
python第九周學習內容
1.paramiko模組
用處:連線遠端伺服器並執行相關操作
使用方法:
SSHClient:連線遠端伺服器並執行基本命令
import paramiko #建立SSH物件 ssh = paramiko.SSHClient() #允許連線不在know_hosts檔案中的主機 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #連線伺服器 ssh.connect(hostname="cl.salt.com",port=22,username="Mr Wu",password=123456) #執行命令 stdin,stdout,stderr = ssh.exec_command("df") #標準輸入、標準輸出、標準錯誤 #獲取命令結果 res,err = stdout.read(),stderr.read() result = res if res else err print(result) #關閉連線 ssh.close()
SSHFtp:連線遠端伺服器並執行上傳下載功能
import paramiko #建立連線 transport = paramiko.Transport(("hostname",22)) transport.connect(username="Mr Wu",password="123") #TCP/IP等協議實在SFTPClient中定義的sftp = paramiko.SFTPClient.from_transport(transport) #將本地檔案location.py上傳至伺服器 /tmp/test.py sftp.put("/tmp/location.py","/tmp/test.py") #將遠端檔案remove_path 下載到本地 local_path sftp.get("remove_path","local_path") transport.close()
SSH_RSA:基於公鑰金鑰進行連線
RSA:非對稱金鑰驗證
公鑰:儲存在要連線的伺服器
私鑰:儲存在本地機器
import paramiko private_key= paramiko.RSAKey.from_private_key_file('/home/auto/.ssh/id_rsa') #建立SSH物件 ssh = paramiko.SSHClient() #允許連線不在know_hosts檔案中的主機 ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy()) #連線伺服器 ssh.connect(hostname="cl.salt.com",port=22,username="Mr Wu",key_filename=private_key) #執行命令 stdin,stdout,stderr = ssh.exec_command("df") #獲取命令結果 res,err = stdout.read(),stderr.read() result = res if res else err print(result.decode())
2.程序:
什麼是程序:程式的執行例項稱為程序。
每個程序都提供執行程式所需的資源。 程序具有虛擬地址空間,可執行程式碼,系統物件的開啟控制代碼,安全上下文,唯一程序識別符號,環境變數,優先順序類,最小和最大工作集大小以及至少一個執行執行緒。 每個程序都使用單個執行緒啟動,通常稱為主執行緒,但可以從其任何執行緒建立其他執行緒。
程序的特點:程序之間的記憶體是相互獨立的
要操作CPU,必須通過執行緒
程序之間不能直接通訊,必須通過中間代理
建立子程序就是對父程序進行一次克隆
程序只能操作它的子程序,不能操作它的父程序
對父程序的修改不會對子程序產生影響
3.執行緒:
什麼是執行緒:作業系統能夠進行運算排程的最小單位,它被包含在程序之中,是程序的實際運作單位,一條執行緒指的是程序中的一個單一順序的控制流,一個程序可以併發多個執行緒,每個執行緒可以執行不同的任務。
執行緒就是一段可執行的上下文,CPU執行時就不斷切換上下文來執行不同的執行緒,當一個執行緒沒有執行完畢時,暫存器會儲存可執行的上下文的中斷的位置,當CPU又切換到這段上下文時,就從中斷位置繼續執行
執行緒的特點:是作業系統的最小的排程單位,是一串指令的集合
所有在同一程序裡的執行緒共享同一塊記憶體空間
一個執行緒可以控制和操作同一程序裡的其他執行緒
對主執行緒的修改可能會影響其他的執行緒
4.python GIL(Global Interpreter Lock)
全域性直譯器鎖:在python中,全域性直譯器鎖是一個互斥鎖,它可以防止多個本機執行緒同時執行python位元組碼,這種鎖是必要的,因為python執行緒呼叫的是作業系統的原生系統,cpython的記憶體管理不是執行緒安全的。
全域性直譯器鎖是歷史遺留問題:
這是python的記憶體python直譯器裡有一個獨立的執行緒,每過一段時間它起wake up做一次全域性輪詢看看哪些記憶體資料是可以被清空的,此時你自己的程式 裡的執行緒和 py直譯器自己的執行緒是併發執行的,假設你的執行緒刪除了一個變數,py直譯器的垃圾回收執行緒在清空這個變數的過程中的clearing時刻,可能一個其它執行緒正好又重新給這個還沒來及得清空的記憶體空間賦值了,結果就有可能新賦值的資料被刪除了,為了解決類似的問題,python直譯器簡單粗暴的加了鎖。
