
語音識別語音合成
本節內容 預備資料:
1.FFmpeg:
連結:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg
密碼:w6hk
2.baidu-aip:
pip install baidu-aip
終於進入主題了,此篇是人工智慧應用的重點,只用現成的技術不做底層演算法,也是讓初級程式設計師快速進入人工智慧行業的捷徑
目前市面上主流的AI技術提供公司有很多,比如百度,阿里,騰訊,主做語音的科大訊飛,做只能問答的圖靈機器人等等
這些公司投入了很大一部分財力物力人力將底層封裝,提供應用介面給我們,尤其是百度,完全免費的介面
既然百度這麼仗義,咱們就不要浪費掉怎麼好的資源,從百度AI入手,開啟人工智慧之旅
開啟人工智慧技術的大門 : http://ai.baidu.com/
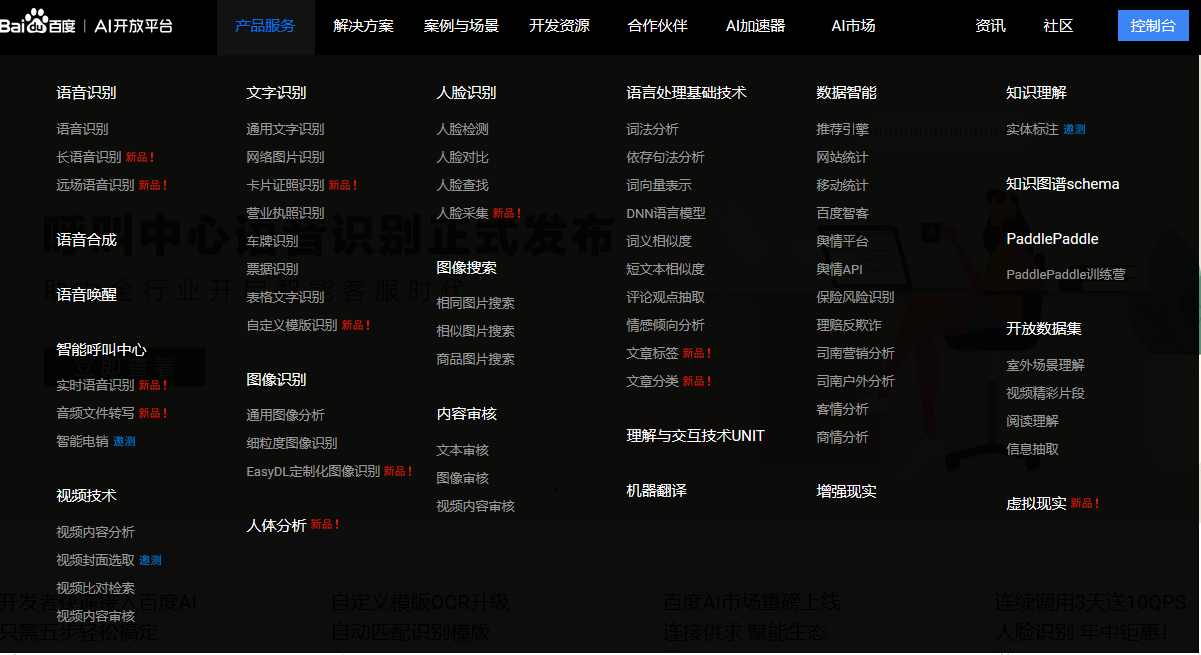
看看我大百度的AI大法,這些技術全部都是封裝好的介面,看著就爽
接下來咱們就一步一步的操作一下
首先進入控制檯,註冊一個百度的賬號(百度賬號通用)

