
[轉]TensorFlow如何進行時序預測
TensorFlow 是一個採用資料流圖(data flow graphs),用於數值計算的開源軟體庫。節點(Nodes)在圖中表示數學操作,圖中的線(edges)則表示在節點間相互聯絡的多維資料陣列,即張量(tensor)。它靈活的架構讓你可以在多種平臺上展開計算,例如臺式計算機中的一個或多個CPU(或GPU),伺服器,移動裝置等等。TensorFlow 最初由Google大腦小組(隸屬於Google機器智慧研究機構)的研究員和工程師們開發出來,用於機器學習和深度神經網路方面的研究,但這個系統的通用性使其也可廣泛用於其他計算領域。
時間序列分析在計量經濟學和財務分析中具有重要意義,但也可以應用於瞭解趨勢做決策和對行為模式的變化做出反應的領域。其中例如,作為主要石油和天然氣供應商的MapR融合資料平臺客戶將感測器放在井上,將資料傳送到MapR Streams,然後將其用於趨勢監測井的狀況,如體積和溫度。在金融方面,時間序列分析用於股票價格,資產和商品的價格的預測。計量經濟學家長期利用“差分自迴歸移動平均模型”(ARIMA)模型進行單變數預測。
ARIMA模型已經使用了幾十年,並且很好理解。然而,隨著機器學習的興起,以及最近的深度學習,其他模式正在被探索和利用。
深度學習(DL)是基於一組演算法的機器學習的分支,它通過使用由多個非線性變換組成的人造神經網路(ANN)架構來嘗試對資料進行高階抽象然後建模。更為流行的DL神經網路之一是迴圈神經網路(RNN)。RNN是依賴於其輸入的順序性質的一類神經網路。這樣的輸入可以是文字,語音,時間序列,以及序列中的元素的出現取決於在它之前出現的元素。例如,一句話中的下一個字,如果有人寫“雜貨”最有可能是“商店”而不是“學校”。在這種情況下,給定這個序列,RNN可能預測是商店而不是學校。
人工神經網路
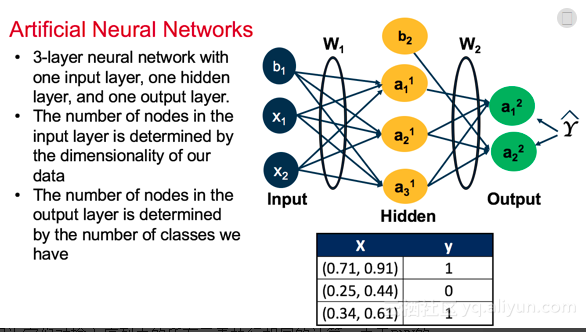
實際上,事實證明,雖然神經網路有時是令人畏懼的結構,但使它們工作的機制出奇地簡單:隨機梯度下降。對於我們網路中的每個引數(如權重或偏差),我們所要做的就是計算相對於損耗的引數的導數,並在相反方向微調一點。
ANNs使用稱為反向傳播(有想了解BP演算法的可以參考BP演算法雙向傳,鏈式求導最纏綿)的方法來調整和優化結果。反向傳播是一個兩步過程,其中輸入通過正向傳播饋送到神經網路中,並且在通過啟用函式變換之前與(最初隨機的)權重和偏差相乘。你的神經網路的深度將取決於你的輸入應該經過多少變換。一旦正向傳播完成,反向傳播步驟通過計算產生誤差的權重的偏導數來調整誤差。一旦調整權重,模型將重複正向和反向傳播步驟的過程,以最小化誤差率直到收斂。下圖中你看到這是一個只有一個隱藏層的ANN,所以反向傳播不需要執行多個梯度下降計算。
迴圈神經網路
迴圈神經網路(RNN)被稱為迴圈是因為它們對輸入序列中的所有元素執行相同的計算。由於RNN的廣泛應用,RNN正在變得非常受歡迎。它們可以分析時間序列資料,如股票價格,並提供預測。在自動駕駛系統中,他們可以預測汽車軌跡並幫助避免事故。他們可以將句子,文件或音訊樣本作為輸入,它們也可以應用於自然語言處理(NLP)系統,如自動翻譯,語音對文字或情感分析。
