
檢視、觸發器、事務、儲存過程、函式,流程控制
檢視
檢視是一個虛擬表(非真實存在),其本質是【根據SQL語句獲取動態的資料集,併為其命名】,使用者使用時只需使用【名稱】即可獲取結果集,可以將該結果集當做表來使用。
使用檢視我們可以把查詢過程中的臨時表摘出來,用檢視去實現,這樣以後再想操作該臨時表的資料時就無需重寫複雜的sql了,直接去檢視中查詢即可,但檢視有明顯地效率問題,並且檢視是存放在資料庫中的,如果我們程式中使用的sql過分依賴資料庫中的檢視,即強耦合,那就意味著擴充套件sql極為不便,因此並不推薦使用
準備工作
#兩張有關係的表 mysql> select * from course; +-----+--------+------------+ | cid | cname | teacher_id | +-----+--------+------------+ | 1 | 生物 | 1 | | 2 | 物理 | 2 | | 3 | 體育 | 3 | | 4 | 美術 | 2 | +-----+--------+------------+ 4 rows in set (0.00 sec) mysql> select * from teacher; +-----+-----------------+ | tid | tname | +-----+-----------------+ | 1 | 張磊老師 | | 2 | 李平老師 | | 3 | 劉海燕老師 | | 4 | 朱雲海老師 | | 5 | 李傑老師 | +-----+-----------------+ 5 rows in set (0.00 sec) #查詢李平老師教授的課程名 mysql> select cname from course where teacher_id = (select tid from teacher where tname='李平老師'); +--------+ | cname | +--------+ | 物理 | | 美術 | +--------+ 2 rows in set (0.00 sec) #子查詢出臨時表,作為teacher_id等判斷依據 select tid from teacher where tname='李平老師'
建立檢視
#語法:CREATE VIEW 檢視名稱 AS SQL語句 create view teacher_view as select tid from teacher where tname='李平老師'; #於是查詢李平老師教授的課程名的sql可以改寫為 mysql> select cname from course where teacher_id = (select tid from teacher_view); +--------+ | cname | +--------+ | 物理 | | 美術 | +--------+ 2 rows in set (0.00 sec) #!!!注意注意注意: #1. 使用檢視以後就無需每次都重寫子查詢的sql,但是這麼效率並不高,還不如我們寫子查詢的效率高 #2. 而且有一個致命的問題:檢視是存放到資料庫裡的,如果我們程式中的sql過分依賴於資料庫中存放的檢視,那麼意味著,一旦sql需要修改且涉及到檢視的部分,則必須去資料庫中進行修改,而通常在公司中資料庫有專門的DBA負責,你要想完成修改,必須付出大量的溝通成本DBA可能才會幫你完成修改,極其地不方便
使用檢視
#修改檢視,原始表也跟著改 mysql> select * from course; +-----+--------+------------+ | cid | cname | teacher_id | +-----+--------+------------+ | 1 | 生物 | 1 | | 2 | 物理 | 2 | | 3 | 體育 | 3 | | 4 | 美術 | 2 | +-----+--------+------------+ 4 rows in set (0.00 sec) mysql> create view course_view as select * from course; #建立表course的檢視 Query OK, 0 rows affected (0.52 sec) mysql> select * from course_view; +-----+--------+------------+ | cid | cname | teacher_id | +-----+--------+------------+ | 1 | 生物 | 1 | | 2 | 物理 | 2 | | 3 | 體育 | 3 | | 4 | 美術 | 2 | +-----+--------+------------+ 4 rows in set (0.00 sec) mysql> update course_view set cname='xxx'; #更新檢視中的資料 Query OK, 4 rows affected (0.04 sec) Rows matched: 4 Changed: 4 Warnings: 0 mysql> insert into course_view values(5,'yyy',2); #往檢視中插入資料 Query OK, 1 row affected (0.03 sec) mysql> select * from course; #發現原始表的記錄也跟著修改了 +-----+-------+------------+ | cid | cname | teacher_id | +-----+-------+------------+ | 1 | xxx | 1 | | 2 | xxx | 2 | | 3 | xxx | 3 | | 4 | xxx | 2 | | 5 | yyy | 2 | +-----+-------+------------+ 5 rows in set (0.00 sec)
我們不應該修改檢視中的記錄,而且在涉及多個表的情況下是根本無法修改檢視中的記錄的
修改檢視
語法:ALTER VIEW 檢視名稱 AS SQL語句 mysql> alter view teacher_view as select * from course where cid>3; Query OK, 0 rows affected (0.04 sec) mysql> select * from teacher_view; +-----+-------+------------+ | cid | cname | teacher_id | +-----+-------+------------+ | 4 | xxx | 2 | | 5 | yyy | 2 | +-----+-------+------------+ 2 rows in set (0.00 sec)
刪除檢視
語法:DROP VIEW 檢視名稱 DROP VIEW teacher_view
觸發器
使用觸發器可以定製使用者對錶進行【增、刪、改】操作時前後的行為,注意:沒有查詢
建立觸發器


