
golang簡明指南
開發環境搭建
golang 的開發環境搭建比較簡單,由於是編譯型語言,寫好 golang 原始碼後,只需要執行 go build 就能將原始碼編譯成對應平臺(本文中預設為 linux)上的可執行程式。本文不再贅述如何搭建 golang 開發環境,只說明下需要注意的地方。
從官網下載對應平臺的 golang 安裝包中包括 golang 的編譯器、一些工具程式和標準庫原始碼。早期的 golang 版本中,需要設定 GOROOT 和 GOPATH 兩個環境變數。
從 1.8 版開始,GOPATH 不再需要顯示設定。如果沒有顯示設定,則 GOPATH
$HOME/go 。GOPATH可以設定多個目錄,但推薦只設置一個或直接使用預設值,多個 GOPATH 會造成依賴管理的困難。推薦將 $GOPATH/bin 加到 $PATH 裡,這樣通過 go install 會安裝到 $GOPATH/bin 目錄的可執行程式可以像系統命令一樣直接執行,不用輸入完整路徑。從 1.10 版開始,
GOROOT 也不再需要顯示設定了,只需要將安裝包中的 bin 目錄加到 $PATH 裡,系統會自動推匯出 GOROOT編輯器根據個人喜好選擇,作者主要使用 vim 和 vscode 。這裡介紹了使用 vim 時需要安裝的外掛(安裝過程可能需要翻牆,YCM 安裝比較複雜可以不要,gocode 夠用了)。
hello world
以下是 golang 版本的 hello world:
package main
import (
"fmt"
)
func main() {
fmt.Println("hello world")
}golang 安裝包自帶的 gofmt 能將原始碼格式化成官方推薦的風格,建議將這個工具整合到編輯器裡。
這個簡單的程式用 go build 編譯出來可執行程式用 ldd 檢視發現沒有任何動態庫依賴,size 也比較大(1.8M ,對等的 C 程式版本只有 7.5K)。實際上這裡也體現了 golang 的哲學:直接通過原始碼分發軟體,所有的程式碼編到一整個可執行程式裡,基本沒有動態庫依賴(或者只依賴 C/C++ 執行時庫和基本的系統庫),這也方便了 docker 化(C/C++ 程式設計師應試能體會動態庫依賴有多噁心)。通過 readelf 檢視可執行程式會發現程式碼段和除錯資訊段佔用了比較大的空間,程式碼段大是因為 golang 的執行時也在裡面。除錯資訊段方便 golang 程序 panic 時會列印詳細的程序堆疊及原始碼資訊,這也是為什麼 golang 的可執行程式比較大的原因。
命名規範
golang 的標準庫提供了 golang 程式命名規範很好的參考標準,命名規範應該儘量和標準庫的風格接近,多看下標準庫的程式碼就能體會到 golang 的命名哲學了。
命名在很大程式上也體現了一名程式設計師的修養,用好的命名寫出的程式碼通常是自注釋的,只需要在有複雜的邏輯需要解釋的情況下才額外註釋。
好的命名應該具有以下特徵:
- 一致性:見名知義,比如標準庫中將物件序列化成字串的操作名為
String,在你自己的程式碼裡將自定義型別的物件序列化成字串也應該叫這個名字,並且簽名和標準庫要一致; - 簡明精煉:減少敲鍵盤的次數;
- 精確性:不要使用有歧義的命名。
Tip: 通常變數的作用域越廣,變數的名字應該越長,反之亦然。
golang 中一般使用駝峰命名法,儘量不要使用下劃線(基本只在全大寫的常量命名中使用)。首字母縮略詞應該全部大寫,比如 ServeHTTP , IDProcessor 。
本文中出現的必須、 禁止是指強烈推薦的 golang 風格的規範,但違反這個規範並不會導致程式編譯不過。
常量
全大寫或者駝峰命名都可以,全大寫的情況下可使用下劃線分隔單詞:
const (
SEEK_SET int = 0 // seek relative to the origin of the file
SEEK_CUR int = 1 // seek relative to the current offset
SEEK_END int = 2 // seek relative to the end
)
const (
MaxInt8 = 1<<7 - 1
MinInt8 = -1 << 7
MaxInt16 = 1<<15 - 1
MinInt16 = -1 << 15
MaxInt32 = 1<<31 - 1
MinInt32 = -1 << 31
MaxInt64 = 1<<63 - 1
MinInt64 = -1 << 63
MaxUint8 = 1<<8 - 1
MaxUint16 = 1<<16 - 1
MaxUint32 = 1<<32 - 1
MaxUint64 = 1<<64 - 1
)區域性變數
通過以下程式碼片斷舉例說明區域性變數的命名原則:
func RuneCount(buffer []byte) int {
runeCount := 0
