
(一)理解word2vec:原理篇
為什麼想起來學習word2vec呢?其實之前自己根本沒有接觸過NLP的知識和任務,只是最近嘗試使用了embedding的方法去處理類別特徵和用embedding去做推薦,發現有不錯的效果。同時,自己也感觸到了所掌握知識的匱乏,因此,決定好好學習一下word2vec。
最近幾天自己研讀了網上一些介紹word2vec原理的部落格,寫得非常得清晰和易懂。因此,自己也想做一個總結,關於word2vec的原理和實踐的一個總結。供自己和讀者們隨時可以參看。
好了,廢話不多說了。本篇部落格主要記錄word2vec的原理。關於實踐word2vec的部落格請參看這篇。
宣告:本篇部落格主要借鑑了劉建平老師在部落格園的
文章目錄
- 一、引言
- 二、詞向量基礎
- 三、 基於Hierarchical Softmax的模型
- 3.1 基於Hierarchical Softmax的模型概述
- 3.2 基於Hierarchical Softmax的模型梯度計算
- 3.3 基於Hierarchical Softmax的CBOW模型
- 3.4 基於Hierarchical Softmax的Skip-Gram模型
- 四、基於Negative Sampling的模型
- 4.1 Hierarchical Softmax的缺點與改進
- 4.2 基於Negative Sampling的模型概述
- 4.3 基於Negative Sampling的模型梯度計算
- 4.4 Negative Sampling負取樣方法
- 4.5 基於Negative Sampling的CBOW模型
- 4.6 基於Negative Sampling的Skip-Gram模型
- 五、Hierarchical Softmax和Negative Sampling的一些細節
- 參考文獻
一、引言
1.1 什麼是word2vec
word2vec是google在2013年推出的一個NLP工具,它的特點是將所有的詞向量化,這樣詞與詞之間就可以定量的去度量他們之間的關係,挖掘詞之間的聯絡。原始論文《Exploiting Similarities among Languages for Machine Translation》。根據上面簡單的介紹,我們一句話來說明word2vec是什麼:word2vec就是把單詞轉換成向量。
我們知道one-hot編碼也可以將單詞轉換為向量,one-hot representation用來表示詞向量非常簡單,但是卻有很多問題。最大的問題是我們的詞彙表一般都非常大,比如達到百萬級別,這樣每個詞都用百萬維的向量來表示簡直是記憶體的災難。這樣的向量其實除了一個位置是1,其餘的位置全部都是0,表達的效率不高,能不能把詞向量的維度變小呢?
word2vec轉換的向量相比於one-hot編碼是低維稠密的。我們稱其為Dristributed representation,這可以解決one-hot representation的問題,它的思路是通過訓練,將每個詞都對映到一個較短的詞向量上來。所有的這些詞向量就構成了向量空間,進而可以用普通的統計學的方法來研究詞與詞之間的關係。這個較短的詞向量維度是多大呢?這個一般需要我們在訓練時自己來指定。
有了用Dristributed representation表示的較短的詞向量,我們就可以較容易的分析詞之間的關係了,比如我們將詞的維度降維到2維,有一個有趣的研究表明,用下圖的詞向量表示我們的詞時,我們可以發現:
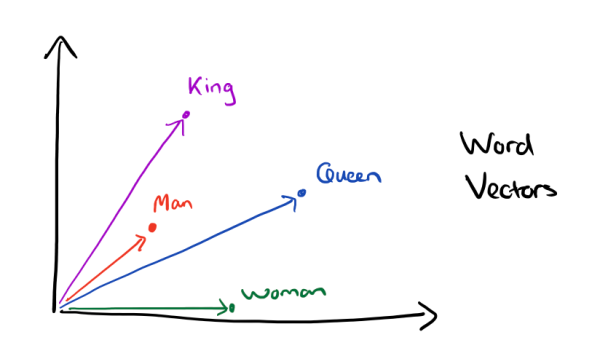
還比如,在一些介紹手機的語料庫中,我們可以找相關詞,注意是相關詞而不是同義詞。例如你輸入”雷軍”,計算出來的相關詞就會有:手機,小米,喬布斯等等。
那麼,word2vec是怎麼樣學會相關詞了呢?我這裡先給一個小小的例子,具體的細節後面會講。
word2vec的原理就是 一個詞預測 前後詞 或者 前後詞 預測 當前詞,使得概率最大化。
這會導致2個結果:
-
相似的句子,相同部位的詞會相關。
比如 句子1 w1 w2 w3 w4 X w5 w6 w7.