# 插入前 CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW BEGIN ... END # 插入後 CREATE TRIGGER tri_after_insert_tb1 AFTER INSERT ON tb1 FOR EACH ROW BEGIN ... END # 刪除前 CREATE TRIGGER tri_before_delete_tb1 BEFORE DELETE ON tb1 FOR EACH ROW BEGIN ... END # 刪除後 CREATE TRIGGER tri_after_delete_tb1 AFTER DELETE ON tb1 FOR EACH ROW BEGIN ... END # 更新前 CREATE TRIGGER tri_before_update_tb1 BEFORE UPDATE ON tb1 FOR EACH ROW BEGIN ... END # 更新後 CREATE TRIGGER tri_after_update_tb1 AFTER UPDATE ON tb1 FOR EACH ROW BEGIN ... END觸發器的型別
#準備表 CREATE TABLE cmd ( id INT PRIMARY KEY auto_increment, USER CHAR (32), priv CHAR (10), cmd CHAR (64), sub_time datetime, #提交時間 success enum ('yes', 'no') #0代表執行失敗 ); CREATE TABLE errlog ( id INT PRIMARY KEY auto_increment, err_cmd CHAR (64), err_time datetime ); #建立觸發器 delimiter // CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW BEGIN IF NEW.success = 'no' THEN #等值判斷只有一個等號 INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必須加分號 END IF ; #必須加分號 END// delimiter ; #往表cmd中插入記錄,觸發觸發器,根據IF的條件決定是否插入錯誤日誌 INSERT INTO cmd ( USER, priv, cmd, sub_time, success ) VALUES ('egon','0755','ls -l /etc',NOW(),'yes'), ('egon','0755','cat /etc/passwd',NOW(),'no'), ('egon','0755','useradd xxx',NOW(),'no'), ('egon','0755','ps aux',NOW(),'yes'); #查詢錯誤日誌,發現有兩條 mysql> select * from errlog; +----+-----------------+---------------------+ | id | err_cmd | err_time | +----+-----------------+---------------------+ | 1 | cat /etc/passwd | 2017-09-14 22:18:48 | | 2 | useradd xxx | 2017-09-14 22:18:48 | +----+-----------------+---------------------+ 2 rows in set (0.00 sec)插入後觸發觸發器
特別的:NEW表示即將插入的資料行,OLD表示即將刪除的資料行。
使用觸發器
觸發器無法由使用者直接呼叫,而知由於對錶的【增/刪/改】操作被動引發的。
刪除觸發器
drop trigger tri_after_insert_cmd;
事務
事務簡介
一般而言,使用者的每次請求都對應一個業務邏輯方法,並且每個業務邏輯方法往往具有邏輯上的原子性。此外,一個業務邏輯方法往往包括一系列資料庫原子訪問操作,並且這些資料庫原子訪問操作應該繫結成一個整體,即要麼全部執行,要麼全部不執行,通過這種方式我們可以保證資料庫的完整性。也就是說,事務是最小的邏輯執行單元,是資料庫維護資料一致性的基本單位。
總的來說,事務是一個不可分割操作序列,也是資料庫併發控制的基本單位,其執行的結果必須使資料庫從一種一致性狀態變到另一種一致性狀態。事務具有四個重要特徵,即原子性(Atomicity)、一致性(Consistency)、隔離性 (Isolation)和永續性 (Durability)。
原子性(Atomicity) 原子性是指事務包含的所有操作要麼全部成功,要麼全部失敗回滾。 因此,事務的操作如果成功就必須要完全應用到資料庫,如果操作失敗則不會對資料庫有任何影響,也就是說,事務是應用中不可再分的最小邏輯執行體。 一致性(Consistency) 一致性是指事務執行的結果必須使資料庫從一種一致性狀態變到另一種一致性狀態,也就是說,一個事務執行之前和執行之後資料庫都必須處於一致性狀態。拿轉賬來說,假設使用者A和使用者B兩者的錢加起來一共是5000,那麼不管A和B之間如何轉賬,轉幾次賬,事務結束後兩個使用者的錢相加起來應該還得是5000,這就是事務的一致性。 隔離性 (Isolation) — 與事務併發直接相關 隔離性是指併發執行的事務之間不能相互影響。也就是說,對於任意兩個併發的事務 T1 和 T2,在事務 T1 看來,T2 要麼在 T1 開始之前就已經結束,要麼在 T1 結束之後才開始,這樣每個事務都感覺不到有其他事務在併發地執行。關於事務的隔離性下文會重點探討。 永續性 (Durability) 永續性是指一個事務一旦被提交了,那麼對資料庫中的資料的改變就是永久性的,即便是在資料庫系統遇到故障的情況下也不會丟失提交事務的操作。換句換說,事務一旦提交,對資料庫所做的任何改變都要記錄到永久的儲存器中(通常就是儲存到物理資料庫)。
create table user( id int primary key auto_increment, name char(32), balance int ); insert into user(name,balance) values ('wsb',1000), ('egon',1000), ('ysb',1000); #原子操作 start transaction; update user set balance=900 where name='wsb'; #買支付100元 update user set balance=1010 where name='egon'; #中介拿走10元 update user set balance=1090 where name='ysb'; #賣家拿到90元 commit; #出現異常,回滾到初始狀態 start transaction; update user set balance=900 where name='wsb'; #買支付100元 update user set balance=1010 where name='egon'; #中介拿走10元 uppdate user set balance=1090 where name='ysb'; #賣家拿到90元,出現異常沒有拿到 rollback; commit; mysql> select * from user; +----+------+---------+ | id | name | balance | +----+------+---------+ | 1 | wsb | 1000 | | 2 | egon | 1000 | | 3 | ysb | 1000 | +----+------+---------+ 3 rows in set (0.00 sec)事務例項
事務隔離性的內涵
以上介紹完了事務的基本概念及其四大特性(簡稱ACID),現在重點來說明下事務的隔離性。我們知道,當多個執行緒都開啟事務操作資料庫中的資料時,資料庫系統要能進行隔離操作以保證各個執行緒獲取資料的準確性。也就是說,事務的隔離性主要用於解決事務的併發安全問題,那麼事務的隔離性解決了哪些具體問題呢?