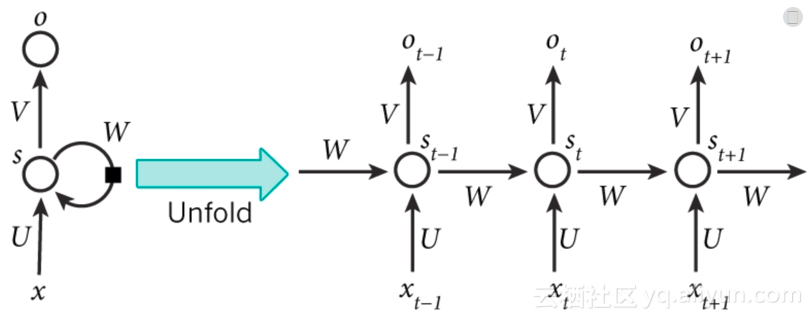
上圖是RNN架構的示例,並且我們看到xt是時間步長t的輸入。例如,x1可能是時間段1中的股票的第一個價格。st是在時間步長tn處的隱藏狀態,並且使用啟用函式基於先前的隱藏狀態和當前步驟的輸入來計算。St-1通常被初始化為零。ot是步驟t的輸出。例如,如果我們想預測序列中的下一個值,那麼它將是我們時間序列中概率的向量。
RNN隱藏層的成長是依賴於先前輸入的隱藏狀態或記憶,捕獲到目前為止所看到的內容。任何時間點的隱藏狀態的值都是前一時間步驟中的隱藏狀態值和當前時間的輸入值進行函式計算的結果。RNN具有與ANN不同的結構,並且通過時間(BPTT)使用反向傳播來計算每次迭代之後的梯度下降。
一個小例子:
此示例使用3個節點的小型MapR群集完成。此示例將使用以下內容:
- Python 3.5
- TensorFlow 1.0.1
- Red Hat 6.9
如果你使用Anaconda,你需要保證你能夠安裝TensorFlow 1.0.1版本在你本地的機器上。此程式碼將不能在TensorFlow <1.0版本上使用。如果TensorFlow版本相同,則可以在本地機器上執行並傳輸到叢集。其他需要考慮的深度學習庫是MXNet,Caffe2,Torch和Theano。Keras是另一個為TensorFlow或Theano提供python包的深度學習庫。
MapR提供了使用者喜好的整合Jupyter Notebook(或Zeppelin)的功能。我們將在這裡顯示的是資料管道的尾端。在分散式環境中執行RNN時間序列模型的真正價值是你可以構建的資料流水線,將聚合的系列資料推送到可以饋送到TensorFlow計算圖中的格式。
如果我正在聚合來自多個裝置(IDS,syslogs等)的網路流,並且我想預測未來的網路流量模式行為,我可以使用MapR Streams建立一個實時資料管道,將這些資料聚合成一個佇列,進入我的TensorFlow模型。對於這個例子,我在叢集上只使用一個節點,但是我可以在其他兩個節點上安裝TensorFlow,並且可以有三個TF模型執行不同的超引數。
對於這個例子,我生成了一些虛擬資料。

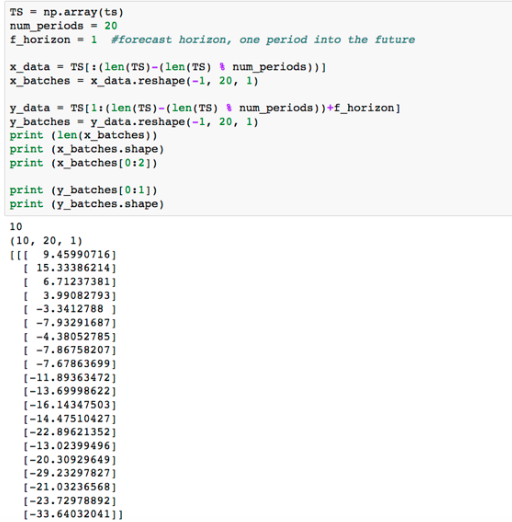
我們在我們的資料中有209個觀察結果。我want確保我對每個批次輸入都有相同的觀察次數。
我們看到的是我們的訓練資料集由10個批次組成,包含20個觀測值。每個觀察值是單個值的序列。
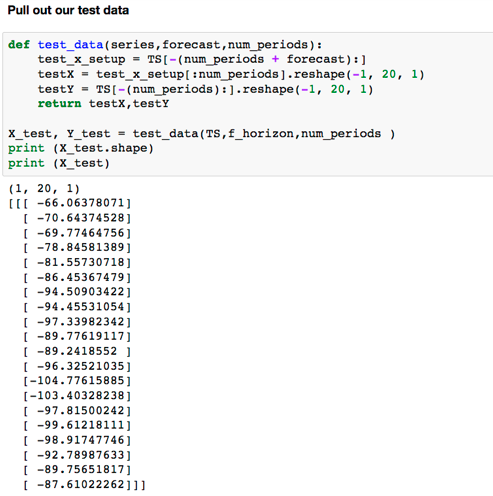
現在我們有了我們的資料,我們來建立一個將執行計算的TensorFlow圖。
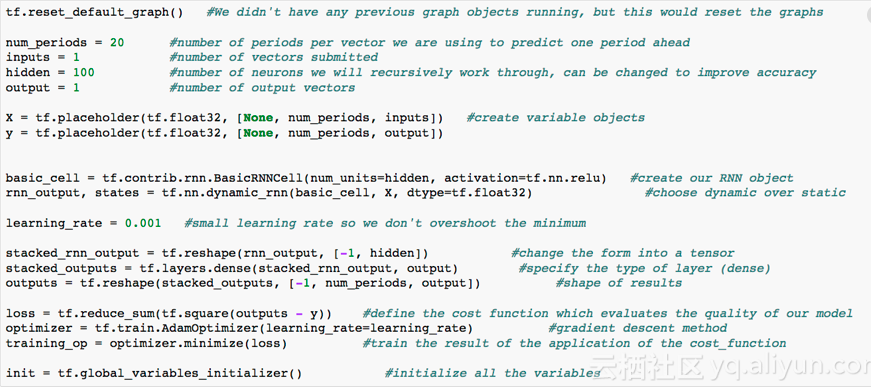
