
java利用Freemarker模板生成docx格式的word文件
之前寫過一篇利用Freemarker模板生成doc的部落格,不過那個部落格有點缺陷,生成的word佔用的空間很大,幾百頁的word有將近100M了。所以,後面需求必須是生成的docx文件,結果匯出後正常才幾M,昨天花了一天的時間實現。
具體思路
1.把docx文件修改為ZIP格式(修改.docx字尾名為.zip)
2.獲取zip裡的document.xml文件以及_rels資料夾下的document.xml.rels文件
3.把內容填充到document.xml裡,以及圖片配置資訊填充至document.xml.rels文件裡
4.在輸入docx文件的時候把填充過內容的的 document.xml、document.xml.rels用流的方式寫入zip(詳見下面程式碼)。
5.把圖片寫入zip檔案下word/media資料夾中
6.輸出docx文件
docx模板修改成zip格式後的資訊如下(因為word文件本身就是ZIP格式實現的)
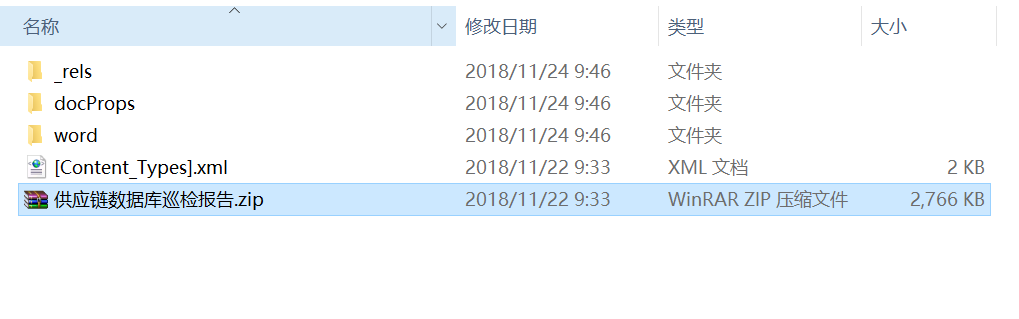
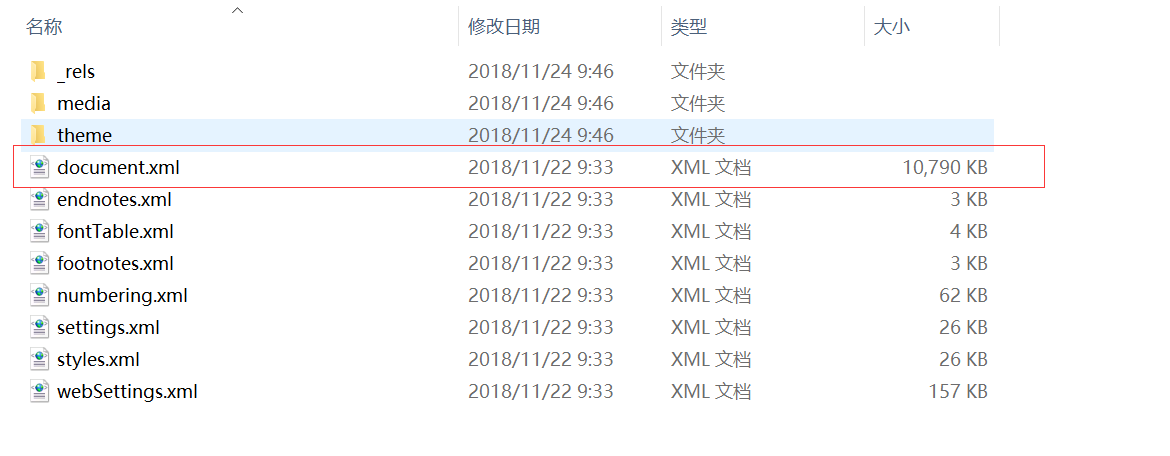
- document.xml裡存放主要資料
- media存放圖片資訊
- _rels裡存放配置資訊
注意:如果docx模板裡的圖片帶有具體路徑的話,則圖片的格式不受限制。
如果docx模板裡裡圖片資訊不帶路徑,則模板僅支援和模板圖片型別一致的圖片。
處理流程
1.準備好docx模板
2.把docx文件修改為ZIP格式(修改.docx字尾名為.zip)
3.獲取zip檔案裡的word資料夾下的document.xml以及_rels資料夾裡的document.xml.rels檔案作為模板。
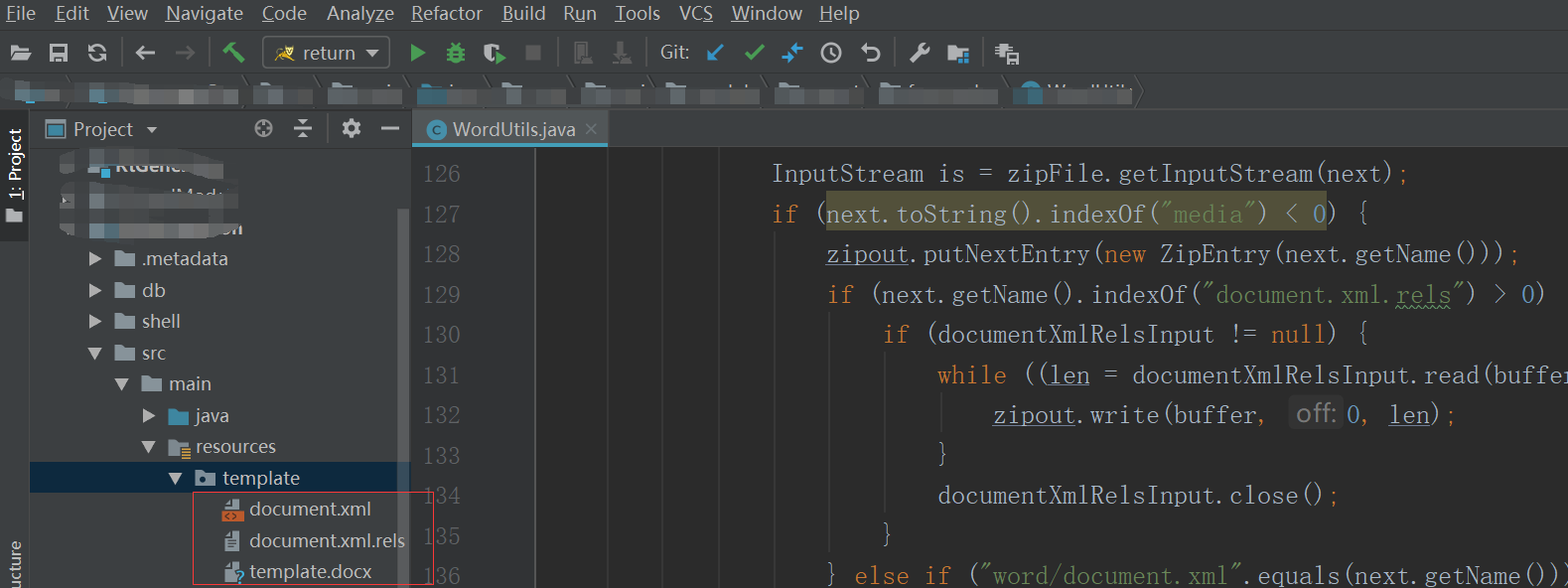
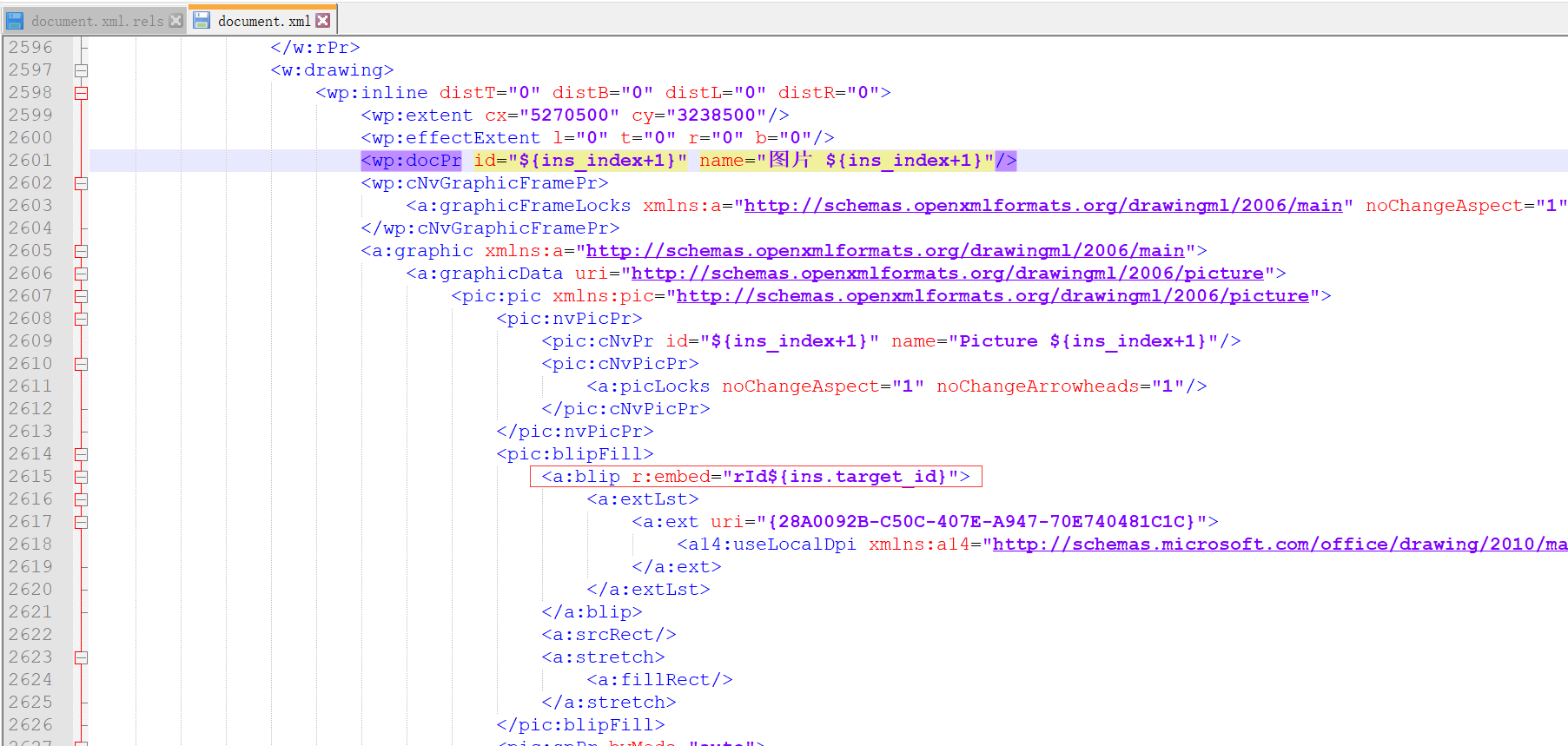
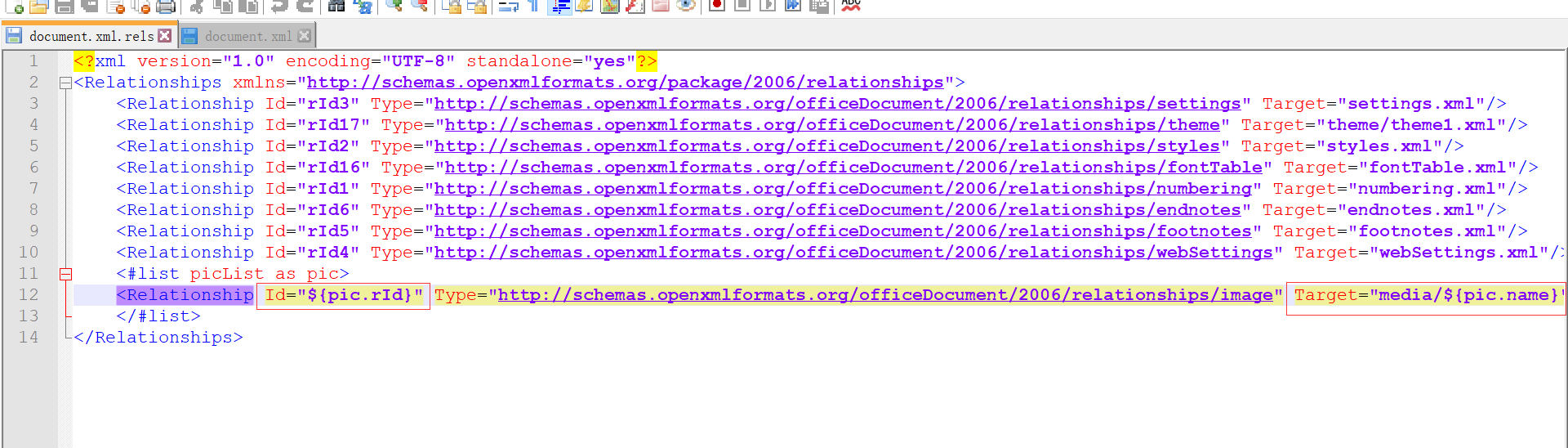
注意:這裡圖片配置資訊是根據 rId來獲取的,為了避免重複,可以根據自己具體的業務規則來實現
4.填充模板資訊、寫入圖片資訊。
//outputStream 輸出流可以自己定義 瀏覽器或者檔案輸出流
public static void createDocx(Map dataMap,OutputStream outputStream) {
ZipOutputStream zipout = null;
