
pandas.DataFrame.merge
pandas.DataFrame.merge¶
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)[source]
Merge DataFrame objects by performing a database-style join operation by columns or indexes.
If joining columns on columns, the DataFrame indexes will be ignored. Otherwise if joining indexes on indexes or indexes on a column or columns, the index will be passed on.
| Parameters: | right : DataFrame how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
on : label or list
left_on : label or list, or array-like
right_on : label or list, or array-like
left_index : boolean, default False
right_index : boolean, default False
sort : boolean, default False
suffixes : 2-length sequence (tuple, list, …)
copy : boolean, default True
indicator : boolean or string, default False
validate : string, default None
|
|---|---|
| Returns: | merged : DataFrame
|
See also
merge_ordered, merge_asof, DataFrame.join
Notes
Support for specifying index levels as the on, left_on, and right_on parameters was added in version 0.23.0
Examples
>>> A >>> B
lkey value rkey value
0 foo 1 0 foo 5
1 bar 2 1 bar 6
2 baz 3 2 qux 7
3 foo 4 3 bar 8
>>> A.merge(B, left_on='lkey', right_on='rkey', how='outer') lkey value_x rkey value_y 0 foo 1 foo 5 1 foo 4 foo 5 2 bar 2 bar 6 3 bar 2 bar 8 4 baz 3 NaN NaN 5 NaN NaN qux 7
https://www.cnblogs.com/stream886/p/6022049.html
使用Pandas進行資料匹配
本文轉載自:藍鯨的網站分析筆記
原文連結:使用Pandas進行資料匹配
目錄
Pandas中的merge函式類似於Excel中的Vlookup,可以實現對兩個資料表進行匹配和拼接的功能。與Excel不同之處在於merge函式有4種匹配拼接模式,分別為inner,left,right和outer模式。 其中inner為預設的匹配模式。本篇文章我們將介紹merge函式的使用方法和4種拼接模式的區別。

下面是我們準備進行拼接的兩個資料表,左邊是貸款狀態表loan_stats,右邊為使用者等級表member_grade。我們將分別用merge函式的4種匹配模式對這兩個表進行拼接。

準備工作
開始使用merge函式進行資料拼接之前先匯入所需的功能庫,然後將分別讀取兩個資料表,並命名為loanstats表和member_grade表。
| 1 2 3 4 |
|
函式功能介紹
merge函式的使用方法很簡單,以下是官方的函式功能介紹和使用說明。merge函式中第一個出現的資料表是拼接後的left部分,第二個出現的資料表是拼接後的right部分。第三個是資料匹配模 式,預設是inner模式。第四個引數on表示資料匹配所依據的欄位名稱,如果這個欄位名稱同時出現在兩個資料表中,那麼可以省略on引數的設定,merge預設會按照兩個資料表中共有的欄位名稱進行匹配和拼接。如果兩個資料表中的匹配欄位名稱不一致,則需要分別在left_on和right_on引數中指明兩個表匹配欄位的名稱。如果兩個資料表中沒有匹配欄位,需要使用索引列進行匹配和拼接,可以對left_index和right_index引數設定為True。merge還有一些排序和其他的引數,可在需要使用時進行設定。

Inner模式匹配
inner模式是merge的預設匹配模式,我們通過下面的文氏圖來說明inner的匹配方法。Inner模式提供在loanstats和member_grade表中共有欄位的匹配結果。也就是對兩個的表交集部分進行匹配和拼接。單獨只出現在一個表中的欄位值不會參與匹配和拼接。

以下是使用merge函式進行拼接的程式碼,因為inner是預設的拼接模式,因此也可以省略how=’inner’部分。其中第一個出現的loanstats出現在拼接後的左側,member_grade出現在拼接後的右側。拼接後的資料表中只包含兩個表的交集,因此不存在未匹配到的NaN情況。
| 1 |
|

left模式匹配

left模式是左匹配,以左邊的資料表loanstats為基礎匹配右邊的資料表member_grade中的內容。匹配不到的內容以NaN值顯示。在Excel中就好像將Vlookup公式寫在了左邊的表中。下面的文氏圖說明了left模式的匹配方法。Left模式匹配的結果顯示了所有左邊資料表的內容,以及和右邊資料表共有的內容。

