
Mask RCNN 實現視訊和圖片中的多人姿態檢測
Mask RCNN是目標分割檢測框架--擴充套件到人體關鍵點檢測
對於原理不清晰的同學,建議你去看一下Kaming He的論文:https://arxiv.org/pdf/1703.06870.pdf
我的部落格裡也有論文的翻譯版:Mask R-CNN 論文翻譯
對於視訊中的多人進行姿態估計,預訓練權重,可以直接下載:連結: mask_rcnn_humanpose.h5 密碼: qx8f
我已將Mask rcnn擴充套件到多人姿態估計的程式碼上傳到我的github上了:Keypoints-of-humanpose-with-Mask-R-CNN
如果覺得對你專案有用的話,點個star吧!
1、安裝環境:
1、電腦環境:
Mask R-CNN是基於Python3,Keras,TensorFlow。
- Python 3.4+
- TensorFlow 1.3+
- Keras 2.0.8+
- Jupyter Notebook
- Numpy, skimage, scipy, Pillow, cython, h5py
- opencv 2.0
2、預訓練權重下載:連結: mask_rcnn_humanpose.h5 密碼: qx8f
3、如果需要在COCO資料集上訓練或測試,需要安裝pycocotools, clone下來,
make生成對應的檔案,make之後將生成的pycocotools資料夾複製到專案資料夾中:
Linux: https://github.com/waleedka/coco
Windows: https://github.com/philferriere/cocoapi. You must have the Visual C++ 2015 build tools on your path (see the repo for additional details)
4、MS COCO資料集(Ubuntu 建議採用 wget 命令直接Ubuntu終端下載)
2、人體姿態估計原理:
MaskR-CNN可以拓寬到多人姿態估計的領域中。對於每一個生成的候選區域進行檢測,當檢測到該區域包含人這一種類時,會對人體身上每一個關鍵點的位置進行獨熱編碼。M個掩碼對應於人體的M個關鍵點型別之一,圖3.11所示為關鍵點檢測網路,通過連線3*3的256維的卷積層,與連線的反捲積層進行雙線性上取樣。最後,為每個關鍵點的輸出一個56*56的特徵圖。
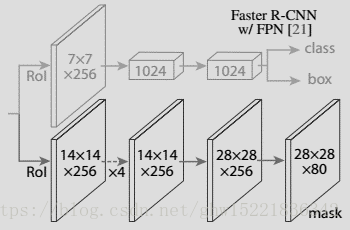
One-hot獨熱編碼為一位有效編碼,利用K位狀態暫存器來對N個狀態進行編碼,每個暫存器都是相互獨立的,在任何條件下只有一位one-hot編碼可以作為分類變數的二進位制向量表示。分配關鍵點時,人體每個部位的關鍵點對應於一個one-hot掩碼,訓練的目標最終是得到一個56*56的二值掩碼,當中只有一個畫素被標記為關鍵點,其餘畫素均為背景。對於每一個關鍵點的位置,進行最小化平均交叉熵損失檢測,K個關鍵點是被獨立處理的。
人體姿態檢測中,人本身可以作為一個目標例項進行分類檢測。但是,採取了one-hot編碼以後,就可以擴充套件到coco資料集中被標註的17個人體關鍵點(例如:左眼、右耳),同時也能夠處理非連續型數值特徵。
3、人體關鍵資料集:
我採用的是coco keypoint 2017資料集進行訓練和測試:
包含(鼻子,左眼,右眼,左耳,右耳,左肩,右肩,左肘,右肘,左手腕,右手腕,左膝蓋,右膝蓋,左腳踝,右腳踝,左小腿,右小腿):
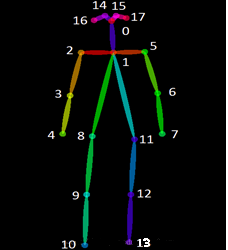
17個人體關鍵點標註
4、程式碼:
如何對於視訊中的多人進行姿態檢測,請開啟專案中的 video_demo.py
可以實現對於視訊中的行人進行姿態檢測!
cap = cv2.VideoCapture('humantest2.avi')#s視訊的名字
size = (
int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)),
int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
)
codec = cv2.VideoWriter_fourcc(*'DIVX')
output = cv2.VideoWriter('human2.avi',codec,25.0,size) #輸出視訊的名字
i = 0
frame_rate_divider = 1
while(cap.isOpened()):
stime = time.time()
ret, frame = cap.read()
if ret:
if i % frame_rate_divider == 0:
results = model.detect_keypoint([frame], verbose=0)
r = results[0]
# for one image
log("rois", r['rois'])
log("keypoints", r['keypoints'])
log("class_ids", r['class_ids'])
log("keypoints", r['keypoints'])
log("masks", r['masks'])
log("scores", r['scores'])
result_frame = cv2_display_keypoint(frame,r['rois'],r['keypoints'],r['masks'],r['class_ids'],r['scores'],class_names)
output.write(result_frame)
cv2.imshow('frame', result_frame)
i += 1
else:
i += 1
print('FPS {:.1f}'.format(1 / (time.time() - stime)))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
else:
break
cap.release()
output.release()
cv2.destroyAllWindows()大家可以把程式碼下載下來,然後用我訓練好的模型進行預訓練,遇到任何問題,在評論區留下你的問題,我會盡力去解決!
附幾張檢測效果圖:


我後面會更新 mobileNet_v1版的Mask R-CNN,模型更小,執行速度更快,檢測精度也很高!