
玩轉 Elasticsearch 的 SQL 功能
最近釋出的 Elasticsearch 6.3 包含了大家期待已久的 SQL 特性,今天給大家介紹一下具體的使用方法。
首先看看介面的支援情況
目前支援的 SQL 只能進行資料的查詢只讀操作,不能進行資料的修改,所以我們的資料插入還是要走之前的常規索引介面。
目前 Elasticsearch 的支援 SQL 命令只有以下幾個:
| 命令 | 說明 |
|---|---|
| DESC table | 用來描述索引的欄位屬性 |
| SHOW COLUMNS | 功能同上,只是別名 |
| SHOW FUNCTIONS | 列出支援的函式列表,支援萬用字元?過濾 |
| SHOW TABLES | 返回索引列表 |
| SELECT .. FROM table_name WHERE .. GROUP BY .. HAVING .. ORDER BY .. LIMIT .. | 用來執行查詢的命令 |
我們分別來看一下各自怎麼用,以及有什麼效果吧,自己也可以動手試一下,看看。
首先,我們建立一條資料:
POST twitter/doc/ { "name":"medcl", "twitter":"sql is awesome", "date":"2018-07-27", "id":123 }
RESTful下呼叫SQL
在 ES 裡面執行 SQL 語句,有三種方式,第一種是 RESTful 方式,第二種是 SQL-CLI 命令列工具,第三種是通過 JDBC 來連線 ES,執行的 SQL 語句其實都一樣,我們先以 RESTful 方式來說明用法。
RESTful 的語法如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT * FROM twitter"
}因為 SQL 特性是 xpack 的免費功能,所以是在 _xpack 這個路徑下面,我們只需要把 SQL 語句傳給 query 欄位就行了,注意最後面不要加上 ;
我們執行上面的語句,查詢返回的結果如下:
date | id | name | twitter
------------------------+---------------+---------------+---------------
2018-07-27T00:00:00.000Z|123 |medcl |sql is awesome ES 儼然已經變成 SQL 資料庫了,我們再看看如何獲取所有的索引列表:
POST /_xpack/sql?format=txt
{
"query": "SHOW tables"
}返回如下:
name | type
---------------------------------+---------------
.kibana |BASE TABLE
.monitoring-alerts-6 |BASE TABLE
.monitoring-es-6-2018.06.21 |BASE TABLE
.monitoring-es-6-2018.06.26 |BASE TABLE
.monitoring-es-6-2018.06.27 |BASE TABLE
.monitoring-kibana-6-2018.06.21 |BASE TABLE
.monitoring-kibana-6-2018.06.26 |BASE TABLE
.monitoring-kibana-6-2018.06.27 |BASE TABLE
.monitoring-logstash-6-2018.06.20|BASE TABLE
.reporting-2018.06.24 |BASE TABLE
.triggered_watches |BASE TABLE
.watcher-history-7-2018.06.20 |BASE TABLE
.watcher-history-7-2018.06.21 |BASE TABLE
.watcher-history-7-2018.06.26 |BASE TABLE
.watcher-history-7-2018.06.27 |BASE TABLE
.watches |BASE TABLE
apache_elastic_example |BASE TABLE
forum-mysql |BASE TABLE
twitter 有點多,我們可以按名稱過濾,如 twitt 開頭的索引,注意萬用字元只支援 %和 _,分別表示多個和單個字元(什麼,不記得了,回去翻資料庫的書去!):
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES 'twit%'"
}
POST /_xpack/sql?format=txt
{
"query": "SHOW TABLES 'twitte_'"
}上面返回的結果都是:
name | type
---------------+---------------
twitter |BASE TABLE 如果要檢視該索引的欄位和元資料,如下:
POST /_xpack/sql?format=txt
{
"query": "DESC twitter"
}返回:
column | type
---------------+---------------
date |TIMESTAMP
id |BIGINT
name |VARCHAR
name.keyword |VARCHAR
twitter |VARCHAR
twitter.keyword|VARCHAR 都是動態生成的欄位,包含了 .keyword 欄位。 還能使用下面的命令來檢視,主要是相容 SQL 語法。
POST /_xpack/sql?format=txt
{
"query": "SHOW COLUMNS IN twitter"
}另外,如果不記得 ES 支援哪些函式,只需要執行下面的命令,即可得到完整列表:
SHOW FUNCTIONS返回結果如下,也就是當前6.3版本支援的所有函式,如下:
name | type
----------------+---------------
AVG |AGGREGATE
COUNT |AGGREGATE
MAX |AGGREGATE
MIN |AGGREGATE
SUM |AGGREGATE
STDDEV_POP |AGGREGATE
VAR_POP |AGGREGATE
PERCENTILE |AGGREGATE
PERCENTILE_RANK |AGGREGATE
SUM_OF_SQUARES |AGGREGATE
SKEWNESS |AGGREGATE
KURTOSIS |AGGREGATE
DAY_OF_MONTH |SCALAR
DAY |SCALAR
DOM |SCALAR
DAY_OF_WEEK |SCALAR
DOW |SCALAR
DAY_OF_YEAR |SCALAR
DOY |SCALAR
HOUR_OF_DAY |SCALAR
HOUR |SCALAR
MINUTE_OF_DAY |SCALAR
MINUTE_OF_HOUR |SCALAR
MINUTE |SCALAR
SECOND_OF_MINUTE|SCALAR
SECOND |SCALAR
MONTH_OF_YEAR |SCALAR
MONTH |SCALAR
YEAR |SCALAR
WEEK_OF_YEAR |SCALAR
WEEK |SCALAR
ABS |SCALAR
ACOS |SCALAR
ASIN |SCALAR
ATAN |SCALAR
ATAN2 |SCALAR
CBRT |SCALAR
CEIL |SCALAR
CEILING |SCALAR
COS |SCALAR
COSH |SCALAR
COT |SCALAR
DEGREES |SCALAR
E |SCALAR
EXP |SCALAR
EXPM1 |SCALAR
FLOOR |SCALAR
LOG |SCALAR
LOG10 |SCALAR
MOD |SCALAR
PI |SCALAR
POWER |SCALAR
RADIANS |SCALAR
RANDOM |SCALAR
RAND |SCALAR
ROUND |SCALAR
SIGN |SCALAR
SIGNUM |SCALAR
SIN |SCALAR
SINH |SCALAR
SQRT |SCALAR
TAN |SCALAR
SCORE |SCORE 同樣支援萬用字元進行過濾:
POST /_xpack/sql?format=txt
{
"query": "SHOW FUNCTIONS 'S__'"
}結果:
name | type
---------------+---------------
SUM |AGGREGATE
SIN |SCALAR 那如果要進行模糊搜尋呢,Elasticsearch 的搜尋能力大家都知道,強!在 SQL 裡面,可以用 match 關鍵字來寫,如下:
POST /_xpack/sql?format=txt
{
"query": "SELECT SCORE(), * FROM twitter WHERE match(twitter, 'sql is') ORDER BY id DESC"
}最後,還能試試 SELECT 裡面的一些其他操作,如過濾,別名,如下:
POST /_xpack/sql?format=txt
{
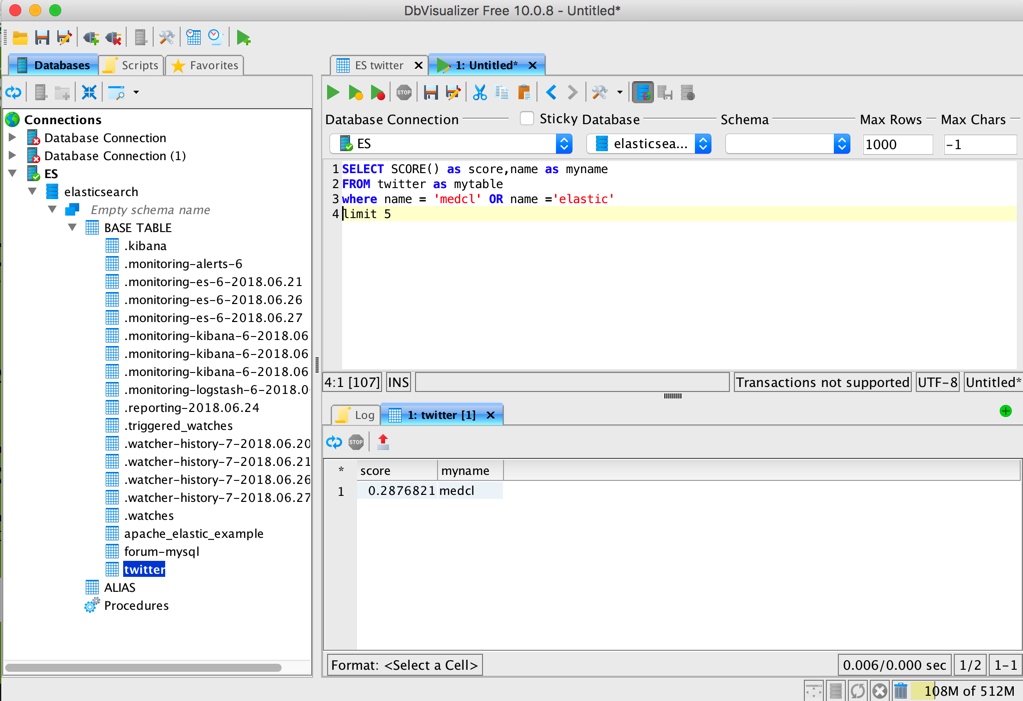
"query": "SELECT SCORE() as score,name as myname FROM twitter as mytable where name = 'medcl' OR name ='elastic' limit 5"
}結果如下:
score | myname
---------------+---------------
0.2876821 |medcl 或是分組和函式計算:
POST /_xpack/sql?format=txt
{
"query": "SELECT name,max(id) as max_id FROM twitter as mytable group by name limit 5"
}結果如下:
name | max_id
---------------+---------------
medcl |123.0 SQL-CLI下的使用
上面的例子基本上把 SQL 的基本命令都介紹了一遍,很多情況下,用 RESTful 可能不是很方便,那麼可以試試用 CLI 命令列工具來執行 SQL 語句,妥妥的 SQL 操作體驗。
切換到命令列下,啟動 cli 程式即可進入命令列互動提示介面,如下:
➜ elasticsearch-6.3.0 ./bin/elasticsearch-sql-cli
.sssssss.` .sssssss.
.:sXXXXXXXXXXo` `ohXXXXXXXXXho.
.yXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXX-
.XXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXX.
.XXXXXXXXXXXXXXXXXXXXo. .oXXXXXXXXXXXXXXXXXXXXh
.XXXXXXXXXXXXXXXXXXXXXXo``oXXXXXXXXXXXXXXXXXXXXXXy
`yXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX.
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXXXXXo`
.XXXXXXXXXXXXXXXXXXXXXXXXXo`
.oXXXXXXXXXXXXXXXXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `odo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXo`
`oXXXXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXo`
`yXXXXXXXXXXXXXXXXXXXXXXXo` oXXXXXXXXXXXXXXXXX.
.XXXXXXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXXXy
.XXXXXXXXXXXXXXXXXXXXo` /XXXXXXXXXXXXXXXXXXXXX
.XXXXXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXXXX-
-XXXXXXXXXXXXXXXo` `oXXXXXXXXXXXXXXXo`
.oXXXXXXXXXXXo` `oXXXXXXXXXXXo.
`.sshXXyso` SQL `.sshXhss.`
sql> 當你看到一個碩大的創口貼,表示 SQL 命令列已經準備就緒了,檢視一下索引列表,不,資料表的列表:
[attach]2546[/attach]
各種操作妥妥的,上面已經測試過的命令就不在這裡重複了,只是體驗不一樣罷了。
如果要連線遠端的 ES 伺服器,只需要啟動命令列工具的時候,指定伺服器地址,如果有加密,指定 keystone 檔案,完整的幫助如下:
➜ elasticsearch-6.3.0 ./bin/elasticsearch-sql-cli --help
Elasticsearch SQL CLI
Non-option arguments:
uri
Option Description
------ -----------
-c, --check <Boolean> Enable initial connection check on startup (default:
true)
-d, --debug Enable debug logging
-h, --help show help
-k, --keystore_location Location of a keystore to use when setting up SSL. If
specified then the CLI will prompt for a keystore
password. If specified when the uri isn't https then
an error is thrown.
-s, --silent show minimal output
-v, --verbose show verbose output JDBC 對接
JDBC 對接的能力,讓我們可以與各個 SQL 生態系統打通,利用眾多現成的基於 SQL 之上的工具來使用 Elasticsearch,我們以兩個工具來舉例。
和其他資料庫一樣,要使用 JDBC,要下載該資料庫的 JDBC 的驅動,我們開啟: https://www.elastic.co/downloads/jdbc-client
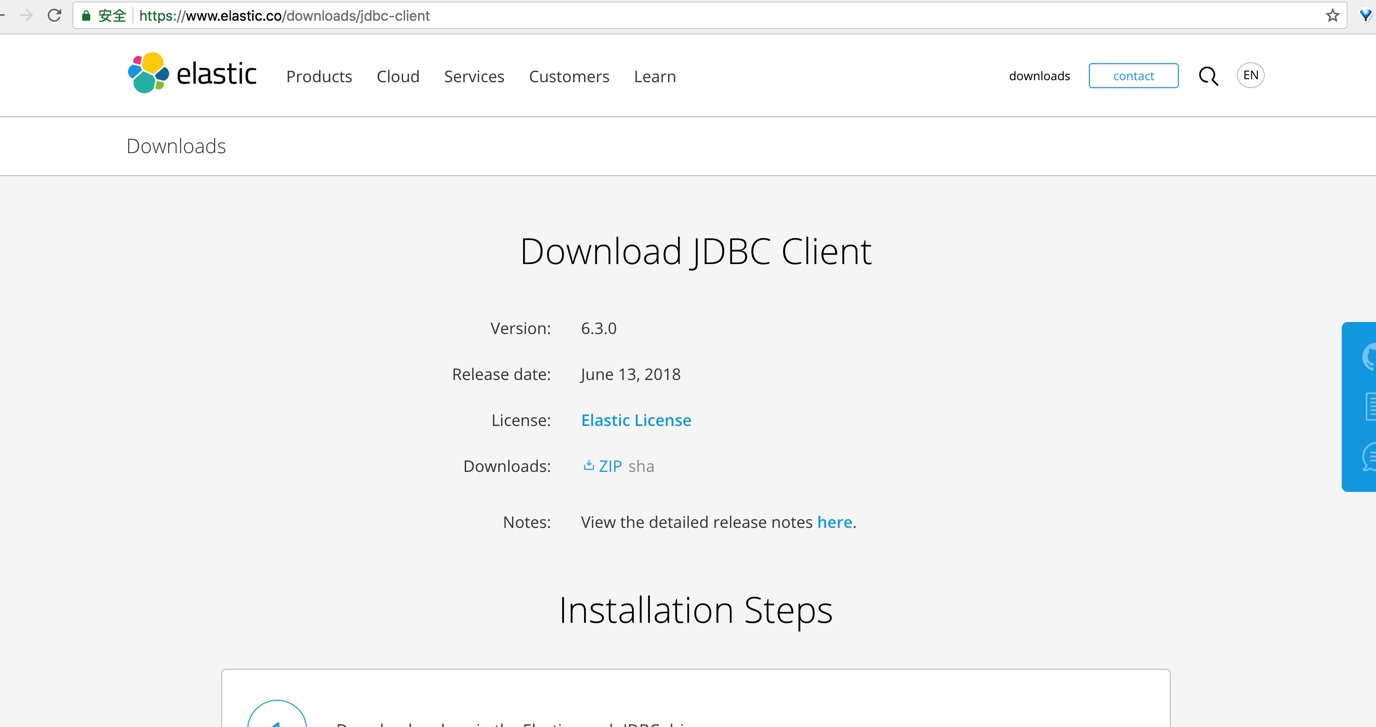
只有一個 zip 包下載連結,下載即可。
然後,我們這裡使用 DbVisualizer 來連線 ES 進行操作,這是一個數據庫的操作和分析工具,DbVisualizer 下載地址是:https://www.dbvis.com/。
下載安裝啟動之後的程式主介面如下圖:
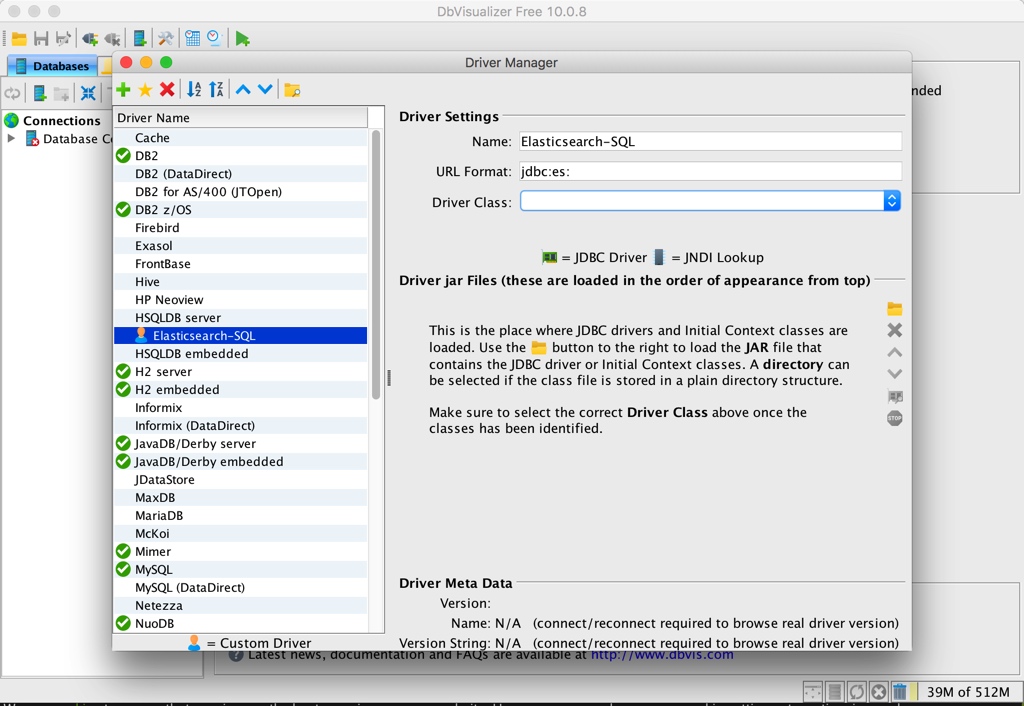
我們如果要使用 ES 作為資料來源,我們第一件事需要把 ES 的 JDBC 驅動新增到 DbVisualizer 的已知驅動裡面。我們開啟 DbVisualizer 的選單【Tools】-> 【Driver Manager】,開啟如下設定視窗:
點選綠色的加號按鈕,新增一個名為 Elasticsearch-SQL 的驅動,url format 設定成 jdbc:es:,如下圖:
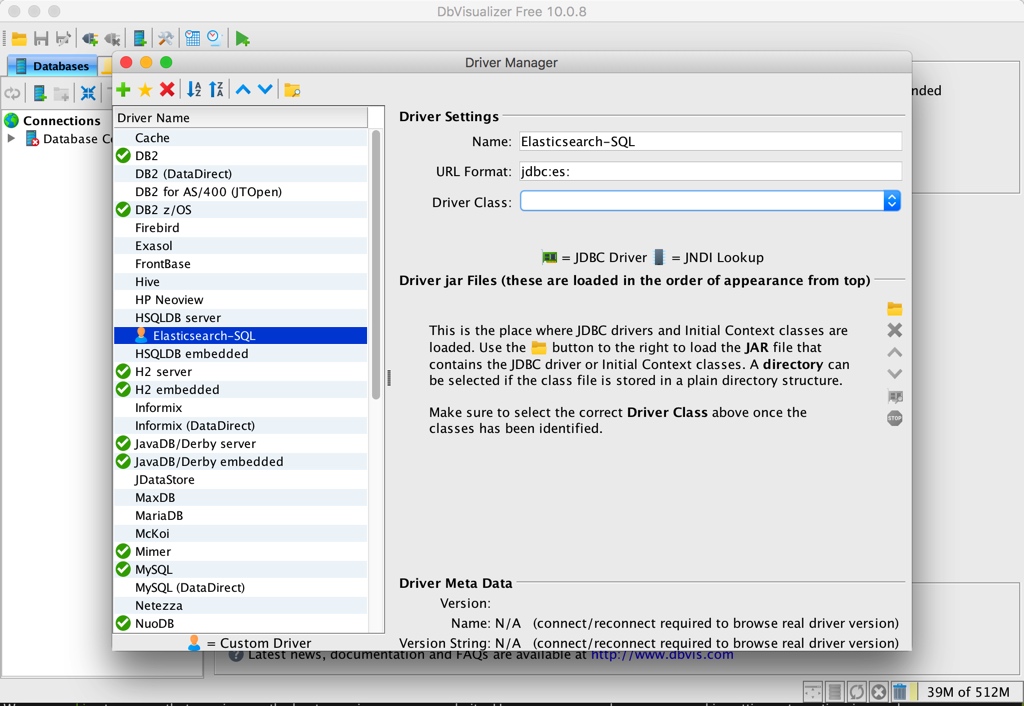
然後點選上圖黃色的資料夾按鈕,新增我們剛剛下載好且解壓之後的所有 jar 檔案,如下:

新增完成之後,如下圖:
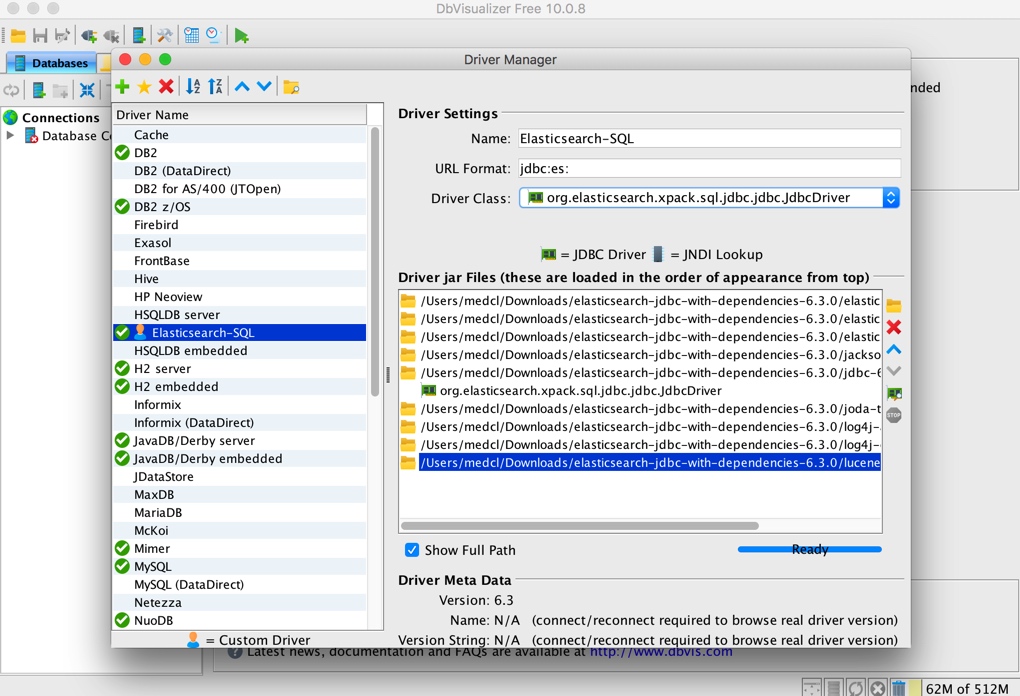
就可以關閉這個 JDBC 驅動的管理視窗了。下面我們來連線到 ES 資料庫。
選擇主程式左側的新建連線圖示,打開向導,如下:
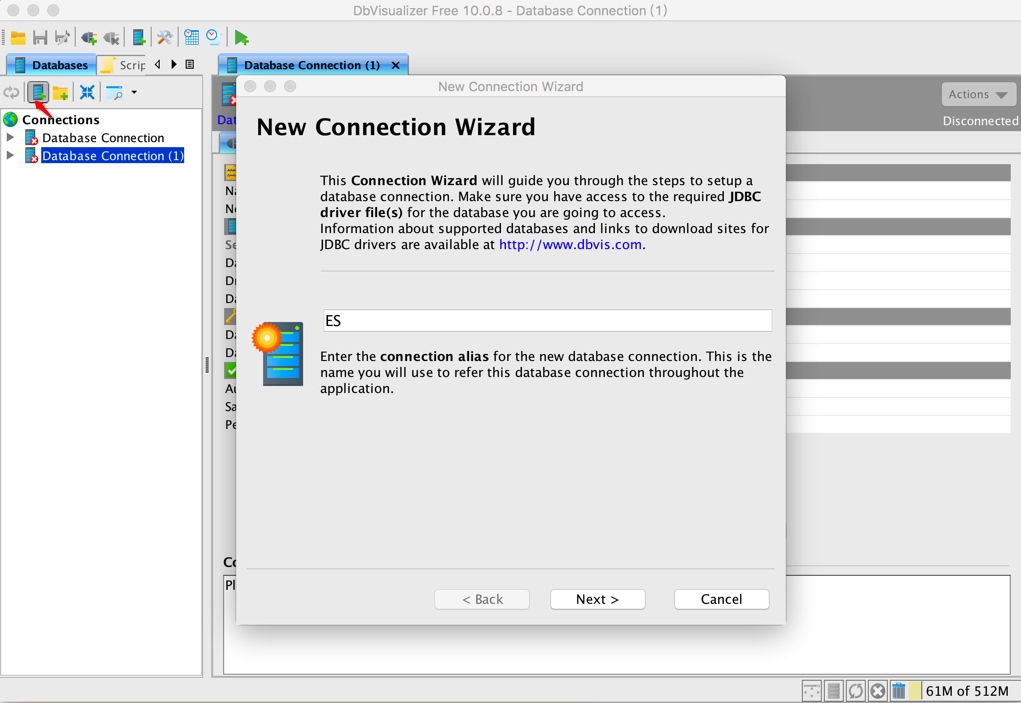
選擇剛剛加入的 Elasticsearch-SQL 驅動:
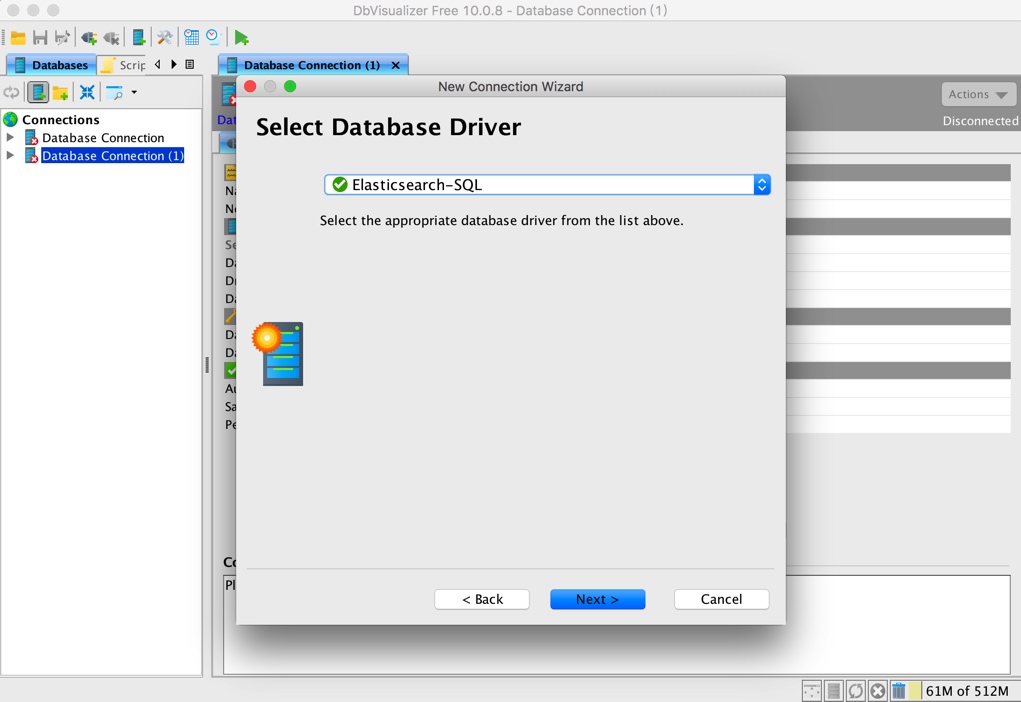
設定連線字串,此處沒有登入資訊,如果有可以對應的填上:
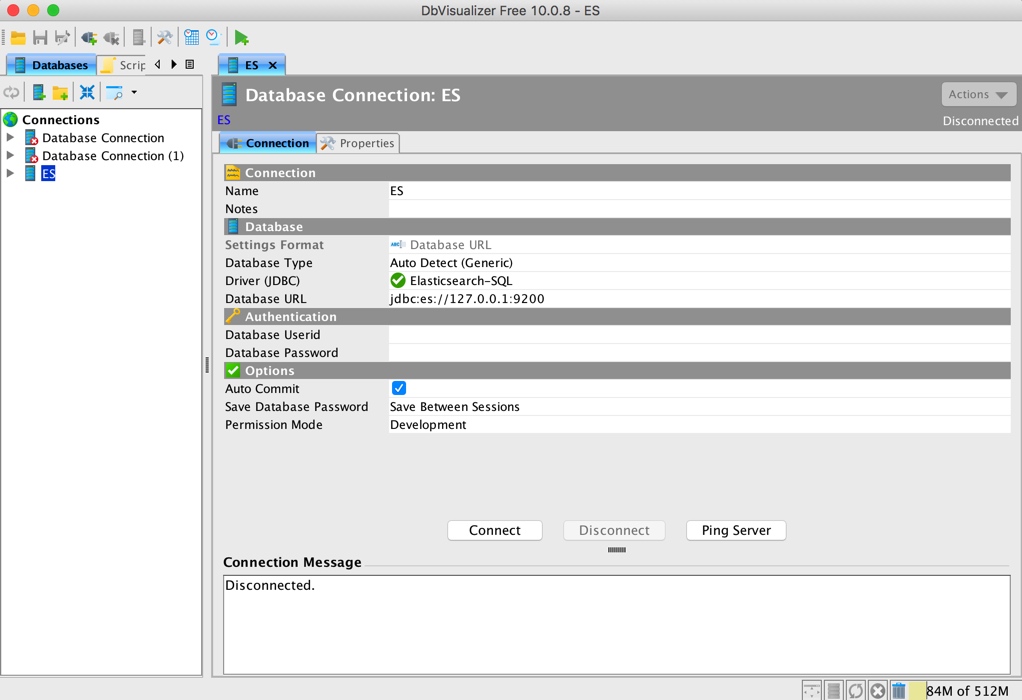
點選 Connect,即可連線到 ES,左側導航可以展開看到對應的 ES 索引資訊:
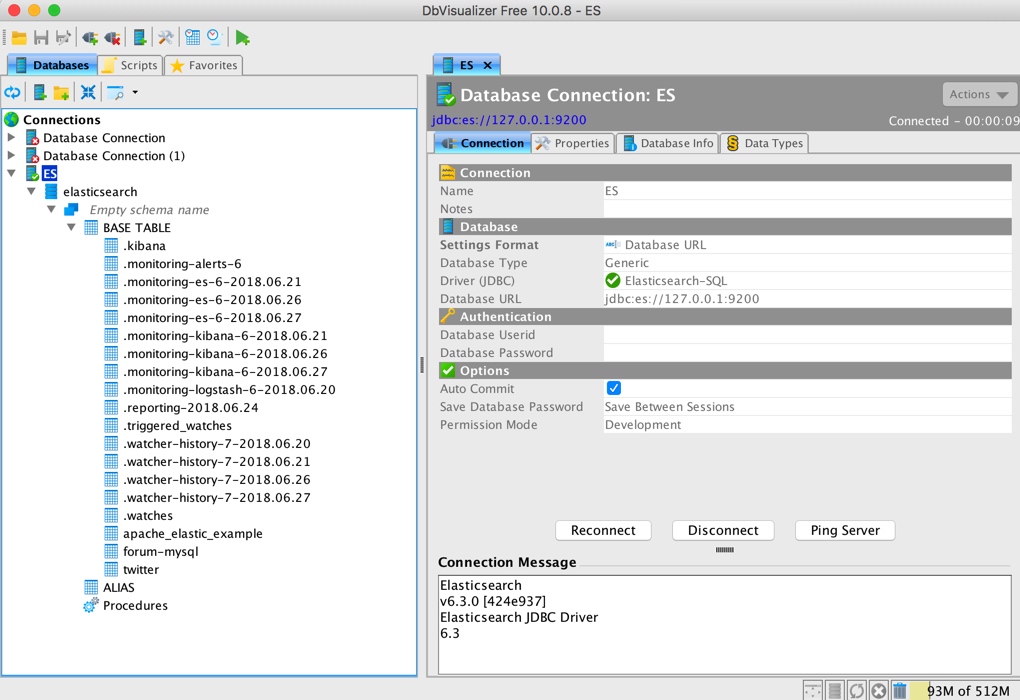
同樣可以檢視相應的庫表結果和具體的資料:
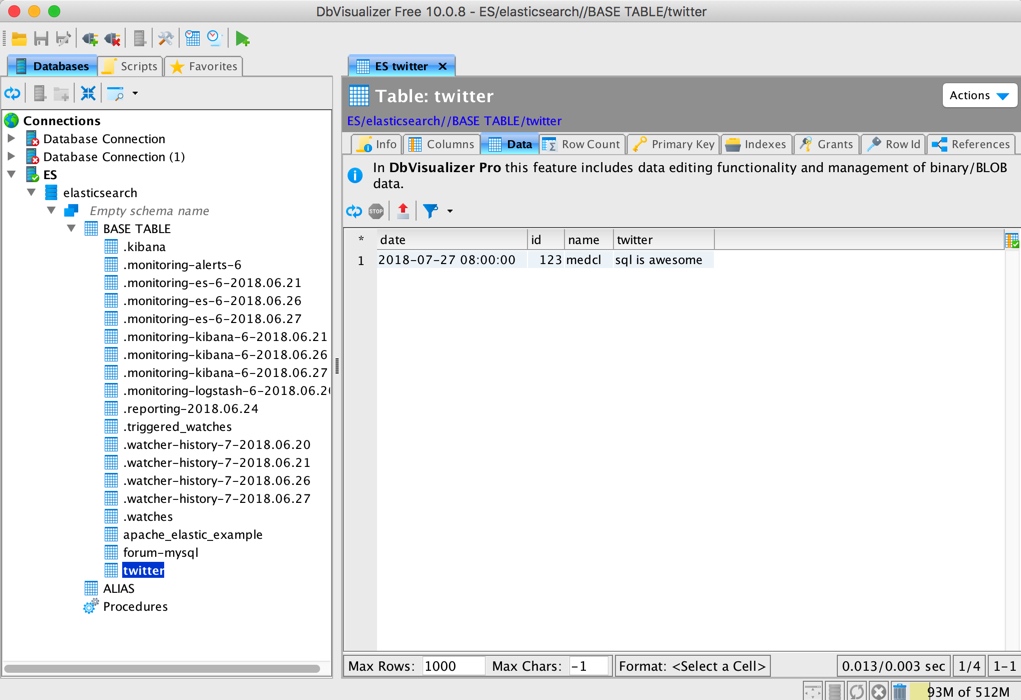
用他自帶的工具執行 SQL 也是不在話下:
同理,各種 ETL 工具和基於 SQL 的 BI 和視覺化分析工具都能把 Elasticsearch 當做 SQL 資料庫來連接獲取資料了。
最後一個小貼士,如果你的索引名稱包含橫線,如 logstash-201811,只需要做一個用雙引號包含,對雙引號進行轉義即可,如下:
關於 SQL 操作的文件在這裡:
https://www.elastic.co/guide/en/elasticsearch/reference/current/sql-jdbc.html
Enjoy!