事務併發帶來的問題
丟失更新問題 當兩個或多個事務選擇同一行,然後基於最初選定的值更新該行時,由於每個事務都不知道其他事務的存在,就會發生丟失更新問題——最後的更新覆蓋了由其他事務所做的更新。 髒讀 髒讀是指在一個事務處理過程中讀取了另一個事務未提交的資料。比如,當一個事務正在多次修改某個資料,而當這個事務對資料的修改還未提交時,這時一個併發的事務來訪問該資料,就會造成資料的髒讀。看下面的例子: 公司發工資了,領導把5000元打到singo的賬號上,但是該事務並未提交,而singo正好去檢視賬戶,發現工資已經到賬,是5000元整,非常高興。可是不幸的是,領導發現發給singo的工資金額不對,是2000元,於是迅速回滾了事務,修改金額後,將事務提交,最後singo實際的工資只有2000元,singo空歡喜一場。 出現的上述情況就是我們所說的髒讀,即對於兩個併發的事務(事務A:領導給singo發工資、事務B:singo查詢工資賬戶),事務B讀取了事務A尚未提交的資料。特別地,當隔離級別設定為 Read Committed 時,就可以避免髒讀,但是仍可能會造成不可重複讀。特別地,大多數資料庫的預設級別就是Read committed,比如Sql Server , Oracle。 不可重複讀 不可重複讀是指:對於資料庫中的某個資料,一個事務範圍內多次查詢卻返回了不同的資料值,這是由於在查詢間隔該資料被另一個事務修改並提交了。例如,事務 T1 在讀取某一資料,而事務 T2 立馬修改了這個資料並且提交事務,當事務T1再次讀取該資料就得到了不同的結果,即發生了不可重複讀。不可重複讀和髒讀的區別是,髒讀是某一事務讀取了另一個事務未提交的髒資料,而不可重複讀則是讀取了前一事務提交的資料。看下面的例子: singo拿著工資卡去消費,系統讀取到卡里確實有2000元,而此時她的老婆也正好在網上轉賬,把singo工資卡的2000元轉到另一賬戶,並在singo之前提交了事務,當singo扣款時,系統檢查到singo的工資卡已經沒有錢,扣款失敗,singo十分納悶,明明卡里有錢,為何…… 上述情況就是我們所說的不可重複讀,即兩個併發的事務(事務A:singo消費、事務B:singo的老婆網上轉賬),事務A事先讀取了資料,事務B緊接著更新了資料並提交了事務,而事務A再次讀取該資料時,資料已經發生了改變。當隔離級別設定為Repeatable read時,可以避免不可重複讀。這時,當singo拿著工資卡去消費時,一旦系統開始讀取工資卡資訊(即事務開始),singo的老婆就不可能對該記錄進行修改,也就是singo的老婆不能在此時轉賬。特別地,MySQL的預設隔離級別就是 Repeatable read。 幻讀 幻讀是事務非獨立執行時發生的一種現象,即在一個事務讀的過程中,另外一個事務可能插入了新資料記錄,影響了該事務讀的結果。例如,事務 T1 對一個表中所有的行的某個資料項執行了從“1”修改為“2”的操作,這時事務T2又對這個表中插入了一行資料項,而這個資料項的數值還是為“1”並且提交給資料庫。這時,操作事務 T1 的使用者如果再檢視剛剛修改的資料,會發現還有一行沒有修改,其實這行是從事務T2中新增的,就好像產生幻覺一樣,這就是發生了幻讀。幻讀和不可重複讀都是讀取了另一條已經提交的事務(這點與髒讀不同),所不同的是不可重複讀查詢的都是同一個資料項,而幻讀針對的是資料記錄插入/刪除問題,二者關注的問題點不太相同。看下面的例子: singo的老婆工作在銀行部門,她時常通過銀行內部系統檢視singo的信用卡消費記錄。有一天,她正在查詢到singo當月信用卡的總消費金額為80元,而singo此時正好在外面胡吃海塞後在收銀臺買單,消費1000元,即新增了一條1000元的消費記錄並提交了事務,隨後singo的老婆將singo當月信用卡消費的明細列印到A4紙上,卻發現消費總額為1080元,singo的老婆很詫異,以為出現了幻覺,幻讀就這樣產生了。當隔離級別設定為Serializable(最高的事務隔離級別)時,不僅可以避免髒讀、不可重複讀,還可以避免幻讀。但同時代價也花費最高,效能很低,一般很少使用,因為在該級別下併發事務將序列執行
事務隔離性小結
總的來說,事務的隔離性主要用於解決事務併發安全問題。上面提到的髒讀、不可重複讀和幻讀三個典型問題都是在事務併發的前提下發生的,不同的是三者的問題關注點略有不同。髒讀關注的是事務讀取了另一個事務未提交的資料;不可重複讀關注的是同一事務中對同一個資料項多次讀取的結果互不相同;幻讀更側重於資料記錄的插入/刪除問題,比如同一事務中對符合同一條件的資料記錄的多次查詢的結果互不相同。更進一步地說,不可重複讀關注的是資料的更新帶來的問題,幻讀關注的是資料的增刪帶來的問題
資料庫的事務隔離級別
不同資料庫的事務隔離級別不盡相同。比如我們在上一節提到,MySQL資料庫支援下面的四種隔離級別,並且預設為 Repeatable read 級別;而在Oracle資料庫中,只支援Serializable 級別和 Read committed 這兩種級別,並且預設為 Read committed 級別。MySQL資料庫為我們提供了四種隔離級別,
Serializable (序列化):最高級別,可避免髒讀、不可重複讀、幻讀的發生;
Repeatable read (可重複讀):可避免髒讀、不可重複讀的發生;
Read committed (讀已提交):可避免髒讀的發生;
Read uncommitted (讀未提交):最低級別,任何情況都無法保證。
View Code
