
Python網路爬蟲之製作股票資料定向爬蟲 以及爬取的優化 可以顯示進度條!
阿新 • • 發佈:2018-11-25
候選網站:
新浪股票:http://finance.sina.com.cn/stock/
百度股票:https://gupiao.baidu.com/stock/
選取原則:
- 無robots協議
- 非js網頁
- 資料在HTMLK頁面中的
F12,檢視原始碼,即可檢視。
新浪股票,使用JS製作。指令碼生成的資料。
百度股票可以在HTML中查詢到!
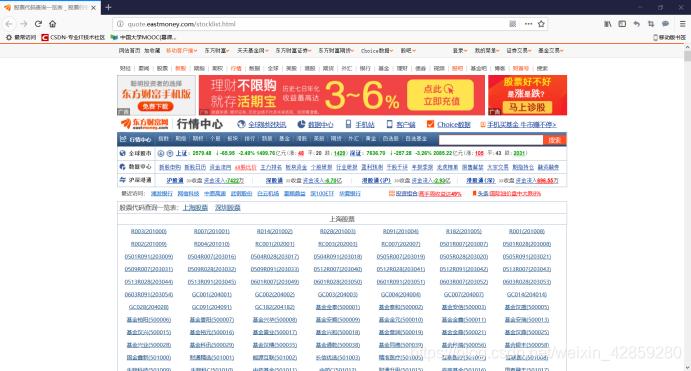
http://quote.eastmoney.com/stocklist.html
這個地址可以查詢股票詳細列表!
程式思路:
1. 獲取股票列表
2. 根據列表資訊到百度獲取個股資訊2,根據列表資訊到百度獲取個股資訊
3. 將結果儲存
考慮用字典作為資料容器進行儲存!
火狐瀏覽器可以檢視原始碼,藍色的IE瀏覽器就會出現亂碼:
火狐的:

因為a標籤,太多所以正則表示式匹配比較困難。
可用try except來解決!
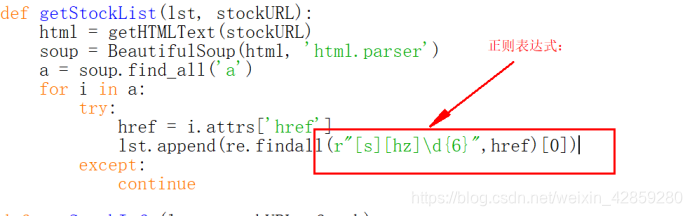
[s]:表示s。[hz]:表示h z。後面是隨意6個數。
SH:
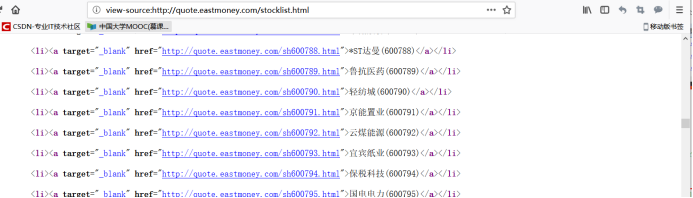
SZ:

優化:

- r.encoding:僅從頭部獲得
- r.apparent_encoding:是從全文獲得的。r.apparent_encoding:是從全文獲得的。
優化就是將編碼直接給程式碼,另外一個就是顯示進度。
下面就是程式碼部分啦:
最初的程式碼:(真長)
import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url): try: r = requests.get(url, timeout = 30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL) soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}",href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html == "": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div', attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'股票名稱':name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valurList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write(str(infoDict) + '\n') except: traceback.print_exc() continue def main(): stock_list_url = 'https://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D:\234.txt' slist = [] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
程式碼執行結果;