try {
//圖片配置檔案模板
ByteArrayInputStream documentXmlRelsInput =FreeMarkUtils.getFreemarkerContentInputStream(dataMap, documentXmlRels);
//內容模板
ByteArrayInputStream documentInput = FreeMarkUtils.getFreemarkerContentInputStream(dataMap, document);
//最初設計的模板
File docxFile = new File(WordUtils.class.getClassLoader().getResource(template).getPath());
if (!docxFile.exists()) {
docxFile.createNewFile();
}
ZipFile zipFile = new ZipFile(docxFile);
Enumeration<? extends ZipEntry> zipEntrys = zipFile.entries();
zipout = new ZipOutputStream(outputStream);
//開始覆蓋文件------------------
int len = -1;
byte[] buffer = new byte[1024];
while (zipEntrys.hasMoreElements()) {
ZipEntry next = zipEntrys.nextElement();
InputStream is = zipFile.getInputStream(next);
if (next.toString().indexOf("media") < 0) {
zipout.putNextEntry(new ZipEntry(next.getName()));
if (next.getName().indexOf("document.xml.rels") > 0) { //如果是document.xml.rels由我們輸入
if (documentXmlRelsInput != null) {
while ((len = documentXmlRelsInput.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
documentXmlRelsInput.close();
}