所以由於GIL的存在,python並不能利用cpu多核的特性,在微觀層面上,python並不是真正的多執行緒,在同一時刻只能有一個執行緒在執行。
python threading模組:
執行緒的兩種呼叫方式:
直接呼叫:
例項化一個執行緒:t = threading.Thread()
import threading,time #迴圈啟動50個執行緒 def run(n): time.sleep(2) print("task:",n,threading.current_thread()) for i in range(50): t = threading.Thread(target=run,args=("t%s"%i,)) t.start()
繼承式呼叫:
import threading class MyThread(threading.Thread): def __init__(self,n): super(MyThread,self).__init__() self.n = n def run(self): print("running task",self.n) t1 = MyThread("t1") t2 = MyThread("t2") t1.start() t2.start()
t.Join()
阻塞:主執行緒必須等待執行緒t執行完畢後才能繼續執行
import threading,time def run(n): time.sleep(2) print("task:",n,threading.current_thread()) start_time = time.time() t_list = [] #存放執行緒例項 for i in range(10): t = threading.Thread(target=run,args=("t%s"%i,)) t.start() t_list.append(t) #為了不阻塞後面執行緒的啟動,不在這裡join,先放到一個列表裡 for t in t_list: t.join() end_time = time.time() print("=========all threads has finished....") print("cost:",end_time - start_time,threading.current_thread()) #整個程式是一個主執行緒,for迴圈內是子執行緒,主執行緒與子執行緒併發執行 #output: ''' task: t0 <Thread(Thread-1, started 6448)> task: t1 <Thread(Thread-2, started 10080)> task: t2 <Thread(Thread-3, started 2736)> task: t3 <Thread(Thread-4, started 7072)> task: t4 <Thread(Thread-5, started 7704)> task: t6 <Thread(Thread-7, started 1280)> task: t5 <Thread(Thread-6, started 1520)> task: t8 <Thread(Thread-9, started 3764)> task: t7 <Thread(Thread-8, started 4136)> task: t9 <Thread(Thread-10, started 2444)> =========all threads has finished.... cost: 2.0088112354278564 <_MainThread(MainThread, started 6208)> '''
t.setBaemon(True)
將執行緒t設定為守護執行緒,整個程式在非守護執行緒執行結束時就結束,不會等待守護程序
注:由守護程序建立的其他程序,在非守護程序結束時也會結束,不管其是否完成任務
import threading,time def run(n): time.sleep(2) print("task:",n,threading.current_thread()) start_time = time.time() for i in range(50): t = threading.Thread(target=run,args=("t%s"%i,)) t.setDaemon(True) t.start() end_time = time.time() print("=========all threads has finished....") print("cost:",end_time - start_time,threading.current_thread()) #整個程式是一個主執行緒,for迴圈內是子執行緒,主執行緒與子執行緒併發執行 #整個程式在非守護執行緒執行結束時就結束,不會等待守護程序
注:由守護程序建立的其他程序,在非守護程序結束時也會結束,不管其是否完成任務
