[深度學習]Object detection物體檢測之SPPNet(3)
目錄
4.SPP-NET FOR OBJECT DETECTION
論文全稱:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
論文地址:https://arxiv.org/pdf/1406.4729.pdf
論文一作是kaiming He,怎麼到處都是你,真的強的不像話呀。
1.論文的綜述
當下卷積神經網路的弊端是輸入必須是fixed size

所以作者就思考一種解決辦法,他們分析其實傳統卷積網路無非就是卷積部分加上全連線部分,卷積分部提取影象特徵其實並非一定要統一的size,只是後面的全連線需要統一大小的feature,所以作者在卷積層和全連線層之間加入一個Spatial Pyramid Pooling空間金字塔池化,它的作用是使得大小不一致的feature變成固定大小的feature,來匹配全連線層。下面是傳統方法和本論文方法的區別圖:

那麼SPPNet有什麼特性使它特別適合CNN呢?
- SPP能夠生成固定長度的輸出,而不考慮輸入大小,而在以前的深度網路中使用的滑動視窗池化卻不能;
- SPP使用multi-level spatial bins多級空間箱,而e sliding window pooling滑動視窗池化只使用單個視窗大小。多級池已被證明是魯棒的物件變形。
- 由於輸入尺度的靈活性,SPP可以在可變尺度下提取特徵。(這裡第三點有點疑惑,論文裡面這說的不明白)
無論是在testing還是training,可變輸入都是允許的,這就可以增加尺度不變性,減少過擬合。
論文還開發了一種簡單的多尺度訓練方法
其實SPPNet原本是一個更關注於classification的問題,同時論文裡面也提到它適用於很多其他的問題例如一個就是object detection。作者分析了RCNN的弊端是費時,因為不同的region會重疊,所以會重複計算feature。而SPPNet的優勢是隻需要進行一次卷積的過程,而不在乎有多少個region。這個方法比R-CNN快100倍都不止。
SPPNet繼承了深度CNN feature map的強大功能,也繼承了SPP在任意視窗大小上的靈活性,從而獲得了出色的準確性和效率。這使得它能夠滿足現實生活中應用的實時性。
2.Spatial Pyramid Pooling結構

如上圖所示,Spatial Pyramid Pooling替代了最後一個池化層(在最後一個卷積層之後的池化),通過local spatial bins這種結構來維護空間資訊,這些spatial bins的大小與影象大小成正比,並且無論影象大小如何,spatial bins的數量都是固定的。這與之前的深層網路的滑動視窗池化形成了對比,後者的滑動視窗數量取決於輸入大小。Spatial Pyramid Pooling的輸出是k*m dimension向量,其spatial bins的數量記為M (k是最後一個卷積層中的filter層數)。fixed-dimensional固定維向量是完全連通層的輸入的大小。
3.Training the Network訓練網路的細節
關於如果做到根據影象的比例來調整spatial bins的大小,這裡論文提供了一個例子:

為了最後得到3*3,2*2,1*1的3-level pyramid pooling,sizeX的大小和stride的大小會根據最後一層卷積輸入的大小來調整,這裡三個spatial bins的sizeX分別為5,7,13,stride分別為4,6,13。我們可以算一下其中第一個,(13-5)/4+1確實是等於3。
這裡訓練網路一開始只是Single-size training(240*240),後來變成了Multi-size training(240*240和180*180),輸入的資料只是解析度大小不同,並不是從240*240的影象隨機crop出180*180。但是為了實現Multi-size training,還是需要增添一個fixed-size-input (180×180) network,使得180*180輸入可以被接受。
具體怎麼訓練呢?其實是先訓練240*240網路的一個batch,再轉換到180*180網路訓練一個batch,這樣迴圈得到的結果跟single size training收斂的結果一致。
可是在測試集的時候是怎麼做到接受不同的大小的輸入的呢?其實這裡有一個誤區,我們以前學的網路模型都是固定大小的輸入,但其實輸入多大的影象卷積都是沒問題的,輸入多大卷積輸出就多大而已。這裡測試的時候比較簡單粗暴的直接把不同size的影象輸入卷積層。
以下就是SPPNet在ImageNet 2012的實驗結果:

4.SPP-NET FOR OBJECT DETECTION
SPPNet方法是從feature map的區域中提取視窗級的特徵,而R-CNN直接從影象區域中提取。這麼做的好處就是降低了卷積過程中重複計算所帶來的時間消耗,下面這張圖形象的展示了這個問題:

RCNN的整個過程是這樣的:
- 通過selective search為每一張待檢測圖片提取出2000左右的候選框;
- 每張圖片中的候選框調整到227*277大小,然後分別輸入到CNN中提取特徵;
- 提取到的特徵後,利用svm對這些特徵進行分類識別;
- 利用NMS演算法對結果進行抑制處理。
2000個左右的region proposal都要使用CNN來提取特徵,計算量是很大的。然後利用這些特徵進行分類時,同樣需要很大的記憶體。
SPPNet的整個過程:
- 同樣是使用selective search演算法為每一張待檢測的圖片提取出2000左右的候選框,這一點和RCNN相同;
- 特徵提取階段,整個圖片輸入到SPPNet中,提取出整張圖片的feature map,然後將原圖上的候選框對映到feature map上。然後對各個候選框對應的feature map上的塊做金字塔空間池化,提取出固定長度的特徵向量;
- 使用SVM演算法對得到的特徵向量分類識別;
- 使用NMS做極大值抑制。
最大的區別是第二個步驟,只需要一次卷積而不用在意有多少的候選框,這使得提取特徵的時間大大縮短。
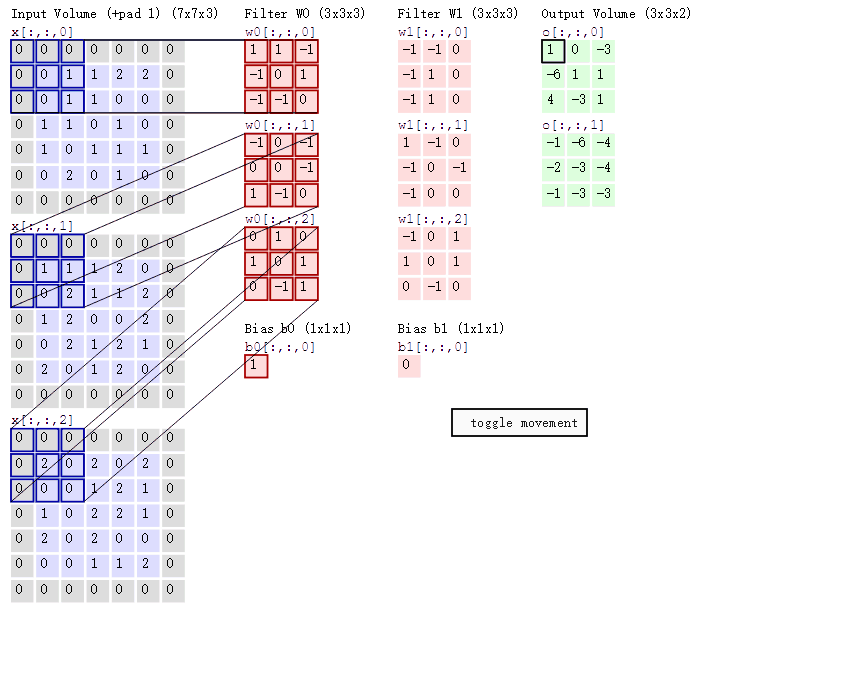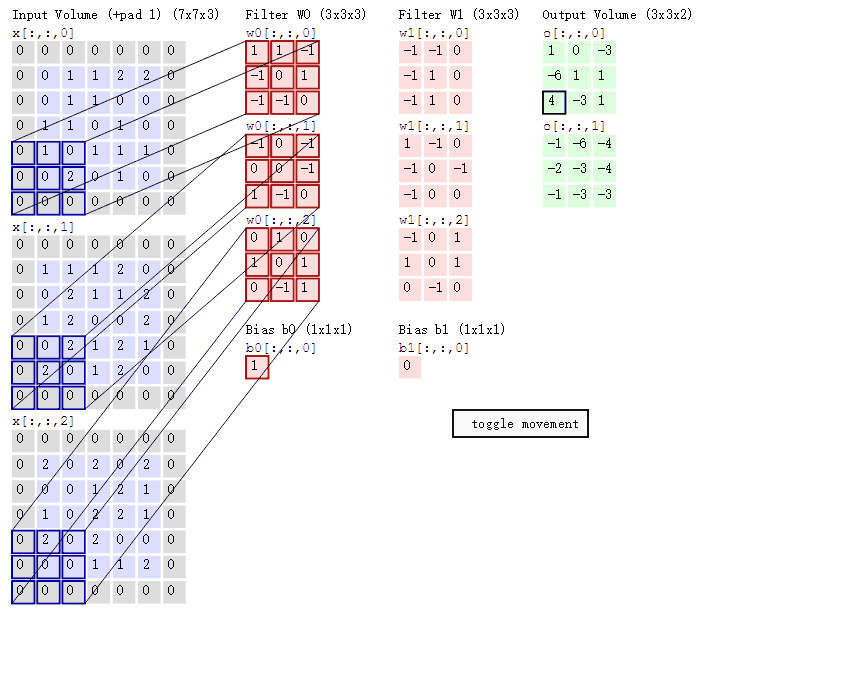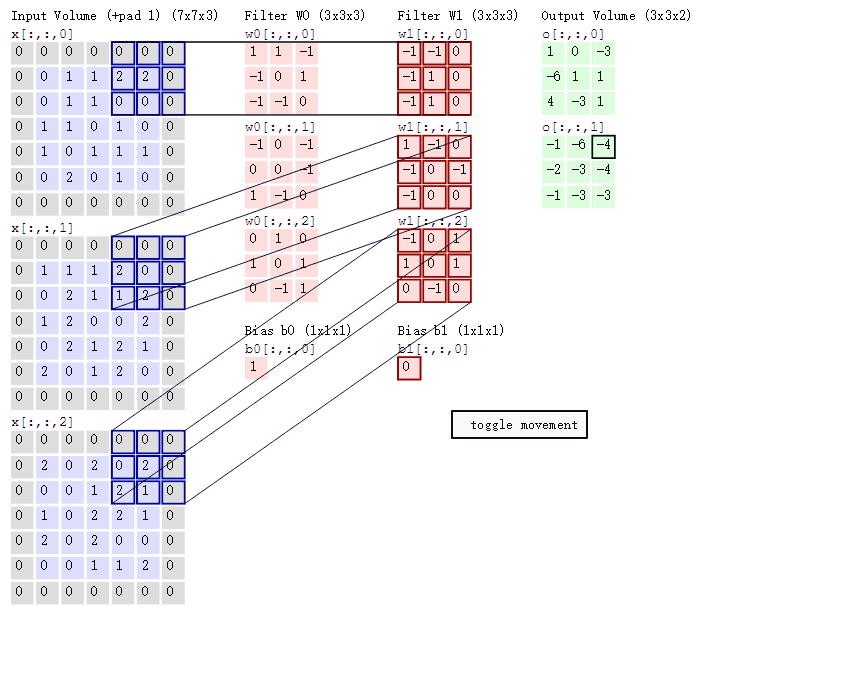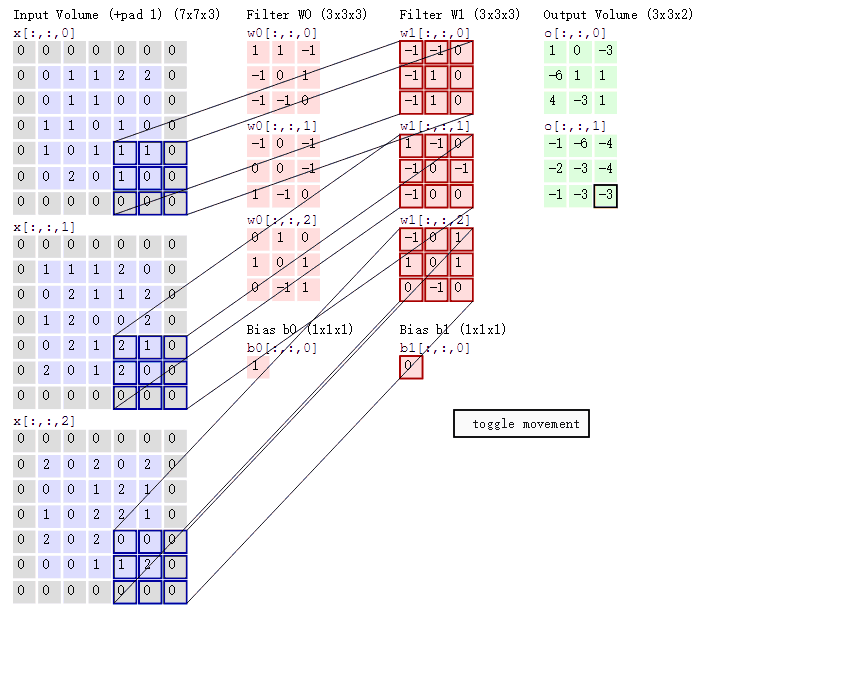
那麼具體是怎麼做對映的呢?其實這跟感受野有關,feature map中的一個畫素點其實對應於原始image的一個感受野範圍。對映關係還跟padding有關,具體可以檢視論文。簡單點說,如果一次卷積或者pooling過程之後的輸出,假設輸出的一個畫素點(x,y),對映到輸入的中心點是(x`,y`),則(x,y)跟輸入的(Sx`,Sy`)那麼多的畫素點有關(即為感受野),S就是之前的stride,看看下圖卷積的過程就明白了。如果是多層的卷積和pooling,那麼S代表之前所有的stride的乘積。
關於x和x·的對應關係,主要找出左上角和右下角兩個點就能確定整個區域了。下面就是論文給出兩個分別找出左上角右下角的公式。
![]()
![]()
當然了這只是對應於論文裡面的模型有效,如果改變了padding的值就要向x新增適當的偏移量。