} else if ("word/document.xml".equals(next.getName())) {//如果是word/document.xml由我們輸入
if (documentInput != null) {
while ((len = documentInput.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
documentInput.close();
}
} else {
while ((len = is.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
is.close();
}
}
}
//寫入圖片
List<Map<String, Object>> picList = (List<Map<String, Object>>) dataMap.get("picList");
for (Map<String, Object> pic : picList) {
ZipEntry next = new ZipEntry("word" + separator + "media" + separator + pic.get("name"));
zipout.putNextEntry(new ZipEntry(next.toString()));
InputStream in = (ByteArrayInputStream)pic.get("code");
while ((len = in.read(buffer)) != -1) {
zipout.write(buffer, 0, len);
}
in.close();
}
} catch (Exception e) {
logger.error("word匯出失敗:"+e.getStackTrace());
}finally {
if(zipout!=null){
try {
zipout.close();
} catch (IOException e) {
logger.error("io異常");
}
}
if(outputStream!=null){
try {
outputStream.close();
} catch (IOException e) {
logger.error("io異常");
}
}
}
}/**
* 獲取freemarker模板字串
* @author lpf
*/
public class FreeMarkUtils {
private static Logger logger = LoggerFactory.getLogger(FreeMarkUtils.class);
public static Configuration getConfiguration(){
//建立配置例項
Configuration configuration = new Configuration(Configuration.VERSION_2_3_28);
//設定編碼
configuration.setDefaultEncoding("utf-8");
configuration.setClassForTemplateLoading(FreeMarkUtils.class, "/template");
return configuration;
}
/**
* 獲取模板字串輸入流
* @param dataMap 引數
* @param templateName 模板名稱
* @return
*/
public static ByteArrayInputStream getFreemarkerContentInputStream(Map dataMap, String templateName) {
ByteArrayInputStream in = null;
try {
//獲取模板
Template template = getConfiguration().getTemplate(templateName);
StringWriter swriter = new StringWriter();
//生成檔案
template.process(dataMap, swriter);
in = new ByteArrayInputStream(swriter.toString().getBytes("utf-8"));//這裡一定要設定utf-8編碼 否則匯出的word中中文會是亂碼
} catch (Exception e) {
logger.error("模板生成錯誤!");
}
return in;
}
}
5.輸出word測試
就是這麼簡單,比較麻煩的就是如果word比較複雜的話寫freemarkr標籤要仔細一些,還有word中的字元儘量對特殊字元有轉義,否則會引起word打不開的現象。
總結
這裡最重要的一個思想是把檔案輸出到ByteArrayOutputStream裡,下載的時候把這個位元組寫出就行了。開發的時候注意編碼問題,用這種方式匯出還有一個好處就是,你會發現,同樣一個word。匯出doc格式的檔案大小要比docx格式的檔案大小大的多,所以還是推薦用這種;