#output: ''' =========all threads has finished.... cost: 0.03975486755371094 <_MainThread(MainThread, started 10208)> '''
執行緒鎖:
設count = 0,當我們啟用50個執行緒去執行count += 1時。按理來說,由於GIL的存在,這些執行緒其實是序列的,計算出的最終count的值應該等於50,但是在實際程式執行時,count的值常常會小於50。這與python GIL的執行原理有關,當CPU大概執行一百多條命令時python直譯器就會釋放全域性直譯器鎖,這樣就可能導致某兩個執行緒返回的是同一個值(其中一個執行緒還沒有執行完畢時,python直譯器釋放了全域性直譯器鎖,導致另一個執行緒拿到的值是資料池裡面沒有改變的值)
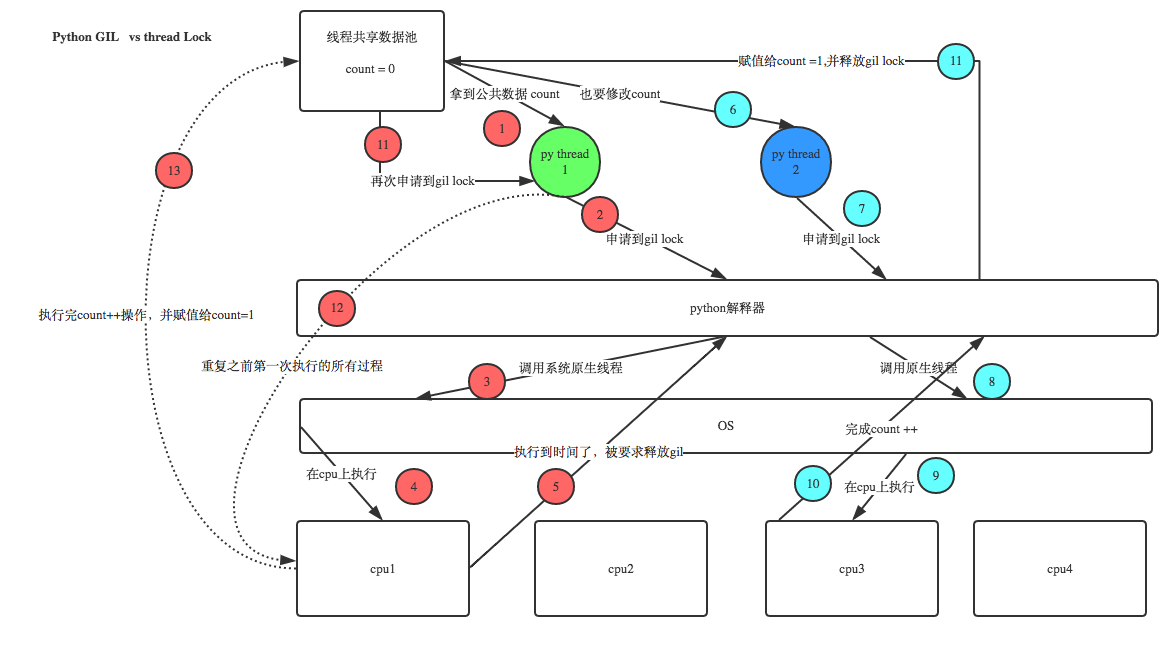
這個時候我們可以自己設定執行緒鎖,即在一個執行緒執行完任務count += 1後,才會釋放執行緒鎖,其他執行緒才能申請全域性直譯器鎖。
import threading,time #例項化一個執行緒鎖 lock = threading.Lock() num = 0 #當資料量不是特別大時可使用執行緒鎖 def run(n): lock.acquire() #加鎖 global num num += 1 lock.release() #釋放鎖 for t in range(50): t = threading.Thread(target=run,args=(num,)) t.start() print("num:",num) #output: num: 50
遞迴鎖(Rlock)
import threading,time num,num2 = 0,0 lock = threading.RLock() #遞迴鎖 def run1(): print("grab the first part data") lock.acquire() global num num += 1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print("-----between run1 and run2------") res2 = run2() lock.release() print(res,res2) for i in range(2): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: pass else: print("=======all threads done======") print(num,num2) #output: ''' grab the first part data -----between run1 and run2------ grab the second part data 1 1 grab the first part data -----between run1 and run2------ grab the second part data 2 2 =======all threads done====== 2 2 '''
訊號量(semaphore)
執行緒鎖同時允許一個執行緒更改資料,而訊號量是同時允許一定數量的執行緒更改資料。
注:在設定的訊號量執行緒裡,只要有一個執行緒完成,就會讓新的執行緒進來,直到所有執行緒執行結束
semaphore = threading.BoundedSemaphore(5) #設定訊號量,最大隻能設定為5
semaphore.acquire() #申請執行緒鎖
semaphore.release() #釋放執行緒鎖
#在設定的訊號量執行緒裡,只要有一個執行緒完成,就會讓新的執行緒進來,保持設定的執行緒數直到所有執行緒執行結束 import threading,time def run(n): semaphore.acquire() print("run the thread: %s\n"%n) global num num += 1 time.sleep(1) semaphore.release() if __name__ == '__main__': num = 0 semaphore = threading.BoundedSemaphore()#最多允許5個執行緒同時執行 for i in range(20): t = threading.Thread(target=run,args=(i,)) t.start() while threading.active_count() != 1: pass else: print("-----all threads done-----") print(num)
計時器(Timer)
此類表示僅在經過一定時間後才應執行的操作。
與執行緒一樣,通過呼叫start()方法啟動計時器。 通過呼叫thecancel()方法可以停止計時器(在其動作開始之前)。 計時器在執行其操作之前將等待的時間間隔可能與使用者指定的時間間隔不完全相同。
import threading def run(): print("My Name Is Mr Wu!") t = threading.Timer(10,run) t.start() #在10秒後輸出 My Name Is Mr Wu!