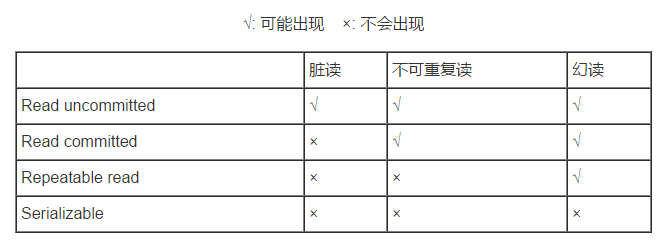
以上四種隔離級別中最高的是 Serializable級別,最低的是 Read uncommitted級別。當然,隔離級別越高,事務併發就越安全,但執行效率也就越低。比如,Serializable 這樣的級別就是以鎖表的方式(類似於Java多執行緒中的鎖)保證併發事務的序列執行,但這時執行效率也降到了最低,所以,選用何種隔離級別實質上是一種併發安全與併發效率的平衡,應該根據實際情況而定。特別地,在MySQL資料庫中,預設的事務隔離級別為 Repeatable read(可重複讀),下面我們看看如何在MySQL資料庫中操作事務的隔離級別。
MySQL預設事務隔離級別檢視
在MySQL資料庫中,我們可以通過以下方式檢視當前事務的隔離級別:
select @@tx_isolation;
MySQL事務隔離級別修改
在MySQL資料庫中,我們可以分別通過以下兩種方式設定事務的隔離級別,分別為:
set [glogal | session] transaction isolation level 隔離級別名稱; 或 set tx_isolation='隔離級別名稱';
使用JDBC對設定資料庫事務的隔離級別
設定資料庫的隔離級別一定要是在開啟事務之前。特別地,使用JDBC對資料庫的事務設定隔離級別時,我們應該在呼叫Connection物件的setAutoCommit(false)方法之前呼叫Connection物件的setTransactionIsolation(level)去設定當前連結的隔離級別如下所示:
至於引數level,可以使用Connection介面的欄位,如以下程式碼所示:
Connection conn=null;
Statement st=null;
ResultSet rs=null;
try{
conn=JdbcUtils.getConnection();
//設定該連結的隔離級別
conn.setTransactionIsolation(Connection.TRANSACTION_SERIALIZABLE);
conn.setAutoCommit(false);//開啟事務
至於引數level,可以使用Connection介面的欄位

特別地,通過這種方式設定事務隔離級別只對當前連結有效。對於使用MySQL命令視窗而言,一個視窗就相當於一個連結,當前視窗設定的隔離級別只對當前視窗中的事務有效;對於JDBC操作資料庫來說,一個Connection物件相當於一個連結,而對於Connection物件設定的隔離級別只對該Connection物件有效,與其他連結Connection物件無關。
資料庫併發控制
也許大家已經聽說過,鎖分兩種,一個叫 悲觀鎖,一種稱之為 樂觀鎖。事實上,無論是悲觀鎖還是樂觀鎖,都是人們定義出來的概念,是一種解決問題的思想。因此,不僅僅在資料庫系統中有樂觀鎖和悲觀鎖的概念,像memcache、hibernate、tair等都有類似的概念。比如,線上程併發處理中, Synchronized內建鎖 就是悲觀鎖的一種,也稱之為 獨佔鎖,加了synchronized關鍵字的程式碼基本上就只能以單執行緒的形式去執行了,它會導致其他需要該資源的執行緒掛起,直到前面的執行緒執行完畢釋放所資源;而 樂觀鎖是一種更高效的機制,它的原理就是每次不加鎖去執行某項操作,如果發生衝突則失敗並重試,直到成功為止,其實本質上不算鎖,所以很多地方也稱之為 自旋。
在解決資料庫的事務併發訪問問題時,雖然將事務串形化可以保證資料在多事務併發處理下不存在資料不一致的問題,但序列執行使得資料庫的處理效能大幅度地下降,常常是我們接受不了的。所以,一般來說,我們常常結合事務隔離級別和其它併發機制來保證事務的併發,以此來兼顧事務併發的效率與安全性。事實上,大多數資料庫的隔離級別都會設定為 Read Committed(只能讀取其他事務已提交的資料),然後由應用程式使用樂觀鎖/悲觀鎖機制來解決其他事務併發問題,比如不可重複讀問題。特別地,樂觀併發控制(樂觀鎖)和悲觀併發控制(悲觀鎖)是併發控制主要採用的技術手段。
特別地,樂觀鎖的理念是:假設不會發生併發衝突,只在提交操作時檢查是否違反資料完整性;而悲觀鎖的理念是假定會發生併發衝突,遮蔽一切可能違反資料完整性的操作。針對於不同的業務場景,應該選用不同的併發控制方式。所以,不要把樂觀併發控制和悲觀併發控制狹義的理解為DBMS中的概念,更不要把他們和資料中提供的鎖機制(行鎖、表鎖、排他鎖、共享鎖)混為一談。需要指出的是,在DBMS中,悲觀鎖正是利用資料庫本身提供的鎖機制來實現的。
樂觀鎖
樂觀鎖,雖然名字中帶“鎖”,但是樂觀鎖並不鎖住任何東西,而是在提交事務時檢查這條記錄是否被其他事務進行了修改:如果沒有,則提交;否則,進行回滾。相對於悲觀鎖,在對資料庫進行處理的時候,樂觀鎖並不會使用資料庫提供的鎖機制。如果併發的可能性並不大,那麼樂觀鎖定策略帶來的效能消耗是非常小的。樂觀鎖採用的實現方式一般是記錄資料版本。 資料版本是為資料增加的一個版本標識。當讀取資料時,將版本標識的值一同讀出,資料每更新一次同時對版本標識進行更新。當我們提交更新的時候,判斷資料庫表對應記錄的當前版本資訊與第一次取出來的版本標識進行比對,如果資料庫表當前版本號與第一次取出來的版本標識值相等,則予以更新,否則認為是過期資料。一般地,實現資料版本有兩種方式,一種是使用版本號,另一種是使用時間戳。
悲觀鎖