開通一下我們百度AI開放平臺的授權
然後找到已開通服務中的百度語音
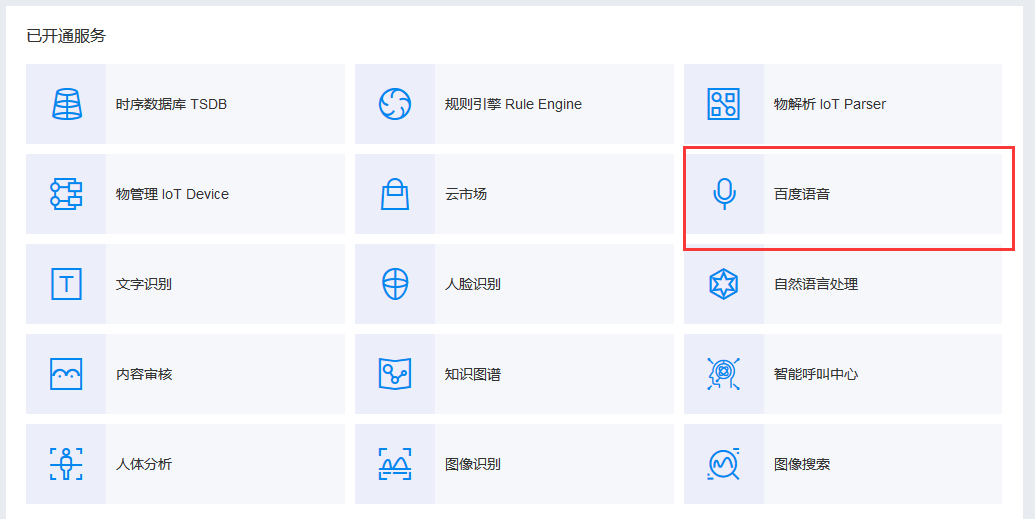
走到這裡,想必已經知道咱們要從語音入手了,語音識別和語音合成
開啟百度語音,進入語音應用管理介面,建立一個新的應用 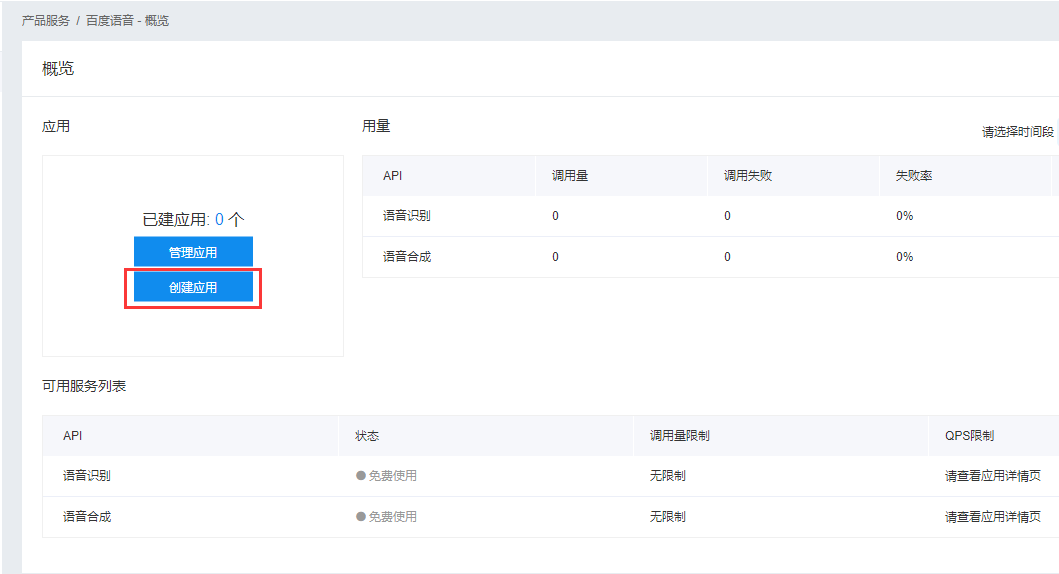
建立語音應用App

就可以建立應用了,回到應用列表我們可以看到已建立的應用了

這裡面有三個值 AppID , API Key , Secret Key 記住可以從這裡面看到 , 在之後的學習中我們會用到
好了 百度語音的應用已經建立完成了 接下來 我會用Python 程式碼作為例項進行應用及講解
一.安裝百度的人工智慧SDK:
首先咱們要 pip install baidu-aip 安裝一個百度人工智慧開放平臺的Python SDK實在是太方便了,這也是為什麼我們選擇百度人工智慧的最大原因
安裝完成之後就來測試一下:

在工程目錄下,就可以看到 s1.mp3 這個檔案了,來聽一聽
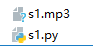
上面咱們測試了一個語音合成的例子,那麼就從語音合成開始入手
二.語音合成:
技術上,程式碼上任何的疑惑,都可以從官方文件中得到答案
baidu-aip Python SDK 語音合成技術文件 : https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top
剛才我們做了一個語音合成的例子,就用這個例子來展開說明
先來看第一段程式碼

這是與百度進行一次加密校驗 , 認證你是合法使用者 合法的應用
AipSpeech 是百度語音的客戶端 認證成功之後,客戶端將被開啟,這裡的client 就是已經開啟的百度語音的客戶端了
再來看第二段程式碼:

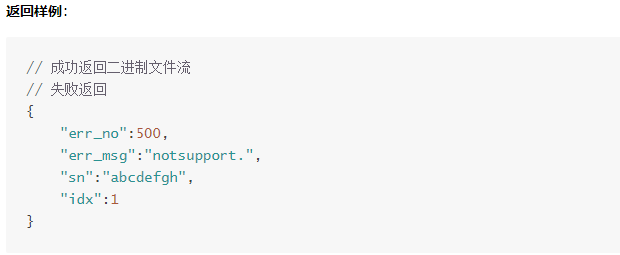
用百度語音客戶端中的synthesis方法,並提供相關引數
成功可以得到音訊檔案,失敗則返回一段錯誤資訊
重點看一下 synthesis 這個方法 , 從 https://ai.baidu.com/docs#/TTS-Online-Python-SDK/top 來獲得答案吧
從引數入手分析:

按照這些引數,從新發起一個語音合成

這次聲音是不是與一點點蘿莉了呢?
這都是語音語調的作用 0 - 9 其實就是 御姐音 - 蘿莉音
這就是人工智慧中的語音合成技術,呼叫百度的SDK,只用了5分鐘,完成了1年的開發量,哈哈哈哈
一定要自己練習一下語音合成, 別把它玩兒壞了
三.語音識別:
哎,每次到這裡,我都默默無語淚兩行,聲音這個東西格式太多樣化了,如果要想讓百度的SDK識別咱們的音訊檔案,就要想辦法轉變成百度SDK可以識別的格式PCM
目前DragonFire已知可以實現自動化轉換格式並且屢試不爽的工具 : FFmpeg 這個工具的下載地址是 : 連結:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg 密碼:w6hk
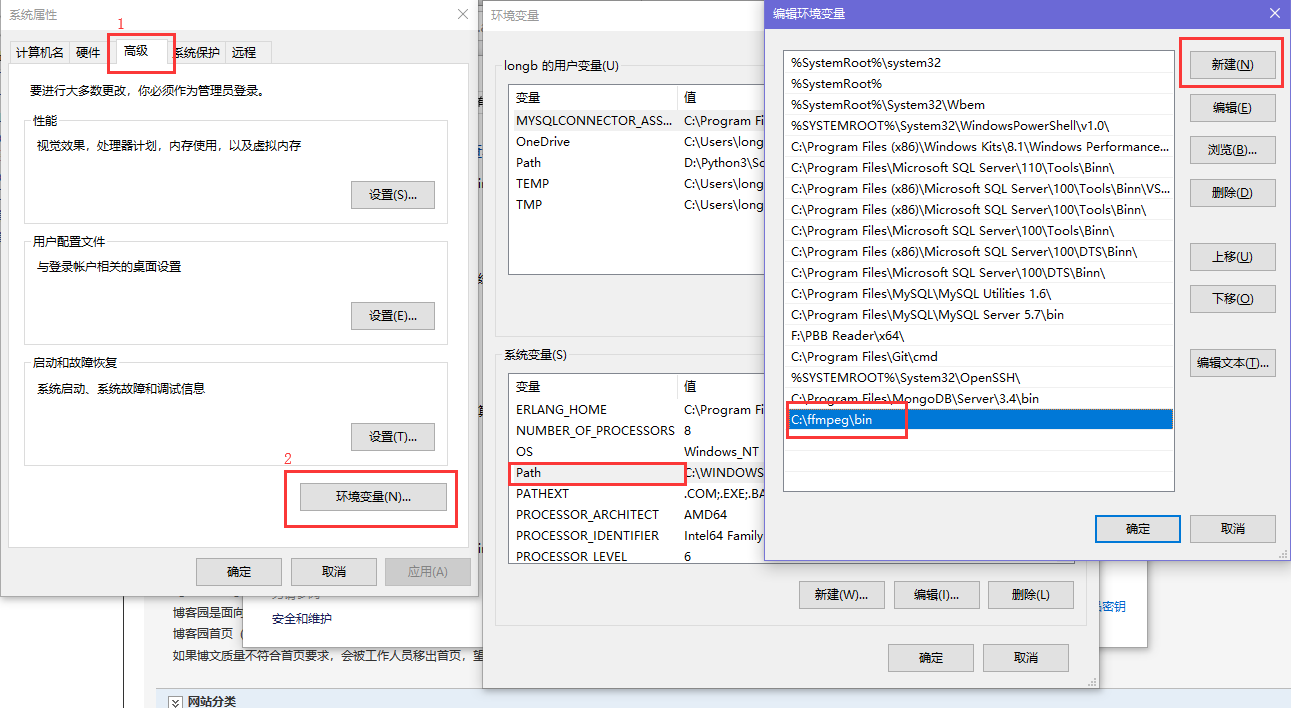
FFmpeg 環境變數配置:
首先你要解壓縮,然後找到bin目錄,我的目錄是 C:\ffmpeg\bin
然後 以 windows 10 為例,配置環境變數