句子2 w1 w2 w3 w5 Y w5 w6 w7.
因為 X 的向量 受 w1 w2 w3 w4 w5 w6 w7 向量影響決定, Y也是受這幾個詞影響決定。
所以 X Y 是相關的。
-
挨著近的詞,也是相關的。
比如 句子 w1 w2 w3 w4 X Y w5 w6 w7. 這樣 X Y 都是受到 來自 w1 w2 w3 w4 w5 w6 w7
向量影響決定。所以X Y是相關的。
1.2 word2vec在工業界有什麼應用
那麼,word2vec在工業中有什麼應用呢?我在這裡先介紹一些具體的應用,讓大家感受以下word2vec的強大作用。隨後,我再介紹它的原理。
1.2.1 在社交網路中的推薦
通過類似nearest neighbor原理,找意思相關的詞彙,段落或者文章匹配,推薦排序。比如有一個個性化推薦的場景,給當前使用者推薦他可能關注的『大V』。對一個新使用者,此題基本無解。但如果在已知使用者關注了幾個『大V』之後,相當於知道了當前使用者的一些關注偏好,根據此偏好給他推薦和他關注過大V相似的大V,就是一個很不錯的推薦策略。所以,如果可以求出來任何兩個V使用者的相似度,上面問題就可以基本得到解決。
我們知道word2vec中兩個詞的相似度可以直接通過餘弦來衡量,接下來就是如何將每個V使用者變為一個詞向量的問題了。巧妙的地方就是如何定義doc和word,針對上面問題,可以將doc和word定義為:
1.word -> 每一個大V就是一個詞
2.doc -> 根據每一個使用者關注大V的順序,生成一篇文章
由於使用者量很大(大約4億),可以將關注word個數少的doc刪掉,因為本身大V的種類是十萬級別(如果我沒記錯的話), 選擇可以覆蓋絕大多數大V的文章數量就足夠了。
1.2.2 計算商品的相似度
在商品推薦的場景中,競品推薦和搭配推薦的時候都有可能需要計算任何兩個商品的相似度,根據瀏覽/收藏/下單/App下載等行為,可以將商品看做詞,將每一個使用者的一類行為序看做一個文件,通過word2vec將其訓練為一個向量。
同樣的,在計算廣告中,根據使用者的點選廣告的點選序列,將每一個廣告變為一個向量。變為向量後,用此向量可以生成特徵融入到rank模型中。
1.2.3 作為另一個模型的輸入
把word2vec生成的向量直接作為深度神經網路的輸入。
二、詞向量基礎
那麼我們應該怎麼訓練得到合適的詞向量呢?一個很常見的方法是使用神經網路語言模型。
2.1 CBOW與Skip-Gram用於神經網路語言模型
在word2vec出現之前,已經有用神經網路DNN來用訓練詞向量進而處理詞與詞之間的關係了。採用的方法一般是一個三層的神經網路結構(當然也可以多層),分為輸入層,隱藏層和輸出層(softmax層)。