悲觀鎖,正如其名,它指的是對資料被外界修改持保守(悲觀)態度,因此,在整個資料處理過程中,將資料處於鎖定狀態。悲觀鎖的實現往往依靠資料庫提供的鎖機制,也只有資料庫層提供的鎖機制才能真正保證資料訪問的排他性,否則即使在本系統中實現了加鎖機制,也無法保證外部系統不會修改資料。悲觀併發控制主要用於資料爭用激烈的環境,以及發生併發衝突時使用鎖保護資料的成本要低於回滾事務的成本的環境中。和樂觀鎖相比,悲觀鎖則是一把真正的鎖了,它通過SQL語句“select for update”鎖住select出的那批資料,這時如果其他事務來更新這批資料時會等待。 悲觀併發控制實際上是“先取鎖再訪問”的保守策略,為資料處理的安全提供了保證。但是在效率方面,處理加鎖的機制會讓資料庫產生額外的開銷,還有增加產生死鎖的機會;另外,在只讀型事務處理中由於不會產生衝突,也沒必要使用鎖,這樣做只能增加系統負載;還有會降低了並行性,一個事務如果鎖定了某行資料,其他事務就必須等待該事務處理完才可以處理那行資料。
悲觀鎖和樂觀鎖小結
悲觀鎖和樂觀鎖都是一種解決併發控制問題的思想。特別地,在資料庫併發控制方面,悲觀鎖與樂觀鎖有以下幾點區別: 思想:在事務併發環境中,樂觀鎖假設不會發生併發衝突,因此只在提交操作時檢查是否違反資料完整性;而悲觀鎖假定會發生併發衝突,會遮蔽一切可能違反資料完整性的操作。 實現:悲觀鎖是利用資料庫本身提供的鎖機制來實現的;而樂觀鎖則是通過記錄資料版本實現的; 應用場景:悲觀鎖主要用於資料爭用激烈的環境或者發生併發衝突時使用鎖保護資料的成本要低於回滾事務的成本的環境中;而樂觀鎖主要應用於併發可能性並不太大、資料競爭不激烈的環境中,這時樂觀鎖帶來的效能消耗是非常小的; 髒讀: 樂觀鎖不能解決髒讀問題,而悲觀鎖則可以。 總的來說,悲觀鎖相對樂觀鎖更安全一些,但是開銷也更大,甚至可能出現數據庫死鎖的情況,建議只在樂觀鎖無法工作時才使用。
儲存過程
介紹
儲存過程包含了一系列可執行的sql語句,儲存過程存放於MySQL中,通過呼叫它的名字可以執行其內部的一堆sql
使用儲存過程的優點:
1. 用於替代程式寫的SQL語句,實現程式與sql解耦 2. 基於網路傳輸,傳別名的資料量小,而直接傳sql資料量大
使用儲存過程的缺點:
程式設計師擴充套件功能不方便
補充:程式與資料庫結合使用的三種方式
方式一:
MySQL:儲存過程
程式:呼叫儲存過程
方式二:
MySQL:
程式:純SQL語句
方式三:
MySQL:
程式:類和物件,即ORM(本質還是純SQL語句)
無引數儲存過程建立
delimiter //
create procedure p1()
BEGIN
select * from blog;
INSERT into blog(name,sub_time) values("xxx",now());
END //
delimiter ;
#在mysql中呼叫
call p1()
#在python中基於pymysql呼叫
cursor.callproc('p1')
print(cursor.fetchall())
有引數儲存過程建立
對於儲存過程,可以接收引數,其引數有三類: in 僅用於傳入引數用 out 僅用於返回值用 inout 既可以傳入又可以當作返回值
delimiter // create procedure p2( in n1 int, in n2 int ) BEGIN select * from blog where id > n1; END // delimiter ; #在mysql中呼叫 call p2(3,2) #在python中基於pymysql呼叫 cursor.callproc('p2',(3,2)) print(cursor.fetchall())in
delimiter // create procedure p3( in n1 int, out res int ) BEGIN select * from blog where id > n1; set res = 1; END // delimiter ; #在mysql中呼叫 set @res=0; #0代表假(執行失敗),1代表真(執行成功) call p3(3,@res); select @res; #在python中基於pymysql呼叫 cursor.callproc('p3',(3,0)) #0相當於set @res=0 print(cursor.fetchall()) #查詢select的查詢結果 cursor.execute('select @_p3_0,@_p3_1;') #@p3_0代表第一個引數,@p3_1代表第二個引數,即返回值 print(cursor.fetchall())out
delimiter // create procedure p4( inout n1 int ) BEGIN select * from blog where id > n1; set n1 = 1; END // delimiter ; #在mysql中呼叫 set @x=3; call p4(@x); select @x; #在python中基於pymysql呼叫 cursor.callproc('p4',(3,)) print(cursor.fetchall()) #查詢select的查詢結果 cursor.execute('select @_p4_0;') print(cursor.fetchall())inout