for index := 0; index < len(buffer); {
if buffer[index] < RuneSelf {
index++
} else {
_, size := DecodeRune(buffer[index:])
index += size
}
runeCount++
}
return runeCount
}慣用的變數名應該儘可能短:
- 使用
i而不是index - 使用
r而不是reader - 使用
b而不是buffer
這幾個字母在 golang 中有約定俗成的含義,使用單字母名字是更 golang 的方式(可能在其他語言的規範中是反例),其他可以舉一反三。
變數名中不要有冗餘的資訊,在函式 RuneCount 裡,計數器命名就不需再把 rune 包含進來了,直接用 count 就好了。
在判斷 Map 中是否存在某個鍵值或者介面的轉型操作裡,通常用 ok 來接收判斷結果:v, ok := m[k]。
上文中的示例程式碼按照以上原則重構後應該是這個樣子:
func RuneCount(b []byte) int {
count := 0
for i := 0; i < len(b); {
if b[i] < RuneSelf {
i++
} else {
_, n := DecodeRune(b[i:])
i += n
}
count++
}
return count
}形參
形參的命名原則和區域性變數一致。另外 golang 軟體是以原始碼形式釋出的,形參連同函式簽名通常會作為介面文件的一部分,所以形參的命名規範還有以下特點。
如果形參的型別已經能明確說明形參的含義了,形參的名字就可以儘量簡短:
func AfterFunc(d Duration, f func()) *Timer
func Escape(w io.Writer, s []byte)如果形參型別不能說明形參的含義,形參的命名則應該做到見名知義:
func Unix(sec, nsec int64) Time
func HasPrefix(s, prefix []byte) bool
返回值
跟形參一樣,可匯出函式的返回值也是介面文件的一部分,所以可匯出函式的必須使用命名返回值:
func Copy(dst Writer, src Reader) (written int64, err error)
func ScanBytes(data []byte, atEOF bool) (advance int, token []byte, err error)接收器(Receivers)
習慣上接收器的命名命名一般是 1 到 2 個字母的接收器型別的縮寫:
func (b *Buffer) Read(p []byte) (n int, err error)
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request)
func (r Rectangle) Size() Point
同個型別的不同方法中接收器命名要保持一致,不要在一個方法中叫 r ,在另一個方法中又變成了 rdr 。
包級匯出名
包匯出的變數、常量、函式、型別使用時有包名的修飾。這些匯出名字裡就不再需要包含包名的資訊了,所以標準庫中 bytes 包裡的 Buffer 不需要叫 BytesBuffer 。
介面
只有 1 個方法的介面名通常用方法名加上 er 字尾,不引起迷惑的前提下方法名可以使用縮寫:
type Reader interface {
Read(p []byte) (n int, err error)
}
type Execer interface {
Exec(query string, args []Value) (Result, error)
}方法名本身是複合詞的情況下,可以酌情調整以符合英文文法:
type ByteReader interface {
ReadByte() (c byte, err error)
}如果介面有多個方法,則需要選擇一個最能精確概括描述介面目的的名詞命名(有點難度),但是禁止用多個方法中的某個方法加上 er 字尾來命名,否則別人會誤解此介面只有一個方法。可以參考標準庫這幾個介面所包含的方法及介面的命名:net.Conn, http.ResponseWriter, io.ReadWriter 。
Read, Write, Close, Flush, String 這幾個方法在標準庫裡已經有約定俗成的含義和簽名。自定義的介面方法應該要避免使用這幾個名字,除非方法的行為確實和標準庫這幾個介面方法一致,這時候可以使用這些名字,但必須要確保方法的簽名和標準庫一致。序列化成字串的方法命名成 String 而不是 ToString 。
錯誤
自定義錯誤型別以 Error 作為字尾,採用 XyzError 的格式命名:
type ExitError struct {
...