這個模型是如何定義資料的輸入和輸出呢?一般分為CBOW(Continuous Bag-of-Words)與Skip-Gram(Continuous Bag-of-Words)兩種模型。
CBOW模型的訓練輸入是某一個特徵詞的上下文相關的詞對應的詞向量,而輸出就是這特定的一個詞的詞向量。比如下面這段話,我們的上下文大小取值為4,特定的這個詞是"Learning",也就是我們需要的輸出詞向量,上下文對應的詞有8個,前後各4個,這8個詞是我們模型的輸入。由於CBOW使用的是詞袋模型,因此這8個詞都是平等的,也就是不考慮他們和我們關注的詞之間的距離大小,只要在我們上下文之內即可。
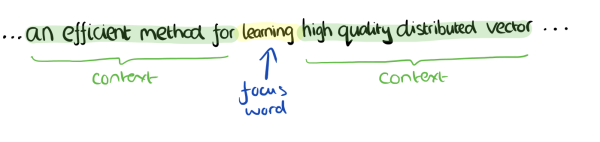
在我們這個CBOW的例子裡,我們的輸入是8個詞向量,輸出是所有詞的softmax概率(訓練的目標是期望訓練樣本特定詞對應的softmax概率最大),對應的CBOW神經網路模型輸入層有8個神經元,輸出層有詞彙表大小個神經元。隱藏層的神經元個數我們可以自己指定。通過DNN的反向傳播演算法,我們可以求出DNN模型的引數,同時得到所有的詞對應的詞向量。這樣當我們有新的需求,要求出某8個詞對應的最可能的輸出中心詞時,我們可以通過一次DNN前向傳播演算法並通過softmax啟用函式找到概率最大的詞對應的神經元即可。
Skip-Gram模型和CBOW的思路是反著來的,即輸入是特定的一個詞的詞向量,而輸出是特定詞對應的上下文詞向量。還是上面的例子,我們的上下文大小取值為4, 特定的這個詞"Learning"是我們的輸入,而這8個上下文詞是我們的輸出。
在我們這個Skip-Gram的例子裡,我們的輸入是特定詞, 輸出是softmax概率排前8的8個詞,對應的Skip-Gram神經網路模型輸入層有1個神經元,輸出層有詞彙表大小個神經元。隱藏層的神經元個數我們可以自己指定。通過DNN的反向傳播演算法,我們可以求出DNN模型的引數,同時得到所有的詞對應的詞向量。這樣當我們有新的需求,要求出某1個詞對應的最可能的8個上下文詞時,我們可以通過一次DNN前向傳播演算法得到概率大小排前8的softmax概率對應的神經元所對應的詞即可。
以上就是神經網路語言模型中如何用CBOW與Skip-Gram來訓練模型與得到詞向量的大概過程。但是這和word2vec中用CBOW與Skip-Gram來訓練模型與得到詞向量的過程有很多的不同。
word2vec為什麼 不用現成的DNN模型,要繼續優化出新方法呢?最主要的問題是DNN模型的這個處理過程非常耗時。我們的詞彙表一般在百萬級別以上,這意味著我們DNN的輸出層需要進行softmax計算各個詞的輸出概率的的計算量很大。有沒有簡化一點點的方法呢?