#介紹 delimiter // create procedure p4( out status int ) BEGIN 1. 宣告如果出現異常則執行{ set status = 1; rollback; } 開始事務 -- 由秦兵賬戶減去100 -- 方少偉賬戶加90 -- 張根賬戶加10 commit; 結束 set status = 2; END // delimiter ; #實現 delimiter // create PROCEDURE p5( OUT p_return_code tinyint ) BEGIN DECLARE exit handler for sqlexception BEGIN -- ERROR set p_return_code = 1; rollback; END; DECLARE exit handler for sqlwarning BEGIN -- WARNING set p_return_code = 2; rollback; END; START TRANSACTION; DELETE from tb1; #執行失敗 insert into blog(name,sub_time) values('yyy',now()); COMMIT; -- SUCCESS set p_return_code = 0; #0代表執行成功 END // delimiter ; #在mysql中呼叫儲存過程 set @res=123; call p5(@res); select @res; #在python中基於pymysql呼叫儲存過程 cursor.callproc('p5',(123,)) print(cursor.fetchall()) #查詢select的查詢結果 cursor.execute('select @_p5_0;') print(cursor.fetchall())事務
delimiter // create procedure p3() begin declare ssid int; -- 自定義變數1 declare ssname varchar(50); -- 自定義變數2 DECLARE done INT DEFAULT FALSE; DECLARE my_cursor CURSOR FOR select sid,sname from student; DECLARE CONTINUE HANDLER FOR NOT FOUND SET done = TRUE; open my_cursor; xxoo: LOOP fetch my_cursor into ssid,ssname; if done then leave xxoo; END IF; insert into teacher(tname) values(ssname); end loop xxoo; close my_cursor; end // delimter ;遊標
delimiter \\ CREATE PROCEDURE p4 ( in nid int ) BEGIN PREPARE prod FROM 'select * from student where sid > ?'; EXECUTE prod USING @nid; DEALLOCATE prepare prod; END\\ delimiter ;動態執行sql,防注入
執行儲存過程
-- 無引數 call proc_name() -- 有引數,全in call proc_name(1,2) -- 有引數,有in,out,inout set @t1=0; set @t2=3; call proc_name(1,2,@t1,@t2)在MySQL中執行儲存過程
#!/usr/bin/env python # -*- coding:utf-8 -*- import pymysql conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passwd='123', db='t1') cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 執行儲存過程 cursor.callproc('p1', args=(1, 22, 3, 4)) # 獲取執行完儲存的引數 cursor.execute("select @_p1_0,@_p1_1,@_p1_2,@_p1_3") result = cursor.fetchall() conn.commit() cursor.close() conn.close() print(result)在python中基於pymysql執行儲存過程
刪除儲存過程
drop procedure proc_name;
函式
MySQL中提供了許多內建函式,例如:
數學函式
ROUND(x,y)
返回引數x的四捨五入的有y位小數的值
RAND()
返回0到1內的隨機值,可以通過提供一個引數(種子)使RAND()隨機數生成器生成一個指定的值。
聚合函式(常用於GROUP BY從句的SELECT查詢中)
AVG(col)返回指定列的平均值
COUNT(col)返回指定列中非NULL值的個數
MIN(col)返回指定列的最小值
MAX(col)返回指定列的最大值
SUM(col)返回指定列的所有值之和
GROUP_CONCAT(col) 返回由屬於一組的列值連線組合而成的結果
字串函式
CHAR_LENGTH(str)
返回值為字串str 的長度,長度的單位為字元。一個多位元組字元算作一個單字元。
CONCAT(str1,str2,...)
