
10種大併發伺服器設計方案
常見併發伺服器方案
-
迴圈式/迭代式伺服器:短連結
缺點:無法充分利用多核CPU,不適合執行時間較長的服務 -
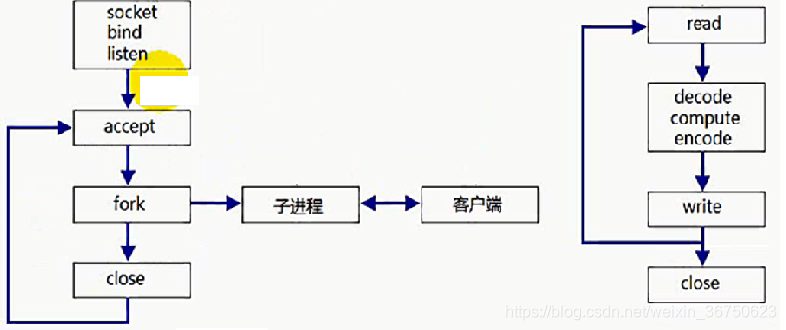
併發式伺服器:長連線
(1)主程序負責監聽client的連線請求
(2)當連線建立後,新fork一個子程序與client通訊
適應場景:適用於執行時間比較長的服務
-
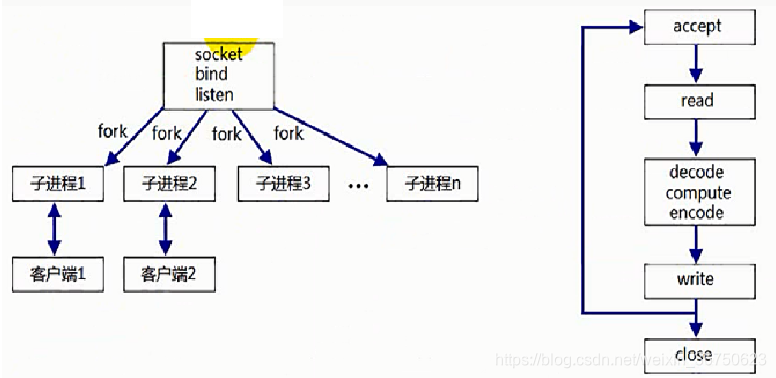
prefork伺服器
(1)父程序進行listen,然後先fork出大量的子程序===>此時,父子程序都listen客戶端的到來
(2)當client連線到來時,可能導致大量的accept返回,但是隻有一個accept返回是正確的(只有一個能建立連線成功),其他的是錯誤的,這種現象叫做“驚群現象”,關於驚群現象請參考UNP2e 第27章
-
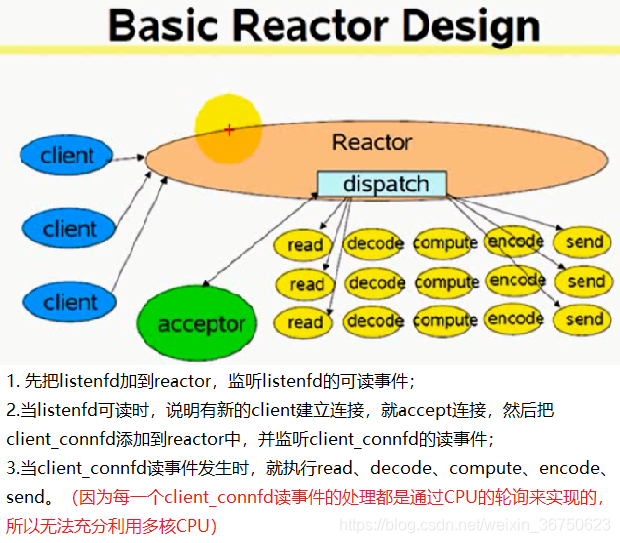
反應式(reactive)伺服器(reactor模式)
(1)select/poll/epoll
(2)併發處理多個請求,實際上是在一個執行緒中完成。無法充分利用多核CPU
(3)不適合執行時間比較長的服務,所以為了讓客戶感覺是在“併發”處理而不是“迴圈”處理,每個請求必須在相對較短時間內執行
-
reactor + thread per request (過渡方案)
-
reactor + worker thread (過渡方案)
-
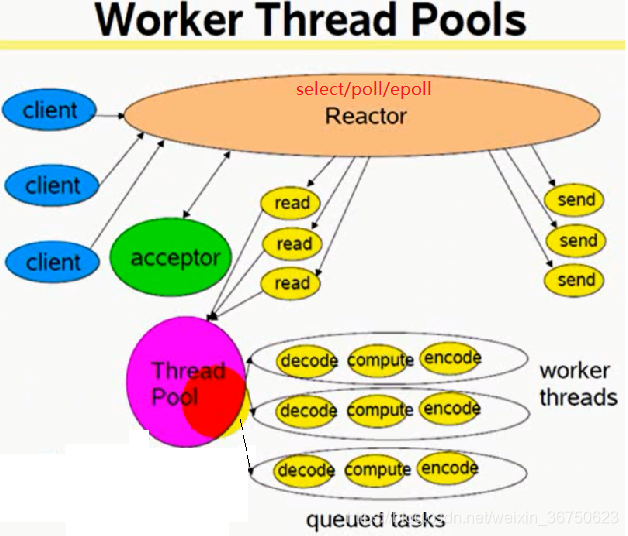
reactor + thread pool (能適應密集計算)
(1) Reactor監聽到讀事件到來後,將呼叫read函式讀取資料,此過程參考select伺服器程式,是在單執行緒中完成的
(2) 將上面讀到的資料,封裝成一個一個的任務,新增到任務佇列中,並通知執行緒池中的空閒執行緒去處理任務(decode、compute、encode)
(3) 當處理完一條任務後,再將處理的結果新增到select的寫事件上
(4) select發現可寫事件發生,就會呼叫send將資料傳送出去
總結:此模式是reactor + thread per request模式的升級版本,因為select僅僅只進行I/O操作,比較耗時的compute任務由執行緒去處理,所以該模式適用於計算密集型任務。
-
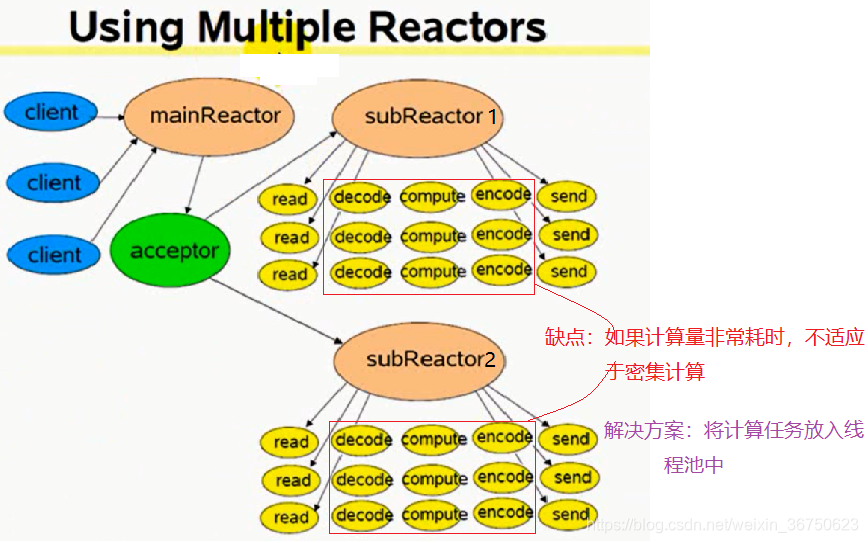
multiple reactors (能適應更大的突發I/O)
reactor in threads ( one Eventloop per thread ) 每個執行緒都是一個事件迴圈
reactor in processes ( one loop per process)
特點:
(1) 該模式有多個reactor,即有多個事件迴圈
(2) 每個reactor都是一個執行緒或者一個程序
優點:
當只使用一個mainReactor進行監聽listenfd、conn_fd的讀事件時,可能mainReactor會出現瓶頸,而使用mainReactor+subReactor+subReactor的方式可以解決瓶頸的問題
**如何使用?**假設有3個千兆網絡卡,可以每個網絡卡都分配一個subReactor
模式執行流程詳解:
(1) mainReactor、subReactor、subReactor分別處在三個執行緒中
(2) mainReactor中存放著listenfd,監聽listenfd的讀事件
(3) 當發現client連線請求後,由acceptor接收連線,並把接收到的連線conn_fd1放入subReactor1中,由subReactor1監聽conn_fd1的讀事件
(4) 當再次發現client連線請求後,由acceptor接收連線,並把接收到的連線conn_fd2放入subReactor2中,由subReactor2監聽conn_fd2的讀事件
(5) 當再次發現client連線請求後,由acceptor接收連線,並把接收到的連線conn_fd3放入subReactor1中,由subReactor1監聽conn_fd3的讀事件
(6) 下次連線放入subReactor2中,… …,新的連線交替的放入subReactor1、subReactor2,此種方式叫“倫叫”(round robin),可以保證連線均勻的分佈到多個subReactor/事件迴圈中。
-
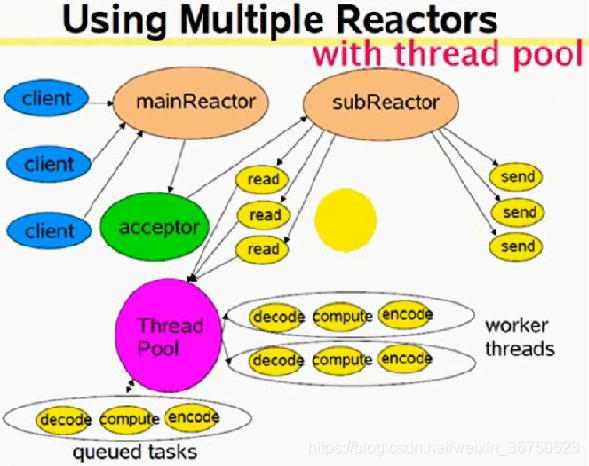
multiple reactors + thread pool (one loop per thread + threadpool) (突發I/O與密集計算)
說明:該模式是在 multiple reactors 模式上添加了thread pool,用來解決耗時的compute操作
-
proactor伺服器 (proactor模式,基於非同步I/O)
(1)理論上 proactor比reactor效率更高一些
(2)非同步I/O能夠讓I/O操作與計算重疊。充分利用DMA直接儲存訪問特性
(3)Linux非同步IO
[1] glibc aio (aio* ),有bug
[2] kernel native aio (aio*),也不完美。目前僅支援O_DIRECT方式來對磁碟讀寫,跳過系統快取。要自己實現快取,難度不小
(4)boost asio實現的proactor,實際上不是真正意義上的非同步I/O,底層是用epoll來實現的,模擬非同步I/O的
man aio_read
int aio_read(struct aiocb *aiocbp);
man 7 aio
struct aiocb {
/* The order of these fields is implementation-dependent */
int aio_fildes; /* File descriptor */
off_t aio_offset; /* File offset */
volatile void *aio_buf; 緩衝區 /* Location of buffer */
size_t aio_nbytes; /* Length of transfer */
int aio_reqprio; /* Request priority */
struct sigevent aio_sigevent; /* Notification method */
int aio_lio_opcode; /* Operation to be performed;
lio_listio() only */
/* Various implementation-internal fields not shown */
};