}錯誤值以 Err 作為字首,採用 ErrXyz 的格式命名:
var ErrFormat = errors.New("image: unknown format")
錯誤描述全部小寫,未尾不需要加結束句點。
Getter/Setter
struct 的首字母大寫的欄位是匯出欄位,可以直接讀寫不需要 Getter/Setter ,首字母小寫的欄位是私有欄位,必要的情況下可以增加讀寫私有欄位的 Getter/Setter 方法。私有欄位首字母變大寫即為 Getter 方法名字,不需要加 Get 字首。私有欄位首字母變大寫加上 Set 字首即為 Setter 方法名字。例如 struct 中名為 obj 的私有欄位,其 Getter/Setter 方法命名分別為 Obj/SetObj 。
包
包名使用純小寫、能精確描述包功能且精煉的名詞(有點難度),不帶下劃線,不引起迷惑的前提下可以用縮寫,比如標準庫的 strconv 。如果包名比較複雜出現了多個單詞,就應該考慮是不是要分層了,參考標準庫的 crypto/md5, net/http/cgi 等包。包名應該要和包所在目錄名一致,比如標準庫的 src/encoding/base64目錄下,原始檔的包名為 base64 。避免以下命名:
- 和標準庫同名
util,common等太過籠統的名字
包路徑
包路徑的最底層路徑名和包名一致:
"compress/gzip" // gzip 路徑下原始檔的的包名也為 gzip
包路徑有良好的層級關係但要避免重複羅嗦:
"code.google.com/p/goauth2/oauth2" // bad, goath2 和 oauth2 重複羅嗦
不是所有平臺的檔案系統都是大小敏感的,包路徑名不要有大寫字母:
"github.com/Masterminds/glide" // bad
在匯入包路徑時,按照標準庫包、第三方庫包、專案內部包的順序匯入,各部分用空行隔開:
import (
"encoding/json"
"strconv"
"time"
"github.com/golang/protobuf/proto"
"github.com/gomodule/redigo/redis"
"dc_agent/attr"
"dc_agent/dc"
)禁止使用相對路徑匯入包:
import (
"./attr" // bad
)專案程式碼佈局
開發 golang 庫時如何組織專案程式碼可以參考 golang 的標準庫。開發應用程式和開發庫在工程實踐上還是有點不同。有一些開源專案把所有的程式碼都放在一個包裡 (main) ,專案比較小時還能接受,專案比較大時就難以閱讀了。golang 的專案程式碼佈局目前業界也沒有一個統一的標準。這篇文章討論了幾種佈局方案缺陷,然後提出了一些建議。這篇文章在此基礎上給出了一個可操作的方案,這也是本文推薦的方案。以下以 xauth專案為例說明。
git.yingzhongtong.com/combase/xauth # 專案根目錄
├── cmd # cmd 目錄存放可執行檔案(binary)程式碼
│ ├── client # binary: client 不同的可執行程式各自建立目錄存放
│ │ └── main.go
│ └── xauth # binary: xauth
| ├── main.go
│ ├── config # 編譯當前可執行程式需要的內部庫組織成不同包各自建立目錄存放
│ │ └── config.go
│ ├── handler
│ │ └── handler.go
│ ├── httpproxy
│ │ └── httpproxy.go
│ └── zrpcproxy
│ └── zrpcproxy.go
├── pkg # pkg 目錄存放庫程式碼
│ ├── model # package: model 不同庫組織成不同包,各自建一個目錄存放
│ │ └── contract.go
│ ├── ratelimiter # package: ratelimiter
│ │ ├── inmemory.go
│ │ ├── inmemory_test.go
│ │ ├── ratelimiter.go
│ │ ├── redis.go
│ │ └── redis_test.go
│ └── version # package: version
│ └── version.go
├── glide.lock # 專案依賴庫檔案
├── glide.yaml
├── Makefile
├── README.md # 專案說明文件