字串拼接
如有任何一個引數為NULL ,則返回值為 NULL。
CONCAT_WS(separator,str1,str2,...)
字串拼接(自定義連線符)
CONCAT_WS()不會忽略任何空字串。 (然而會忽略所有的 NULL)。
CONV(N,from_base,to_base)
進位制轉換
例如:
SELECT CONV('a',16,2); 表示將 a 由16進位制轉換為2進位制字串表示
FORMAT(X,D)
將數字X 的格式寫為'#,###,###.##',以四捨五入的方式保留小數點後 D 位, 並將結果以字串的形式返回。若 D 為 0, 則返回結果不帶有小數點,或不含小數部分。
例如:
SELECT FORMAT(12332.1,4); 結果為: '12,332.1000'
INSERT(str,pos,len,newstr)
在str的指定位置插入字串
pos:要替換位置其實位置
len:替換的長度
newstr:新字串
特別的:
如果pos超過原字串長度,則返回原字串
如果len超過原字串長度,則由新字串完全替換
INSTR(str,substr)
返回字串 str 中子字串的第一個出現位置。
LEFT(str,len)
返回字串str 從開始的len位置的子序列字元。
LOWER(str)
變小寫
UPPER(str)
變大寫
REVERSE(str)
返回字串 str ,順序和字元順序相反。
SUBSTRING(str,pos) , SUBSTRING(str FROM pos) SUBSTRING(str,pos,len) , SUBSTRING(str FROM pos FOR len)
不帶有len 引數的格式從字串str返回一個子字串,起始於位置 pos。帶有len引數的格式從字串str返回一個長度同len字元相同的子字串,起始於位置 pos。 使用 FROM的格式為標準 SQL 語法。也可能對pos使用一個負值。假若這樣,則子字串的位置起始於字串結尾的pos 字元,而不是字串的開頭位置。在以下格式的函式中可以對pos 使用一個負值。
mysql> SELECT SUBSTRING('Quadratically',5);
-> 'ratically'
mysql> SELECT SUBSTRING('foobarbar' FROM 4);
-> 'barbar'
mysql> SELECT SUBSTRING('Quadratically',5,6);
-> 'ratica'
mysql> SELECT SUBSTRING('Sakila', -3);
-> 'ila'
mysql> SELECT SUBSTRING('Sakila', -5, 3);
-> 'aki'
mysql> SELECT SUBSTRING('Sakila' FROM -4 FOR 2);
-> 'ki'
日期和時間函式
CURDATE()或CURRENT_DATE() 返回當前的日期
CURTIME()或CURRENT_TIME() 返回當前的時間
DAYOFWEEK(date) 返回date所代表的一星期中的第幾天(1~7)
DAYOFMONTH(date) 返回date是一個月的第幾天(1~31)
DAYOFYEAR(date) 返回date是一年的第幾天(1~366)
DAYNAME(date) 返回date的星期名,如:SELECT DAYNAME(CURRENT_DATE);
FROM_UNIXTIME(ts,fmt) 根據指定的fmt格式,格式化UNIX時間戳ts
HOUR(time) 返回time的小時值(0~23)
MINUTE(time) 返回time的分鐘值(0~59)
MONTH(date) 返回date的月份值(1~12)
MONTHNAME(date) 返回date的月份名,如:SELECT MONTHNAME(CURRENT_DATE);
NOW() 返回當前的日期和時間
QUARTER(date) 返回date在一年中的季度(1~4),如SELECT QUARTER(CURRENT_DATE);
WEEK(date) 返回日期date為一年中第幾周(0~53)
YEAR(date) 返回日期date的年份(1000~9999)
重點:
DATE_FORMAT(date,format) 根據format字串格式化date值
mysql> SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y');
-> 'Sunday October 2009'
mysql> SELECT DATE_FORMAT('2007-10-04 22:23:00', '%H:%i:%s');
-> '22:23:00'
mysql> SELECT DATE_FORMAT('1900-10-04 22:23:00',
-> '%D %y %a %d %m %b %j');
-> '4th 00 Thu 04 10 Oct 277'
mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00',
-> '%H %k %I %r %T %S %w');
-> '22 22 10 10:23:00 PM 22:23:00 00 6'
mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V');
-> '1998 52'
mysql> SELECT DATE_FORMAT('2006-06-00', '%d');
-> '00'
加密函式
MD5()
計算字串str的MD5校驗和
PASSWORD(str)
返回字串str的加密版本,這個加密過程是不可逆轉的,和UNIX密碼加密過程使用不同的演算法。
控制流函式
CASE WHEN[test1] THEN [result1]...ELSE [default] END
如果testN是真,則返回resultN,否則返回default
CASE [test] WHEN[val1] THEN [result]...ELSE [default]END
如果test和valN相等,則返回resultN,否則返回default
IF(test,t,f)
如果test是真,返回t;否則返回f
IFNULL(arg1,arg2)
如果arg1不是空,返回arg1,否則返回arg2
NULLIF(arg1,arg2)
如果arg1=arg2返回NULL;否則返回arg1
#1 基本使用 mysql> SELECT DATE_FORMAT('2009-10-04 22:23:00', '%W %M %Y'); -> 'Sunday October 2009' mysql> SELECT DATE_FORMAT('2007-10-04 22:23:00', '%H:%i:%s'); -> '22:23:00' mysql> SELECT DATE_FORMAT('1900-10-04 22:23:00', -> '%D %y %a %d %m %b %j'); -> '4th 00 Thu 04 10 Oct 277' mysql> SELECT DATE_FORMAT('1997-10-04 22:23:00', -> '%H %k %I %r %T %S %w'); -> '22 22 10 10:23:00 PM 22:23:00 00 6' mysql> SELECT DATE_FORMAT('1999-01-01', '%X %V'); -> '1998 52' mysql> SELECT DATE_FORMAT('2006-06-00', '%d'); -> '00' #2 準備表和記錄 CREATE TABLE blog ( id INT PRIMARY KEY auto_increment, NAME CHAR (32), sub_time datetime ); INSERT INTO blog (NAME, sub_time) VALUES ('第1篇','2015-03-01 11:31:21'), ('第2篇','2015-03-11 16:31:21'), ('第3篇','2016-07-01 10:21:31'), ('第4篇','2016-07-22 09:23:21'), ('第5篇','2016-07-23 10:11:11'), ('第6篇','2016-07-25 11:21:31'), ('第7篇','2017-03-01 15:33:21'), ('第8篇','2017-03-01 17:32:21'), ('第9篇','2017-03-01 18:31:21'); #3. 提取sub_time欄位的值,按照格式後的結果即"年月"來分組 SELECT DATE_FORMAT(sub_time,'%Y-%m'),COUNT(1) FROM blog GROUP BY DATE_FORMAT(sub_time,'%Y-%m'); #結果 +-------------------------------+----------+ | DATE_FORMAT(sub_time,'%Y-%m') | COUNT(1) | +-------------------------------+----------+ | 2015-03 | 2 | | 2016-07 | 4 | | 2017-03 | 3 | +-------------------------------+----------+ 3 rows in set (0.00 sec)需要掌握data_format
自定義函式
!!!注意!!! 函式中不要寫sql語句(否則會報錯),函式僅僅只是一個功能,是一個在sql中被應用的功能 若要想在begin...end...中寫sql,請用儲存過程
delimiter //
create function f1(
i1 int,
i2 int)
returns int
BEGIN
declare num int;
set num = i1 + i2;
return(num);
END //
delimiter ;
delimiter //
create function f5(
i int
)
returns int
begin
declare res int default 0;
if i = 10 then
set res=100;
elseif i = 20 then
set res=200;
elseif i = 30 then
set res=300;
else
set res=400;
end if;
return res;
end //
delimiter ;
刪除函式
drop function func_name;
執行函式
獲取返回值
select UPPER('egon') into @res;
SELECT @res;
在查詢中使用
select f1(11,nid) ,name from tb2;
流程控制
條件語句
delimiter // CREATE PROCEDURE proc_if () BEGIN declare i int default 0; if i = 1 THEN SELECT 1; ELSEIF i = 2 THEN SELECT 2; ELSE SELECT 7; END IF; END // delimiter ;if
迴圈語句
delimiter // CREATE PROCEDURE proc_while () BEGIN DECLARE num INT ; SET num = 0 ; WHILE num < 10 DO SELECT num ; SET num = num + 1 ; END WHILE ; END // delimiter ;while迴圈
delimiter // CREATE PROCEDURE proc_repeat () BEGIN DECLARE i INT ; SET i = 0 ; repeat select i; set i = i + 1; until i >= 5 end repeat; END // delimiter ;repeat迴圈
BEGIN declare i int default 0; loop_label: loop set i=i+1; if i<8 then iterate loop_label; end if; if i>=10 then leave loop_label; end if; select i; end loop loop_label; ENDloop迴圈
小練習
準備表 /* Navicat MySQL Data Transfer Source Server : localhost_3306 Source Server Version : 50720 Source Host : localhost:3306 Source Database : student Target Server Type : MYSQL Target Server Version : 50720 File Encoding : 65001 Date: 2018-01-02 12:05:30 */ SET FOREIGN_KEY_CHECKS=0; -- ---------------------------- -- Table structure for course -- ---------------------------- DROP TABLE IF EXISTS `course`;