分塊數量(repartition和coalesce)(一)
本人菜鳥一隻,也處於學習階段,如果有什麼說錯的地方還請大家批評指出! 首先我想說明下該文章是幹嘛的,該文章粗略介紹了hdfs儲存資料檔案塊策略和spark的repartition、coalesce兩個運算元的區別,是為了下一篇文章的自動判斷合理分塊數做知識的鋪墊,如果對於這部分知識已經瞭解,甚至
雲端計算(十一)- HDFS快照(HDFS Snapshots)
HDFS快照是一個只讀的基於時間點檔案系統拷貝。快照可以是整個檔案系統的也可以是一部分。常用來作為資料備份,防止使用者錯誤和容災。 HDFS實現了: Snapshot 建立的時間 複雜度為O(1),但是不包括INode 的尋找時間只有當修改SnapShot時,才會有額外的記憶體佔用,記憶體使用量為O(M)
[hadoop]HDFS(Hadoop分散式檔案系統)(一)
Hadoop的起源: Hadoop是Google的集群系統的開源實現 Google集群系統:GFS(Google File System)、 MapReduce、BigTableHadoop主要由HDFS(Hadoop Distributed File System Ha
HA-高可用的HDFS搭建(hdfs+zookeeper)(一)
早期的Hadoop1.x版本,NN是HDFS叢集的單點故障點,每一個叢集只有一個NN,如果這個機器或程序不可用,整個叢集就無法使用。為了解決這個問題在Hadoop2.x中藉助於中間特定的中間渠道解決單點故障點問題,官方文件中提供兩種解決方法: NFS和QJMNFS:採用的是網
HDFS問題集(一),使用命令報錯:com.google.protobuf.ServiceException:java.lang.OutOfMemoryError:java heap space
正常 腳本 spa 執行 xmx error exception 內存 解決方案 僅個人實踐所得,若有不正確的地方,歡迎交流! 一、起因 執行以下兩條基本的HDFS命令時報錯 1 hdfs dfs -get /home/mr/data/* ./ 2 hdfs dfs
Hadoop入門系列(一)Window環境下搭建hadoop和hdfs的基本操作
1.去官網下載hadoop。1>選擇映象網站,選清華的映象的網站。2>找個自己喜歡版本的hadoop,下載好將壓縮包解壓。 2.找對應版本的winutil。因為hadoop主要基於linux編寫,這個winutil.exe主要用於模擬linux下的目錄環境。因此h