├── Dockerfile # 用來建立 docker 映象
└── xauth.yaml # 專案配置這種佈局特別適合既有可執行程式又有庫的複雜專案。主要規範是在專案根目錄下建立 cmd 和 pkg 目錄。cmd 目錄下存放編譯可執行檔案的程式碼。通常一個複雜專案可能會有多個可執行程式,每個可執行程式的程式碼在 cmd 目錄各建立目錄存放。比如 git.yingzhongtong.com/combase/xauth/cmd/xauth 下是編譯可執行檔案 xauth 的原始碼。編譯 xauth 需要使用的內部庫直接在 git.yingzhongtong.com/combase/xauth/cmd/xauth 建立目錄存放。多個可執行程式都需要用到的公共庫應該放到專案根目錄下的 pkg 目錄裡。根目錄的 pkg 目錄下每個目錄都是一個單獨的公共庫。
建議專案根目錄下放一個 Makefile 檔案,方便一鍵編譯出所有可執行程式。
總之,這種佈局的主要思想是按功能模組劃分庫,區分私有庫和公共庫,分別放在不同層級別的目錄裡。使用這種佈局編寫程式碼時,通常可執行程式對應的 main 包一般只有一個 main.go 檔案,而且這個檔案通常程式碼很少,基本就是把需要用到的庫拼到一起。 github 的這個專案提供了這種佈局的模板,可以 clone 下來直接使用(有些檔案需要適當調整下)。
github 上很多優秀的開源專案也是採用的這種佈局,熟悉這種佈局也能幫助你更好的閱讀這些開源專案。
以上介紹的專案程式碼佈局是開發大型專案時強烈建議的方案。如果是小型專案程式碼量很少,直接放在一個目錄裡也是可以接受的。
依賴管理
golang 早期版本中,依賴管理比較簡單,依賴的第三方庫通過 go get 下載到 GOPATH 中,編譯時會根據 import 的路徑去 GOPATH 和 GOROOT 中查詢依賴的庫。這種方式雖然簡單,但是也有很多缺陷:
- 對依賴的第三方庫沒有版本管理,每次 go get 時都是下載最新的版本,最新的版本可能存在 bug;
- 基於域名的第三方庫路徑可能失效;
- 多個專案依賴共同的第三方庫時,一個專案更新依賴庫會影響其他專案。
golang 從 1.6 版本開始引入了 vendor 用來管理第三方庫。vendor 是專案根目錄下的一個特殊目錄,go doc 會忽略這個目錄。編譯時會優先從 vendor 目錄中查詢依賴的第三方庫,找不到時再去 GOPATH 和 GOROOT 中查詢。vendor 機制解決上述的第 2 個和第 3 個缺陷,因此強烈建議工程實踐中將專案的第三方庫(所有本專案之外的庫,包括開源庫及公司級的公共庫)全部放到 vendor 中管理。使用這種方式, GOPATH 存在的意義基本很小了,這也是上文中提到 GOPATH 只需要設定 1 個目錄或者乾脆使用預設值的原因。vendor 機制支援巢狀使用,即 vendor 中的第三方庫中也可以有 vendor 目錄,但這樣做會導致更復雜的依賴鏈甚至迴圈依賴,而且目前也沒有完美的解決方案。因此只有在開發可執行程式專案時才需要使用 vendor 。開發庫時禁止使用 vendor 。vendor 機制並沒有解決上述的依賴庫版本管理問題,並且目前官方也沒有提供配套的工具。可以使用開源的第三方工具解決這個問題,推薦 glide 或 godep 。使用教程參考官方文件,這裡就不贅述了。
使用 vendor 時要注意,專案中的 vendor 目錄不要提交到程式碼倉庫中,但是第三方工具生成的依賴庫列表檔案必須提交,比如 glide 生成的 glide.lock 和 glide.yaml 。
可執行程式版本管理
有時候生產環境跑的可執行程式可能有問題需要找到對應的原始碼進行定位。如果釋出系統也沒有把原始碼資訊和可執行程式關聯的話,可能根本找不到可執行程式是哪個版本的原始碼編譯出來的。因此建議在可執行程式中嵌入版本和編譯資訊,程式啟動時可以直接作為啟動資訊列印。
版本號建議採用通用的 3 級點分字串形式: <大版本號>.<小版本號>.<補丁號>,比如 0.0.1 。簡單的 2 級也可以。使用 git 的話可以把 git commit SHA (通過 git rev-parse --short HEAD 獲取)作為 build id 。
package main
var (
version string
commit string
)
func main() {
println("demo server version:", version, "commit:", commit)
// ...