這裡有很多事情需要處理。例如我們正在指定我們用來預測的週期數。我們指定我們的變數佔位符。我們初始化一種使用的RNN單元格(大小100)和我們想要的啟用函式的型別。ReLU代表“整流線性單元”,是預設的啟用功能,但如果需要,可以更改為Sigmoid,Hyberbolic Tangent(Tanh)等。
我們希望我們的輸出與我們的輸入格式相同,我們可以使用損失函式來比較我們的結果。在這種情況下,我們使用均方誤差(MSE),因為這是一個迴歸問題,我們的目標是最小化實際和預測之間的差異。如果我們處理分類結果,我們可能會使用交叉熵。現在我們定義了這個損失函式,可以定義TensorFlow中的訓練操作,這將優化我們的輸入和輸出網路。要執行優化,我們將使用Adam優化器。Adam優化器是一個很好的通用優化器,可以通過反向傳播實現漸變下降。
現在是時候在我們的訓練資料上實施這個模型了。

我們將指定我們的批次訓練序列迴圈的迭代/紀元的數量。接著,我們建立我們的圖形物件(tf.Session()),並初始化我們的資料,以便在我們遍歷曆元時被饋送到模型中。縮寫輸出顯示每100個紀元後的MSE。隨著我們的模型提供資料向前和反向傳播執行,它調整應用於輸入的權重並執行另一個訓練時期,我們的MSE得到了持續改善(減少)。最後,一旦模型完成,它將接受引數並將其應用於測試資料中,以Y的預測輸出。
我們來看看我們的預測跟實際相差多少。對於我們的測試資料,我們集中在整個209個週期的最後20個時期。
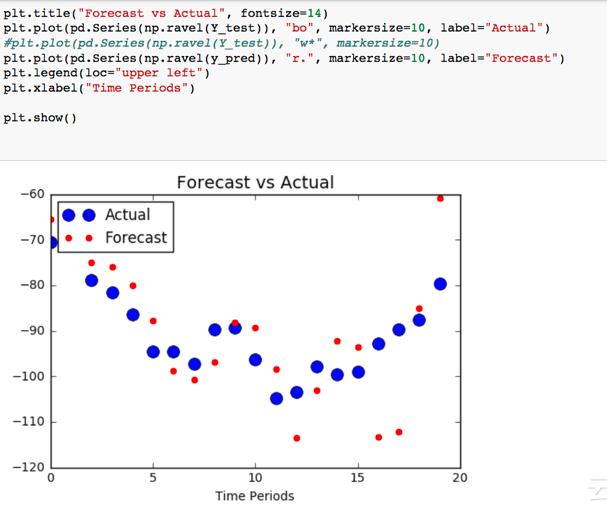
看來這還有一些改進的空間。這可以通過改變隱藏的神經元的數量或增加迭代的數量來完成。優化我們的模式是一個試錯的過程,但我們有一個好的開始。這是隨機資料,所以我們期待著很好的結果,但是也許將這個模型應用到實時系列中會給ARIMA模型帶來一些競爭壓力。
資料科學家因為RNN(和深度學習)的出現,有了更多可用的選項以此來解決更多有趣的問題。許多資料科學家面臨的一個問題是,一旦我們進行了優化,我們如何自動化我們的分析執行?擁有像MapR這樣的平臺允許這種能力,因為你可以在大型資料環境中構建,訓練,測試和優化你的模型。在這個例子中,我們只使用了10個訓練批次。如果我的資料允許我利用數百批次,而不僅僅是20個時期,我想我一定能改進這種模式。一旦我做到了,我可以把它打包成一個自動化指令碼,在一個單獨的節點,一個GPU節點,一個Docker容器中執行。這就是在融合資料平臺上進行資料科學和深度學習的力量。
希望上述的文章能夠幫到你理解TensorFlow。
原文連結地址:https://yq.aliyun.com/articles/118726
相關連結:https://blog.csdn.net/Gavin__Zhou/article/details/78659430?utm_source=blogxgwz9
相關連結:https://mp.weixin.qq.com/s?__biz=MzI0ODcxODk5OA==&mid=2247489403&idx=1&sn=9f004963889104fd83307e48e9ec8709