
Redis面試題(一): Redis到底是多執行緒還是單執行緒?
0. redis單執行緒問題
單執行緒指的是網路請求模組使用了一個執行緒(所以不需考慮併發安全性),即一個執行緒處理所有網路請求,其他模組仍用了多個執行緒。
1. 為什麼說redis能夠快速執行
(1) 絕大部分請求是純粹的記憶體操作(非常快速)
(2) 採用單執行緒,避免了不必要的上下文切換和競爭條件
(3) 非阻塞IO - IO多路複用
2. redis的內部實現
內部實現採用epoll,採用了epoll+自己實現的簡單的事件框架。epoll中的讀、寫、關閉、連線都轉化成了事件,然後利用epoll的多路複用特性,絕不在io上浪費一點時間 這3個條件不是相互獨立的,特別是第一條,如果請求都是耗時的,採用單執行緒吞吐量及效能可想而知了。應該說redis為特殊的場景選擇了合適的技術方案。
3. Redis關於執行緒安全問題
redis實際上是採用了執行緒封閉的觀念,把任務封閉在一個執行緒,自然避免了執行緒安全問題,不過對於需要依賴多個redis操作的複合操作來說,依然需要鎖,而且有可能是分散式鎖。
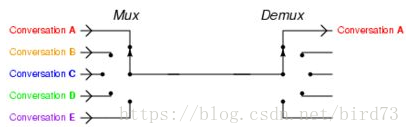
4. IO多路複用
參考: https://www.zhihu.com/question/32163005
要弄清問題先要知道問題的出現原因
原因:
由於程序的執行過程是線性的(也就是順序執行),當我們呼叫低速系統I/O(read,write,accept等等),程序可能阻塞,此時程序就阻塞在這個呼叫上,不能執行其他操作.阻塞很正常.
接下來考慮這麼一個問題:一個伺服器程序和一個客戶端程序通訊,伺服器端read(sockfd1,bud,bufsize),此時客戶端程序沒有傳送資料,那麼read(阻塞呼叫)將阻塞,直到客戶端呼叫write(sockfd,but,size)發來資料.在一個客戶和伺服器通訊時這沒什麼問題;
當多個客戶與伺服器通訊時當多個客戶與伺服器通訊時,若伺服器阻塞於其中一個客戶sockfd1,當另一個客戶的資料到達套接字sockfd2時,伺服器不能處理,仍然阻塞在read(sockfd1,...)上;此時問題就出現了,不能及時處理另一個客戶的服務,咋麼辦?
I/O多路複用來解決!
I/O多路複用:
繼續上面的問題,有多個客戶連線,sockfd1,sockfd2,sockfd3..sockfdn同時監聽這n個客戶,當其中有一個發來訊息時就從select的阻塞中返回,然後就呼叫read讀取收到訊息的sockfd,然後又迴圈回select阻塞;這樣就不會因為阻塞在其中一個上而不能處理另一個客戶的訊息
Q:
那這樣子,在讀取socket1的資料時,如果其它socket有資料來,那麼也要等到socket1讀取完了才能繼續讀取其它socket的資料吧。那不是也阻塞住了嗎?而且讀取到的資料也要開啟執行緒處理吧,那這和多執行緒IO有什麼區別呢?
A:
1.CPU本來就是線性的不論什麼都需要順序處理並行只能是多核CPU
2.io多路複用本來就是用來解決對多個I/O監聽時,一個I/O阻塞影響其他I/O的問題,跟多執行緒沒關係.
3.跟多執行緒相比較,執行緒切換需要切換到核心進行執行緒切換,需要消耗時間和資源.而I/O多路複用不需要切換線/程序,效率相對較高,特別是對高併發的應用nginx就是用I/O多路複用,故而效能極佳.但多執行緒程式設計邏輯和處理上比I/O多路複用簡單.而I/O多路複用處理起來較為複雜.
5. 使用Redis有哪些好處?