2.2 Hierarchical Softmax模型和Negative Sampling模型
為了加速訓練過程,Google論文裡真實實現的word2vec對模型提出了兩種改進思路,即Hierarchical Softmax模型和Negative Sampling模型。
Hierarchical Softmax是用輸出值的霍夫曼編碼代替原本的one-hot向量,用霍夫曼樹替代Softmax的計算過程。
Negative Sampling(簡稱NEG)使用隨機採用替代Softmax計算概率,它是另一種更嚴謹的抽樣模型NCE的簡化版本。
關於Hierarchical Softmax和Negative Sampling的原理細節我將在第三章和第四章進行詳細地闡述。
將這兩種演算法與前面的兩個模型組合,在Google的論文裡一共包含了4種Word2Vec的實現。
- Hierarchical Softmax CBOW 模型
- Hierarchical Softmax Skip-Gram 模型
- Negative Sampling CBOW 模型
- Negative Sampling Skip-Gram 模型
2.3 word2vec基礎之霍夫曼樹
我們已經知道word2vec也使用了CBOW與Skip-Gram來訓練模型與得到詞向量,但是並沒有使用傳統的DNN模型。在Hierarchical Softmax中,使用的資料結構是用霍夫曼樹來代替隱藏層和輸出層的神經元,霍夫曼樹的葉子節點起到輸出層神經元的作用,葉子節點的個數即為詞彙表的小大。 而內部節點則起到隱藏層神經元的作用。
具體如何用霍夫曼樹來進行CBOW和Skip-Gram的訓練我們在第三章裡講,這裡我們先複習下霍夫曼樹。
霍夫曼樹大家都很熟悉,建立其實並不難,過程如下:
-
輸入:權值為 的 個節點
-
輸出:對應的霍夫曼樹
1)將 看做是有 棵樹的森林,每個樹僅有一個節點。
2)在森林中選擇根節點權值最小的兩棵樹進行合併,得到一個新的樹,這兩顆樹分佈作為新樹的左右子樹。新樹的根節點權重為左右子樹的根節點權重之和。
3) 將之前的根節點權值最小的兩棵樹從森林刪除,並把新樹加入森林。
4)重複步驟2)和3)直到森林裡只有一棵樹為止。
下面我們用一個具體的例子來說明霍夫曼樹建立的過程,我們有(a,b,c,d,e,f)共6個節點,節點的權值分佈是(16,4,8,6,20,3)。
首先是最小的b和f合併,得到的新樹根節點權重是7.此時森林裡5棵樹,根節點權重分別是16,8,6,20,7。此時根節點權重最小的6,7合併,得到新子樹,依次類推,最終得到下面的霍夫曼樹。
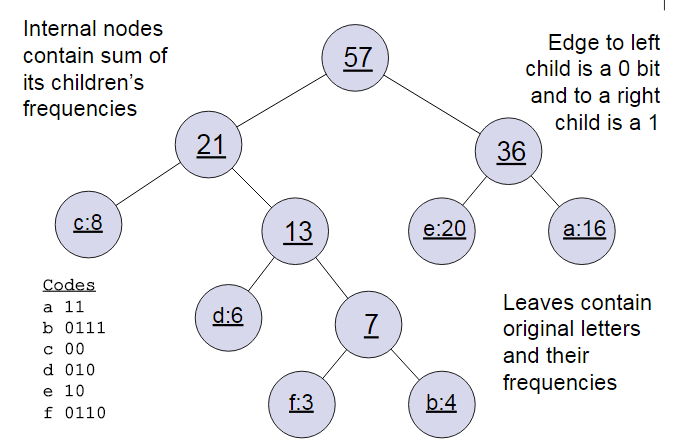
那麼霍夫曼樹有什麼好處呢?一般得到霍夫曼樹後我們會對葉子節點進行霍夫曼編碼,由於權重高的葉子節點越靠近根節點,而權重低的葉子節點會遠離根節點,這樣我們的高權重節點編碼值較短,而低權重值編碼值較長。這保證的樹的帶權路徑最短,也符合我們的資訊理論,即我們希望越常用的詞擁有更短的編碼。如何編碼呢?一般對於一個霍夫曼樹的節點(根節點除外),可以約定左子樹編碼為0,右子樹編碼為1.如上圖,則可以得到c的編碼是00。
在word2vec中,約定編碼方式和上面的例子相反**,即約定左子樹編碼為1,右子樹編碼為0**,同時約定左子樹的權重不小於右子樹的權重。