優化後的程式碼:
import requests from bs4 import BeautifulSoup import traceback import re def getHTMLText(url,code='utf-8'):#預設的是utf-8 try: r = requests.get(url, timeout = 30) r.raise_for_status() r.encoding = code#直接賦值 return r.text except: return "" def getStockList(lst, stockURL): html = getHTMLText(stockURL,'GB2312')#已經查詢過啦! soup = BeautifulSoup(html, 'html.parser') a = soup.find_all('a') for i in a: try: href = i.attrs['href'] lst.append(re.findall(r"[s][hz]\d{6}",href)[0]) except: continue def getStockInfo(lst, stockURL, fpath): count = 0 for stock in lst: url = stockURL + stock + ".html" html = getHTMLText(url) try: if html == "": continue infoDict = {} soup = BeautifulSoup(html, 'html.parser') stockInfo = soup.find('div', attrs={'class':'stock-bets'}) name = stockInfo.find_all(attrs={'class':'bets-name'})[0] infoDict.update({'股票名稱':name.text.split()[0]}) keyList = stockInfo.find_all('dt') valueList = stockInfo.find_all('dd') for i in range(len(keyList)): key = keyList[i].text val = valurList[i].text infoDict[key] = val with open(fpath, 'a', encoding='utf-8') as f: f.write(str(infoDict) + '\n') count = count +1 print('\r當前速度:{:.2f}%'.format(count*100/len(lst)),end=' ') except: count = count +1 print('\r當前速度:{:.2f}%'.format(count*100/len(lst)),end=' ') traceback.print_exc() continue def main(): stock_list_url = 'https://quote.eastmoney.com/stocklist.html' stock_info_url = 'https://gupiao.baidu.com/stock/' output_file = 'D:\234.txt' slist = [] getStockList(slist, stock_list_url) getStockInfo(slist, stock_info_url, output_file) main()
提前給出了編碼方式以及可以顯示進度條的程式碼
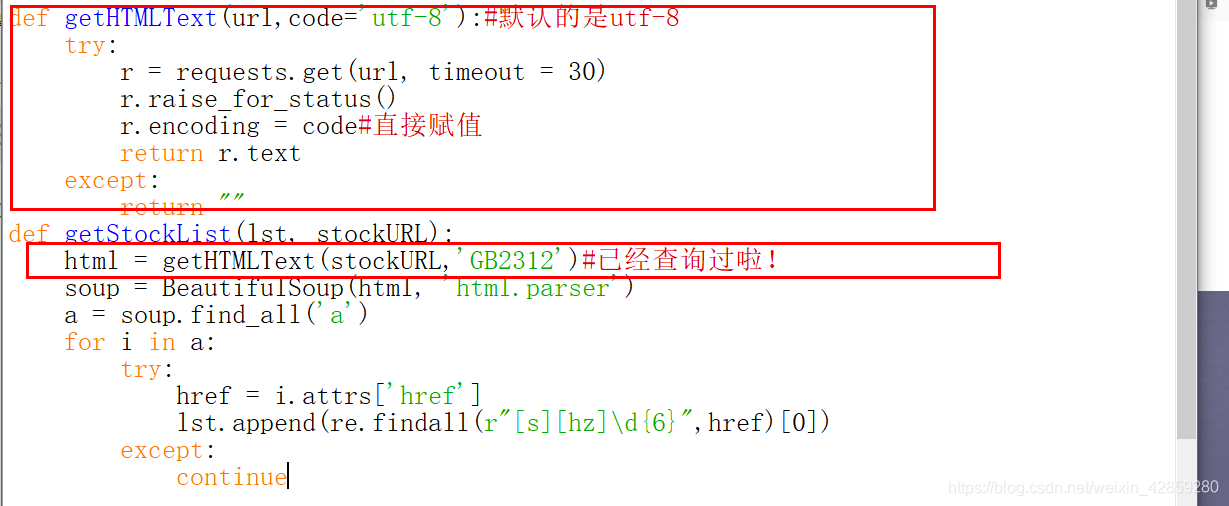
給出編碼方式的程式碼:
def getHTMLText(url,code='utf-8'):#預設的是utf-8
try:
r = requests.get(url, timeout = 30)
r.raise_for_status()
r.encoding = code#直接賦值
return r.text
except:
return ""
def getStockList(lst, stockURL):
html = getHTMLText(stockURL,'GB2312')#已經查詢過啦!
soup = BeautifulSoup(html, 'html.parser')
a = soup.find_all('a')
for i in a:
try:
href = i.attrs['href']
lst.append(re.findall(r"[s][hz]\d{6}",href)[0])
except:
continue
照片:
(如果不是utf-8,就要提前給替換掉!)
可以顯示進度條的程式碼
def getStockInfo(lst, stockURL, fpath):
count = 0
for stock in lst:
url = stockURL + stock + ".html"
html = getHTMLText(url)
try:
if html == "":
continue
infoDict = {}
soup = BeautifulSoup(html, 'html.parser')
stockInfo = soup.find('div', attrs={'class':'stock-bets'})
name = stockInfo.find_all(attrs={'class':'bets-name'})[0]
infoDict.update({'股票名稱':name.text.split()[0]})
keyList = stockInfo.find_all('dt')
valueList = stockInfo.find_all('dd')
for i in range(len(keyList)):
key = keyList[i].text
val = valurList[i].text
infoDict[key] = val
with open(fpath, 'a', encoding='utf-8') as f:
f.write(str(infoDict) + '\n')
count = count +1
print('\r當前速度:{:.2f}%'.format(count*100/len(lst)),end=' ')
except:
count = count +1
print('\r當前速度:{:.2f}%'.format(count*100/len(lst)),end=' ')
traceback.print_exc()
continue
照片:
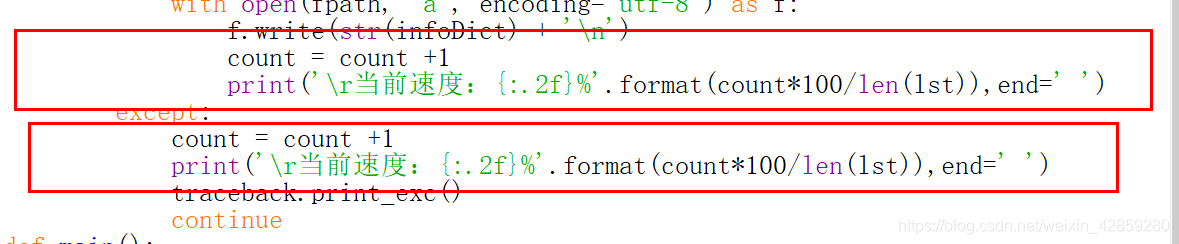 不過,顯示進度在IDLE那裡不可以顯示。
不過,顯示進度在IDLE那裡不可以顯示。
但是最後我也沒成功有檔案生成以及顯示進度條,算啦。先去吃飯啦~