(1) 速度快,因為資料存在記憶體中,類似於HashMap,HashMap的優勢就是查詢和操作的時間複雜度都是O(1)
(2) 支援豐富資料型別,支援string,list,set,sorted set,hash
(3) 支援事務,操作都是原子性,所謂的原子性就是對資料的更改要麼全部執行,要麼全部不執行
(4) 豐富的特性:可用於快取,訊息,按key設定過期時間,過期後將會自動刪除
6. Redis相比memcached有哪些優勢?
(1) memcached所有的值均是簡單的字串,redis作為其替代者,支援更為豐富的資料型別
(2) redis的速度比memcached快很多
(3) redis可以持久化其資料
(4)Redis支援資料的備份,即master-slave模式的資料備份。
(5) 使用底層模型不同,它們之間底層實現方式 以及與客戶端之間通訊的應用協議不一樣。Redis直接自己構建了VM 機制 ,因為一般的系統呼叫系統函式的話,會浪費一定的時間去移動和請求。
(6)value大小:redis最大可以達到1GB,而memcache只有1MB
7. Redis常見效能問題和解決方案:
(1) Master最好不要做任何持久化工作,如RDB記憶體快照和AOF日誌檔案;(Master寫記憶體快照,save命令排程rdbSave函式,會阻塞主執行緒的工作,當快照比較大時對效能影響是非常大的,會間斷性暫停服務,所以Master最好不要寫記憶體快照;AOF檔案過大會影響Master重啟的恢復速度)
(2) 如果資料比較重要,某個Slave開啟AOF備份資料,策略設定為每秒同步一次
(3) 為了主從複製的速度和連線的穩定性,Master和Slave最好在同一個區域網內
(4) 儘量避免在壓力很大的主庫上增加從庫
(5) 主從複製不要用圖狀結構,用單向連結串列結構更為穩定,即:Master <- Slave1 <- Slave2 <- Slave3...;這樣的結構方便解決單點故障問題,實現Slave對Master的替換。如果Master掛了,可以立刻啟用Slave1做Master,其他不變。
8. Redis的回收策略
volatile-lru:從已設定過期時間的資料集(server.db[i].expires)中挑選最近最少使用的資料淘汰
volatile-ttl:從已設定過期時間的資料集(server.db[i].expires)中挑選將要過期的資料淘汰
volatile-random:從已設定過期時間的資料集(server.db[i].expires)中任意選擇資料淘汰
allkeys-lru:從資料集(server.db[i].dict)中挑選最近最少使用的資料淘汰
allkeys-random:從資料集(server.db[i].dict)中任意選擇資料淘汰
no-enviction(驅逐):禁止驅逐資料
注意這裡的6種機制,volatile和allkeys規定了是對已設定過期時間的資料集淘汰資料還是從全部資料集淘汰資料,後面的lru、ttl以及random是三種不同的淘汰策略,再加上一種no-enviction永不回收的策略。
使用策略規則:
1、如果資料呈現冪律分佈,也就是一部分資料訪問頻率高,一部分資料訪問頻率低,則使用allkeys-lru
2、如果資料呈現平等分佈,也就是所有的資料訪問頻率都相同,則使用allkeys-random
9. 五種I/O模型介紹
IO 多路複用是5種I/O模型中的第3種,對各種模型講個故事,描述下區別:
故事情節為:老李去買火車票,三天後買到一張退票。參演人員(老李,黃牛,售票員,快遞員),往返車站耗費1小時。
1.阻塞I/O模型
老李去火車站買票,排隊三天買到一張退票。
耗費:在車站吃喝拉撒睡 3天,其他事一件沒幹。
2.非阻塞I/O模型
老李去火車站買票,隔12小時去火車站問有沒有退票,三天後買到一張票。
耗費:往返車站6次,路上6小時,其他時間做了好多事。
3.I/O複用模型
1.select/poll
老李去火車站買票,委託黃牛,然後每隔6小時電話黃牛詢問,黃牛三天內買到票,然後老李去火車站交錢領票。
耗費:往返車站2次,路上2小時,黃牛手續費100元,打電話17次
2.epoll
老李去火車站買票,委託黃牛,黃牛買到後即通知老李去領,然後老李去火車站交錢領票。
耗費:往返車站2次,路上2小時,黃牛手續費100元,無需打電話
4.訊號驅動I/O模型
老李去火車站買票,給售票員留下電話,有票後,售票員電話通知老李,然後老李去火車站交錢領票。
耗費:往返車站2次,路上2小時,免黃牛費100元,無需打電話
5.非同步I/O模型
老李去火車站買票,給售票員留下電話,有票後,售票員電話通知老李並快遞送票上門。
耗費:往返車站1次,路上1小時,免黃牛費100元,無需打電話
1同2的區別是:自己輪詢
2同3的區別是:委託黃牛
3同4的區別是:電話代替黃牛
4同5的區別是:電話通知是自取還是送票上門