如果沒搞明白的話,我也沒有辦法了,這麼清晰這麼明白
嘗試一下,是否配置成功
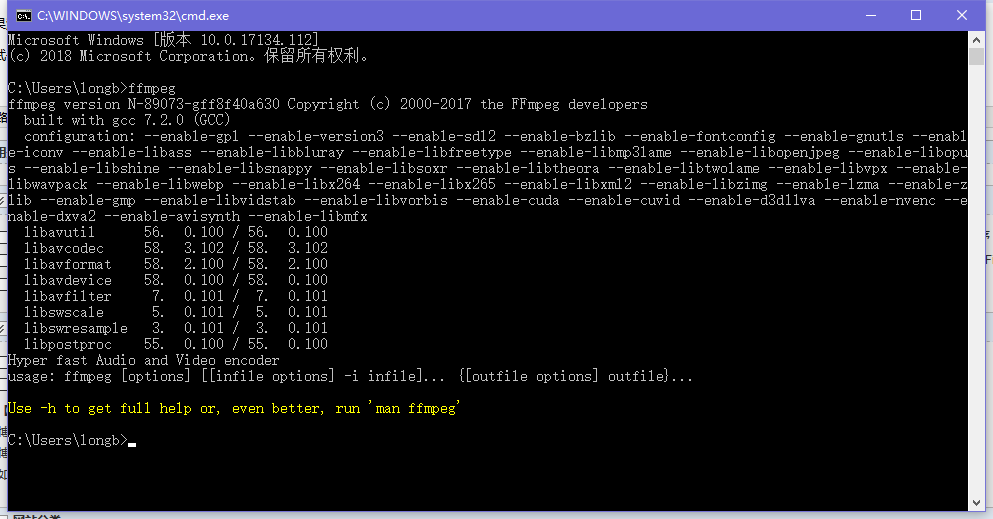
看到這個介面就算配置成功了,配置成功有什麼用呢, 這個工具可以將wav wma mp3 等音訊檔案轉換為 pcm 無壓縮音訊檔案
做一個測試,首先要開啟windows的錄音機,錄製一段音訊(說普通話)
現在假設錄製的音訊檔案的名字為 audio.wav 放置在 D:\DragonFireAudio\
然後我們用命令列對這個 audio.wav 進行pcm格式的轉換然後得到 audio.pcm
命令是 : ffmpeg -y -i audio.wav -acodec pcm_s16le -f s16le -ac 1 -ar 16000 audio.pcm
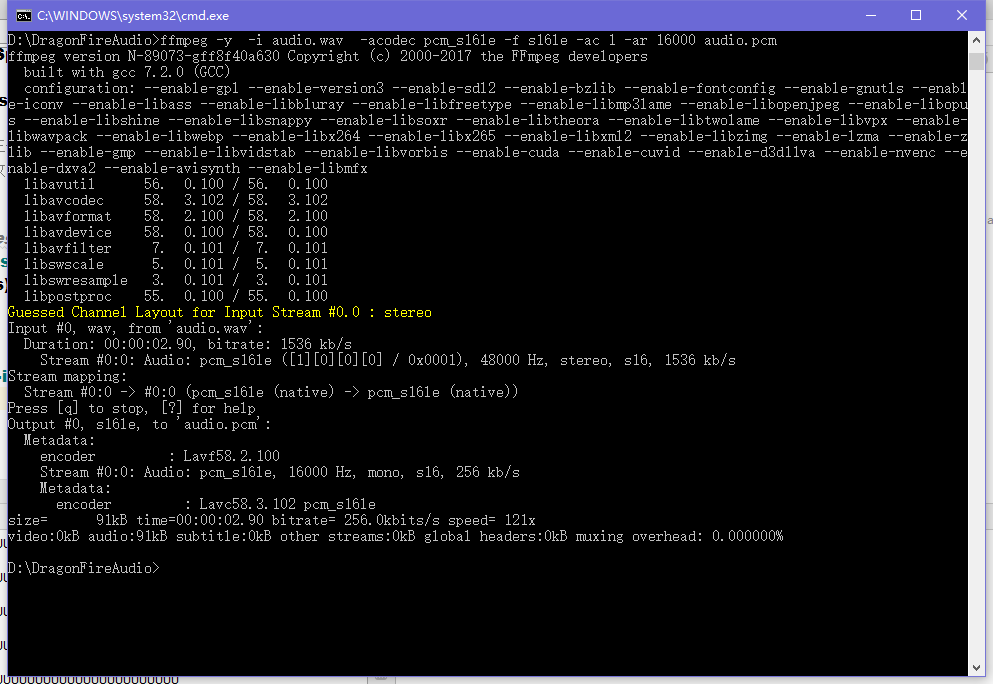
然後開啟目錄就可以看到pcm檔案了