事件(event)
事件是一個簡單的同步物件;
事件代表一個內部標誌和執行緒。
事件可以等待設定標誌,或者自己設定或清除標誌。
簡單點來說,事件就是通過設定、清除標誌位來實現兩個執行緒之間的互動。
event = threading.Event() #生成一個事件例項
event.clear() #清空標誌位
event.set() #設定標誌位
event.wait() #等待標誌位被設定
程式示例:紅燈停、綠燈行。紅燈、綠燈的持續時間都是5,當汽車看到紅燈的時候停止行駛,當看到綠燈的時候行駛。
import time,threading event = threading.Event()#生成一個事件例項 def lighter(): count = 0 while True: if count > 5 and count <= 10:#改成紅燈 event.clear()#清空標誌位 print("\033[41;1m紅燈停\033[0m") elif count > 10: #改成綠燈 #event.set() count = 0 else: event.set() print("\033[42;1m綠燈行\033[0m") time.sleep(1) count += 1 def car(name): while True: if event.is_set(): #綠燈行 print("[%s] running...."%name) time.sleep(1) else: print("[%s] sees red light , waiting..."%name) event.wait() print("[%s] sees green light , start going..."%name) car1 = threading.Thread(target=car,args=("Tesla",)) light = threading.Thread(target=lighter) light.start() car1.start()
佇列(Queue)
當必須在多個執行緒之間安全地交換資訊時,佇列線上程程式設計中特別有用。
簡單點說,佇列就是一個存放資料的容器,執行緒既可以把資料放進去也可以把資料取出來,以此達到執行緒互動的目的。
class queue.Queue(maxsize = 0) #先進先出
class queue.LifoQueue(maxsize = 0) #後進先出
class queue.PriorityQueue(maxsize = 0) #儲存資料時可設定優先順序
優先順序佇列的建構函式。 maxsize是一個整數,用於設定可以放入佇列的專案數的上限。 達到此大小後,插入將阻止,直到消耗佇列項。 如果maxsize小於或等於零,則佇列大小為無限大。
exception queue.Bmpty
在對空的Queue物件呼叫非阻塞get()(或get_nowait())時引發異常。
exception queue.Full
在已滿的Queue物件上呼叫非阻塞put()(或put_nowait())時引發異常。
Queue.qsize() #返回佇列的長度
Queue.empty() #return True if enmpty
Queue.full() #return True if full
Queue.put(item,block = True,timeout = None) #取出佇列裡的資料
當把將資料放入佇列中時。 如果block=True且timeout=None(預設值),則在佇列為滿的時候阻塞,直到佇列有空閒區域的時候才能繼續放入資料。 如果timeout是一個正數,則佇列阻塞最多timeout秒,如果在該時間內佇列為滿,則會引發Full異常。如果block=False,當佇列有空閒區域時,則將資料放在佇列中,否則引發Full異常(在這種情況下忽略超時)。
Queue.put_nowait(item)
Equivalent to put(item,False).
Queue.get(block = True,timeout = None)
當從佇列中取出資料時。 如果block=true且timeout=None(預設值),則在佇列為空的時候阻塞,直到佇列中有資料時才能繼續取出資料。 如果timeout是一個正數,則佇列阻塞最多timeout秒,如果在該時間內佇列為空,則會引發Empty異常。當block=False,當佇列不為空時,則可取出資料,否則引發Empty異常(在這種情況下忽略超時)、
Queue.get_nowait(time)
Equivalent to get(item,False).
生產者消費者模型
為什麼要使用生產者消費者模式?
線上程世界裡,生產者就是生產資料的執行緒,消費者就是消費資料的執行緒。在多執行緒開發當中,如果生產者處理速度很快,而消費者處理速度很慢,那麼生產者就必須等待消費者處理完,才能繼續生產資料。同樣的道理,如果消費者的處理能力大於生產者,那麼消費者就必須等待生產者。為了解決這個問題於是引入了生產者和消費者模式。
什麼是生產這消費者模式?
生產者消費者模式是通過一個容器來解決生產者和消費者的強耦合問題。生產者和消費者彼此之間不直接通訊,而通過阻塞佇列來進行通訊,所以生產者生產完資料之後不用等待消費者處理,直接扔給阻塞佇列,消費者不找生產者要資料,而是直接從阻塞佇列裡取,阻塞佇列就相當於一個緩衝區,平衡了生產者和消費者的處理能力。
程式示例:
import threading,queue,time q = queue.Queue(maxsize=10) def producer(name): count = 1 while True: q.put("骨頭%s"%count) print("生產了骨頭",count) count += 1 time.sleep(2) def consumer(name): #while q.qsize() > 0: while True: print("[%s] 取到[%s],並且吃了它...."%(name,q.get())) time.sleep(1) p = threading.Thread(target=producer,args=("Alex",)) c = threading.Thread(target=consumer,args=("ChengRongHua",)) c1 = threading.Thread(target=consumer,args=("王森",)) p.start() c.start() c1.start()