}以上示例程式碼中,version 和 commit 變數可以在原始碼中硬編碼設定。更優雅的方式是在編譯指令碼(Makefile)裡通過環境變數設定:
VERSION = "0.0.1"
COMMIT = $(shell git rev-parse --short HEAD)
all :
go build -ldflags "-X main.version=$(VERSION) -X main.commit=$(COMMIT)"效能剖析(profiling)
程式的效能通常和使用的正規化、演算法、語言特性有關。在效能敏感的場景下,需要使用效能剖析工具分析程序的瓶頸所在,進而針對性的優化。golang 自帶了效能剖析工具 pprof ,可以方便的剖析 golang 程式的時間/空間執行效能,以下是從某專案中部分程式碼改編後的示例程式碼,用來說明 pprof 的使用。直觀上似乎函式 bar 裡有更多的計算,呼叫函式 bar 應該比呼叫函式 foo 佔用更多的 CPU 時間,實際情況卻並非如此。
// test.go
package main
import (
"net/http"
_ "net/http/pprof"
)
func foo() []byte {
var buf [1000]byte
return buf[:10]
}
var c int
func bar(b []byte) {
c++
for i := 0; i < len(b); i++ {
b[i] = byte(c*i*i*i + 4*c*i*i + 8*c*i + 12*c)
}
}
func main() {
go http.ListenAndServe(":8200", nil)
for {
b := foo()
bar(b)
}
}後臺程式一般是 HTTP 常駐服務(如果不是 HTTP 服務的話也可以直接在程式碼裡啟動一個),import 列表里加上 _ "net/http/pprof" 後,程式啟動後 golang 執行時就會定時對程序執行狀態取樣,取樣到的資料可能通過 HTTP 介面獲取。還有一種方式是使用 "runtime/pprof" 包,在需要剖析的程式程式碼裡插入啟動取樣程式碼將,取樣資料寫到本地檔案用來分析,具體使用方式參考這裡。原理和第一種方式一樣,只是取樣資料讀取方式不一樣。
啟用執行時取樣後,以下命令通過 HTTP 介面獲取一段時間內(5 秒)的取樣資料進行分析,然後進入命令列互動模式:
# go tool pprof http://localhost:8200/debug/pprof/profile?seconds=5
(pprof) top
Showing nodes accounting for 4990ms, 100% of 4990ms total
flat flat% sum% cum cum%
3290ms 65.93% 65.93% 3290ms 65.93% runtime.duffzero
1540ms 30.86% 96.79% 1540ms 30.86% main.bar
110ms 2.20% 99.00% 3400ms 68.14% main.foo (inline)
50ms 1.00% 100% 4990ms 100% main.main
0 0% 100% 4990ms 100% runtime.main使用 top 命令會列印前 10 個最耗時的呼叫(top20 列印前20個,依此類推),從輸出的資訊可以看出大部分 CPU 耗時在 runtime.duffzero 呼叫上。這種命令列方式的輸出不是很直觀,看不出這個呼叫的來源是哪裡。pprof 也支援視覺化輸出,不過需要安裝 graphivz 繪圖工具,centos 下可以通過以下命令安裝:
# sudo yum install graphviz
通過 HTTP 介面取樣 5 秒鐘的 CPU 效能資料生成 PNG 格式(通過 -png 選項開啟)的效能剖析圖並儲存到檔案 cpupprof.png 裡:
# go tool pprof -png http://localhost:8200/debug/pprof/profile?seconds=5 > cpupprof.png
生成的效能剖析圖如下: 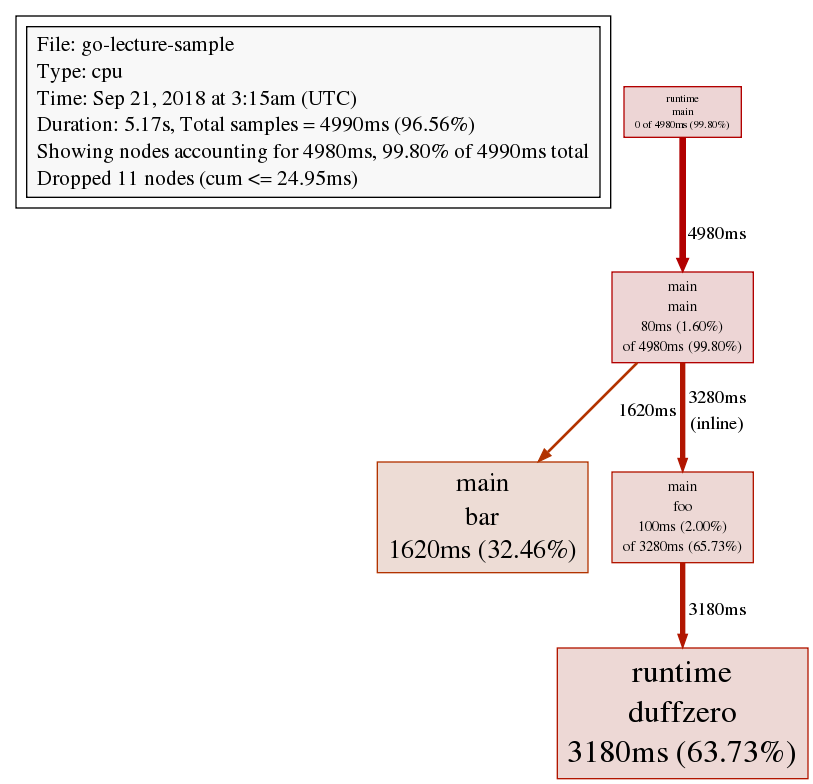
從上圖可以看出呼叫函式 foo 佔用的 CPU 時間要遠大於呼叫函式 bar 的(耗時佔比越大,表示呼叫的箭頭線段也越粗),並且在函式 foo 的耗時主要又耗在呼叫 runtime 的函式 duffzero 上。雖然這是 golang 的內建函式,但看名字基本上已經能猜到效能瓶頸出在哪裡了,這樣就可以進行有針對性的優化。這裡不解釋為什麼呼叫函式 foo 佔用的 CPU 時間會遠大於呼叫函式 bar的,留給讀者思考。
以上這個示例也說明了優化 CPU 效能關鍵是要找到影響整個系統的瓶頸,對於一個只佔系統總耗時 1% 的函式,就算優化 10 倍意義也沒什麼意義。
大多數情況下 golang 後臺應用效能剖析只需要優化 CPU 佔用耗時就可以了。 golang 是自帶垃圾回收(GC)的語言,由於 GC 的複雜性,和程式設計師自己管理記憶體的 C 語言相比,這類語言一般佔用記憶體都比較大。自帶 GC 語言很少會有記憶體洩露問題,不過也有一種特殊場景的記憶體洩漏:比如往一個全域性的切片裡不斷 append 資料又不自行清理,這種一般是程式有邏輯錯誤引起的。pprof 也可以在執行時對物件佔用記憶體進行分析:
# go tool pprof -png http://localhost:8200/debug/pprof/heap > memused.png
以上命令輸出的是物件佔用空間的檢視,預設只有 512KB 以上的記憶體分配才會寫到記憶體分析檔案裡,因此建議在程式開始時加上以下程式碼讓每個記憶體分配都寫到到記憶體分析檔案:
func main() {
runtime.MemProfileRate = 1 // 修改預設值 512KB 為 1B
// ...
}使用 -inuse_objects 選項可以把取樣物件設成物件數目。記憶體取樣資料是物件佔用記憶體狀況的實時快照,不需要像取樣 CPU 效能資料那樣要讓程序跑一段時間。
這篇文章介紹了更多 golang 記憶體洩露的場景,有興趣可以閱讀下。
測試
golang 語言自帶了測試工具和相關庫,可以很方便的對 golang 程式進行測試。
推薦表驅動測試的方式進行單元測試,golang 標準庫中也有很多例子。以下是一個表驅動測試的示例:
func TestAdd(t *testing.T) {
cases := []struct{ A, B, Expected int }{
// 測試用例表
{1, 1, 2},
{1, -1, 0},
{1, 0, 1},
{0, 0, 0},
}
for _, tc := range cases {
actual := tc.A + tc.B
if actual != expected {
t.Errorf(
"%d + %d = %d, expected %d",
tc.A, tc.B, actual, tc.Expected)
}
}
}使用表驅動測試可以很方便的增加測試用例測試各種邊界條件。這個工具可以很方便的生成表驅動測試的樁程式碼。
單元測試一般只需要對包中的匯出函式進行測試,非匯出函式作為內部實現,除非有比較複雜邏輯,一般不用測試。
這個視訊(PPT)更詳細介紹了 golang 測試的最佳實踐,值得一看。
總結
本文不是 golang 語法和工具使用的教程,這些內容在網上可以方便找到。本文假設讀者已經對 golang 語法有了基本的瞭解,給了一些使用 golang 進行實際專案開發時的一些建議和方法指導。文中的主題主要是基於作者的實踐經驗和一些技術部落格的總結,不免帶有一些個人偏見。另外 golang 也是一門不斷演進中的語言(從官方版本釋出頻率也可以看出來),文中的內容也非一成不變,保持與時俱進應該是 golang 開發者應有的心態。
參考資料
- https://studygolang.com/articles/1785
- https://golang.org/doc/effective_go.html
- https://talks.golang.org/2014/names.slide
- http://peter.bourgon.org/go-best-practices-2016/
- https://medium.com/@benbjohnson/standard-package-layout-7cdbc8391fc1
- https://golang.org/pkg/runtime/pprof/
- https://blog.golang.org/profiling-go-programs