pcm檔案已經得到了,趕緊進入正題吧
百度語音識別SDK的應用:
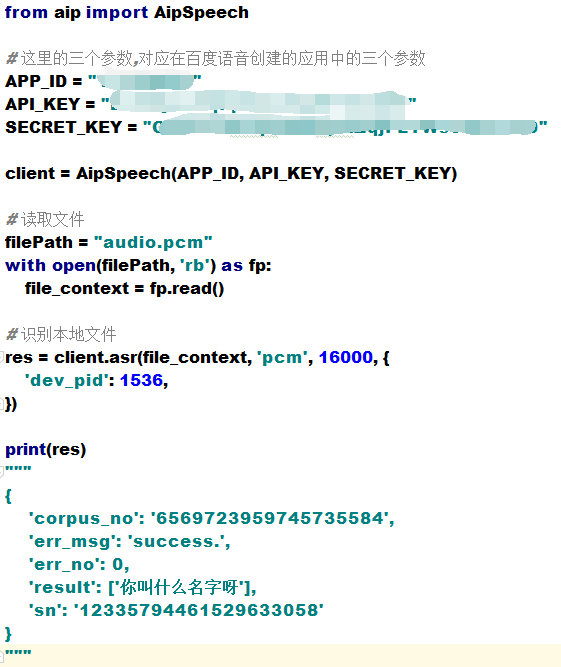
前提是你的audio.pcm 要與你當前的檔案在同一個目錄,還是分段看一下程式碼

讀取檔案的內容,file_context 是 audio.pcm 檔案開啟的二進位制流

asr函式需要四個引數,第四個引數可以忽略,自有預設值,參照一下這些引數是做什麼的
第一個引數: speech 音訊檔案流 建立包含語音內容的Buffer物件, 語音檔案的格式,pcm 或者 wav 或者 amr。(雖說支援這麼多格式,但是隻有pcm的支援是最好的)
第二個引數: format 檔案的格式,包括pcm(不壓縮)、wav、amr (雖說支援這麼多格式,但是隻有pcm的支援是最好的)
第三個引數: rate 音訊檔案取樣率 如果使用剛剛的FFmpeg的命令轉換的,你的pcm檔案就是16000
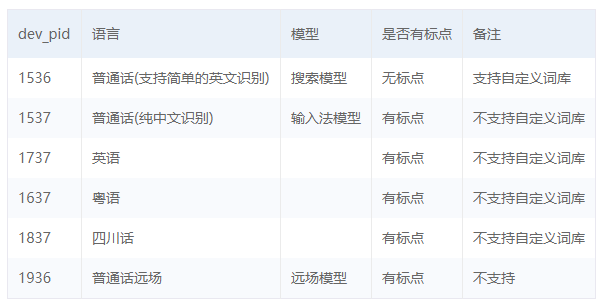
第四個引數: dev_pid 音訊檔案語言id 預設1537(普通話 輸入法模型)
再來看下一段程式碼,列印返回結果:
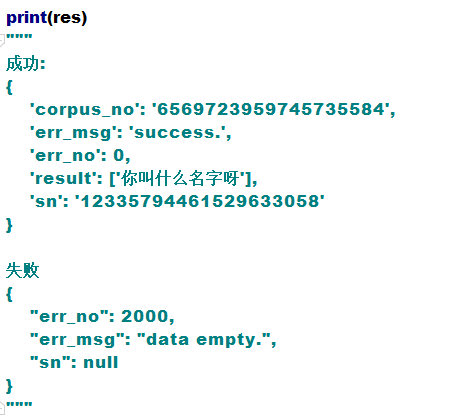
成功的dict中 result 就是我們要的識別文字
失敗的dict中 err_no 就是我們要的錯誤編碼,錯誤編碼代表什麼呢?

如果err_no不是0的話,就參照一下錯誤碼錶
到此百度AI語音部分的呼叫就結束了,是不是感覺很簡單
剛剛學完練習一下:
1.嘗試從語音識別中拿出result對應的中文
2.嘗試你說一句話,然後讓百度AI學你說話
3.嘗試使用對話的方式,得到你叫什麼名字,你今年幾歲了,這樣簡單問題的答案