以下為使用left模式匹配並拼接後的結果,loanstats在merge函式中第一個出現,因此為左表,member_grade第二個出現,為右表。匹配模式為left模式。從結果中可以看出left匹配模式保留了一張完整的loanstats表,以此為基礎對member_grade表中的內容進行匹配。loanstats表中有兩個member_id值在member_grade中無法找到,因此grades欄位顯示為NaN值。
| 1 |
|

right模式匹配

第三種模式是right匹配,right與left模式正好相反,right模式是右匹配,以右邊的資料表member_grade為基礎匹配左邊的資料表loanstats。匹配不到的內容以NaN值顯示。下面通過文氏圖說明right模式的匹配方法。Right模式匹配的結果顯示了所有右邊資料表的內容,以及和左邊資料表共有的內容。

以下為使用right模式匹配拼接的結果,從結果表中可以看出right匹配模式保留了完整的member_grade表,以此為基礎對loanstats表進行匹配,在member_grade資料表中有兩個條目在loanstats資料表中無法找到,因此顯示為了NaN值。
| 1 |
|

outer模式匹配
最後一種模式是outer匹配,outer模式是兩個表的彙總,將loanstats和member_grade兩個要匹配的兩個表彙總在一起,生成一張彙總的唯一值資料表以及匹配結果。

下面是使用outer模式匹配拼接的結果,其中member_id列包含了loanstats和member_grade中的唯一值,grade列顯示了對member_grade表匹配的結果,其他列則顯示了對loanstats表匹配的結果 ,無法匹配的內容以NaN值顯示。
| 1 |
|

NaN值匹配問題

在進行資料匹配和拼接的過程中經常會遇到NaN值。這種情況下merge函式會如何處理呢?merge會將兩個資料表中的NaN值進行交叉匹配拼接,換句話說就是將loanstats表member_id列中的NaN值
分別與member_grade表中member_id列中的每一個NaN值進行匹配,然後再拼接在一張表中。下面是包含NaN值的兩張資料表進行拼接的結果,當我們使用left模式進行匹配時,loanstats作為基礎
表,其中member_id列的NaN值分別與member_grade表中member_id列的每一個NaN值進行匹配。並將匹配結果顯示在了結果表中。
| 1 |
|

df3['objectid'].isnull()產生的是一列布爾陣列

用它 可以過濾非空行:
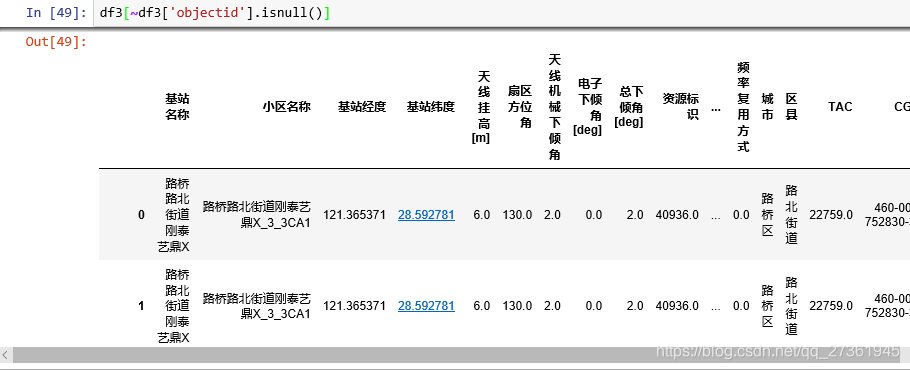
df表的行列的選取方法:
.loc is primarily label based根據行標和列標選取,但是有個特例:
當行標是數字時,ddf.loc[1:2,['eci']]中的1:2好像是通過行號選擇行,實際是通過行標選擇行。
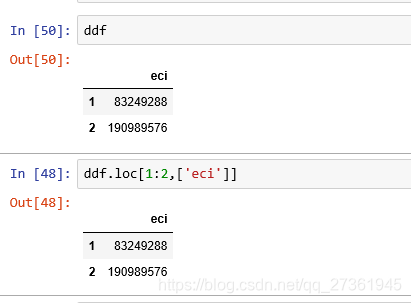
將行標改為3,4 則 .loc[1:2,]就查不到了。

.iloc is primarily integer position based 根據行號和列號選取。
| Object Type | Indexers |
|---|---|
| Series | s.loc[indexer] |
| DataFrame | df.loc[row_indexer,column_indexer] 先行後列 |
| Panel | p.loc[item_indexer,major_indexer,minor_indexer] |