三、 基於Hierarchical Softmax的模型
3.1 基於Hierarchical Softmax的模型概述
我們先回顧下傳統的神經網路詞向量語言模型,裡面一般有三層,輸入層(詞向量),隱藏層和輸出層(softmax層)。裡面最大的問題在於從隱藏層到輸出的softmax層的計算量很大,因為要計算所有詞的softmax概率,再去找概率最大的值。這個模型如下圖所示。其中 是詞彙表的大小,
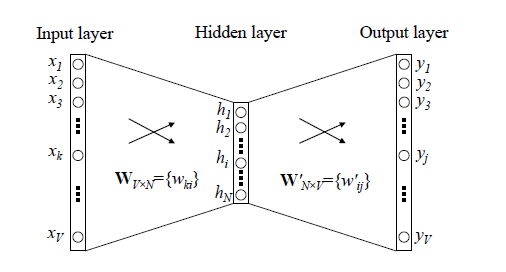
word2vec對這個模型做了改進,首先,對於從輸入層到隱藏層的對映,沒有采取神經網路的線性變換加啟用函式的方法,而是採用簡單的對所有輸入詞向量求和並取平均的方法。比如輸入的是三個4維詞向量:(1,2,3,4),(9,6,11,8),(5,10,7,12),那麼我們word2vec對映後的詞向量就是(5,6,7,8)。由於這裡是從多個詞向量變成了一個詞向量。
第二個改進就是從隱藏層到輸出的softmax層這裡的計算量改進。為了避免要計算所有詞的softmax概率,word2vec取樣了霍夫曼樹來代替從隱藏層到輸出softmax層的對映。我們在上一章已經介紹了霍夫曼樹的原理。如何對映呢?這裡就是理解word2vec的關鍵所在了。
由於我們把之前所有都要計算的從輸出softmax層的概率計算變成了一顆二叉霍夫曼樹,那麼我們的softmax概率計算只需要沿著樹形結構進行就可以了。如下圖所示,我們可以沿著霍夫曼樹從根節點一直走到我們的葉子節點的詞 。

和之前的神經網路語言模型相比,我們的霍夫曼樹的所有內部節點就類似之前神經網路隱藏層的神經元,其中,根節點的詞向量對應我們的投影后的詞向量,而所有葉子節點就類似於之前神經網路softmax輸出層的神經元,葉子節點的個數就是詞彙表的大小。在霍夫曼樹中,隱藏層到輸出層的softmax對映不是一下子完成的,而是沿著霍夫曼樹一步步完成的,因此這種softmax取名為"Hierarchical Softmax"。
如何“沿著霍夫曼樹一步步完成”呢?在word2vec中,我們採用了二元邏輯迴歸的方法,即規定沿著左子樹走,那麼就是負類(霍夫曼樹編碼1),沿著右子樹走,那麼就是正類(霍夫曼樹編碼0)。判別正類和負類的方法是使用sigmoid函式,即:
其中 是當前內部節點的詞向量,而 則是我們需要從訓練樣本求出的邏輯迴歸的模型引數。
使用霍夫曼樹有什麼好處呢?首先,由於是二叉樹,之前計算量為 現在變成了 。第二,由於使用霍夫曼樹是高頻的詞靠近樹根,這樣高頻詞需要更少的時間會被找到,這符合我們的貪心優化思想。
容易理解,被劃分為左子樹而成為負類的概率為 。在某一個內部節點,要判斷是沿左子樹還是右子樹走的標準就是看 , 誰的概率值大。而控制 , 誰的概率值大的因素一個是當前節點的詞向量,另一個是當前節點的模型引數 。
對於上圖中的 ,如果它是一個訓練樣本的輸出,那麼我們期望對於裡面的隱藏節點 的 概率大, 的 概率大, 的 概率大。
回到基於Hierarchical Softmax的word2vec本身,我們的目標就是找到合適的所有節點的詞向量和所有內部節點 , 使訓練樣本達到最大似然。那麼如何達到最大似然呢?
3.2 基於Hierarchical Softmax的模型梯度計算
我們使用最大似然法來尋找所有節點的詞向量和所有內部節點
。先拿上面的
例子來看,我們期望最大化下面的似然函式: