
記filebeat記憶體洩漏問題分析及調優
ELK 從釋出5.0之後加入了beats套件之後,就改名叫做elastic stack了。beats是一組輕量級的軟體,給我們提供了簡便,快捷的方式來實時收集、豐富更多的資料用以支撐我們的分析。但由於beats都需要安裝在ELK叢集之外,在宿主機之上,其對宿主機的效能的影響往往成為了考量其是否能被使用的關鍵,而不是它到底提供了什麼樣的功能。因為業務的穩定執行才是核心KPI,而其他因運維而生的資料永遠是更低的優先順序。影響宿主機效能的方面可能有很多,比如CPU佔用率,網路吞吐佔用率,磁碟IO,記憶體等,這裡我們詳細討論一下記憶體洩漏的問題
filebeat是beats套件的核心元件之一(另一個核心是metricbeat),它一般和生成被採集檔案(主要是日誌)的程式安裝在一個地方,根據官方的建議,是filebeat是不建議用來採集NFS(網路共享磁碟)上的資料的。當filebeat執行起來之後,必定會對cpu,記憶體,網路等資源產生一定的消耗,當這種消耗能夠限定在一個可接受的範圍時,我覺得沒人會限制你在生產環境上使用filebeat。但如果出現一些非預期的情況,比如佔用了大量的記憶體,那麼運維團隊肯定是優先保障核心業務的資源,把filebeat程序給殺了。很可惜的是,記憶體洩漏的問題,從filebeat的誕生到現在就一直沒有完全解決過,無論是什麼版本(最新的6.5版本暫時還沒有觀測到)在不同場景和配置下,均出現記憶體佔用過多的問題。在這裡,我主要描述一下我碰到的在filebeat 6.0上遇到的問題。
問題場景和配置
我們使用了一套統一的簡單配置監控了很多的主機,正是這種無差異化的簡單配置,造成了問題。這是不對的,這是不對的,這是不對的!!! 合理的方式是具體問題具體分析,針對不同的場景是做定製化的配置。
multiline,多行的配置,當日志文件不符合規範,大量的匹配pattern的時候,會造成記憶體洩漏max_procs,限制filebeat的程序數量,其實是核心數,建議手動設為1
filebeat.prospectors:
- type: log
enabled: true
paths:
- /qhapp/*/*.log
tail_files 注意,以上的配置中,僅僅對cpu的核心數進行了限制,而沒有對記憶體的使用率進行特殊的限制。從配置層面來說,影響filebeat記憶體使用情況的指標主要有兩個:
queue.mem.events訊息佇列的大小,預設值是4096,這個引數在6.0以前的版本是spool-size,通過命令列,在啟動時進行配置max_message_bytes單條訊息的大小, 預設值是10M
filebeat最大的可能佔用的記憶體是max_message_bytes * queue.mem.events = 40G,考慮到這個queue是用於儲存encode過的資料,raw資料也是要儲存的,所以,在沒有對記憶體進行限制的情況下,最大的記憶體佔用情況是可以達到超過80G。
因此,建議是同時對filebeat的CPU和記憶體進行限制。
下面,我們看看,使用以上的配置在什麼情況下會觀測到記憶體洩漏
監控檔案過多
對於實時大量產生內容的檔案,比如日誌,常用的做法往往是將日誌檔案進行rotate,根據策略的不同,每隔一段時間或者達到固定大小之後,將日誌rotate。
這樣,在檔案目錄下可能會產生大量的日誌檔案。
如果我們使用萬用字元的方式,去監控該目錄,則filebeat會啟動大量的harvester例項去採集檔案。但是,請記住,我這裡不是說這樣一定會產生記憶體洩漏,只是在這裡觀測到了記憶體洩漏而已,不是說這是造成記憶體洩漏的原因。
當filebeat運行了幾個月之後,佔用了超過10個G的記憶體
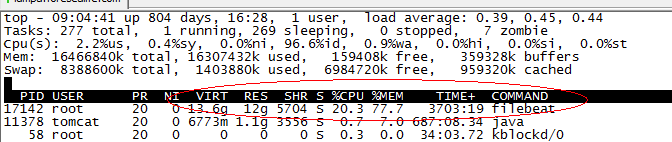
非常頻繁的rotate日誌
另一個可能是,filebeat只配置監控了一個檔案,比如test2.log,但由於test2.log不停的rotate出新的檔案,雖然沒有使用通配符采集該目錄下的所有檔案,但因為linux系統是使用inode number來唯一標示檔案的,rotate出來的新檔案並沒有改變其inode number,因此,時間上filebeat還是同時開啟了對多個檔案的監控。
因為multiline導致記憶體佔用過多
multiline.pattern: '^[[:space:]]+|^Caused by:|^.+Exception:|^\d+\serror,比如這個配置,認為空格或者製表符開頭的line是上一行的附加內容,需要作為多行模式,儲存到同一個event當中。當你監控的檔案剛巧在檔案的每一行帶有一個空格時,會錯誤的匹配多行,造成filebeat解析過後,單條event的行數達到了上千行,大小達到了10M,並且在這過程中使用的是正則表示式,每一條event的處理都會極大的消耗記憶體。因為大多數的filebeat output是需應答的,buffer這些event必然會大量的消耗記憶體。
如何觀察filebeat的記憶體
在6.5版本之前,我們是無法通過xpack的monitoring功能來觀察beats套件的效能的。因此,這裡討論的是沒有monitoring時,我們如何去檢測filebeat的效能。當然,簡單的方法是通過top,ps等作業系統的命令進行檢視,但這些都是實時的,無法做趨勢的觀察,並且都是程序級別的,無法看到filebeat內部的真是情況。因此,這裡介紹如何通過filebeat的日誌和pprof這個工具來觀察記憶體的使用情況
通過filebeat的日誌
其實filebeat的日誌,已經包含了很多引數用於實時觀測filebeat的資源使用情況,以下是filebeat的一個日誌片段:
2018-11-02T17:40:01+08:00 INFO Non-zero metrics in the last 30s: beat.memstats.gc_next=623475680 beat.memstats.memory_alloc=391032232 beat.memstats.memory_total=155885103371024 filebeat.events.active=-402 filebeat.events.added=13279 filebeat.events.done=13681 filebeat.harvester.closed=1 filebeat.harvester.open_files=7 filebeat.harvester.running=7 filebeat.harvester.started=2 libbeat.config.module.running=0 libbeat.output.events.acked=13677 libbeat.output.events.batches=28 libbeat.output.events.total=13677 libbeat.outputs.kafka.bytes_read=12112 libbeat.outputs.kafka.bytes_write=1043381 libbeat.pipeline.clients=1 libbeat.pipeline.events.active=0 libbeat.pipeline.events.filtered=4 libbeat.pipeline.events.published=13275 libbeat.pipeline.events.total=13279 libbeat.pipeline.queue.acked=13677 registrar.states.cleanup=1 registrar.states.current=8 registrar.states.update=13681 registrar.writes=28
通過pprof
眾所周知,filebeat是用go語言實現的,而go語言本身的基礎庫裡面就包含pprof這個功能極其強大的效能分析工具,只是這個工具是用於debug的,在正常模式下,filebeat是不會啟動這個選賢的,並且很遺憾,在官方文件裡面根本沒有提及我們可以使用pprof來觀測filebeat。
啟動pprof監測
具體的做法是在啟動是加上引數-httpprof localhost:6060。這裡只綁定了localhost,無法通過遠端訪問,如果想遠端訪問,應該使用0.0.0.0。
這時,你就可以通過curl http://localhost:6060/debug/pprof/heap > profile.txt等命令,獲取filebeat的實時堆疊資訊了。
遠端連線
當然,你也可以通過在你的本地電腦上安裝go,然後通過go tool遠端連線pprof。
go tool pprof http://localhost:10000/debug/pprof/profile
top 命令
連線之後,你可以通過top命令,檢視消耗記憶體最多的幾個例項:
33159.58kB of 33159.58kB total ( 100%)
Dropped 308 nodes (cum <= 165.80kB)
Showing top 10 nodes out of 51 (cum >= 512.04kB)
flat flat% sum% cum cum%
19975.92kB 60.24% 60.24% 19975.92kB 60.24% runtime.malg
7680.66kB 23.16% 83.40% 7680.66kB 23.16% github.com/elastic/beats/filebeat/channel.SubOutlet
2048.19kB 6.18% 89.58% 2048.19kB 6.18% github.com/elastic/beats/filebeat/prospector/log.NewHarvester
1357.91kB 4.10% 93.68% 1357.91kB 4.10% runtime.allgadd
1024.08kB 3.09% 96.76% 1024.08kB 3.09% runtime.acquireSudog
544.67kB 1.64% 98.41% 544.67kB 1.64% github.com/elastic/beats/libbeat/publisher/queue/memqueue.NewBroker
528.17kB 1.59% 100% 528.17kB 1.59% regexp.(*bitState).reset
0 0% 100% 528.17kB 1.59% github.com/elastic/beats/filebeat/beater.(*Filebeat).Run
0 0% 100% 512.04kB 1.54% github.com/elastic/beats/filebeat/channel.CloseOnSignal.func1
0 0% 100% 512.04kB 1.54% github.com/elastic/beats/filebeat/channel.SubOutlet.func1
檢視堆疊呼叫圖
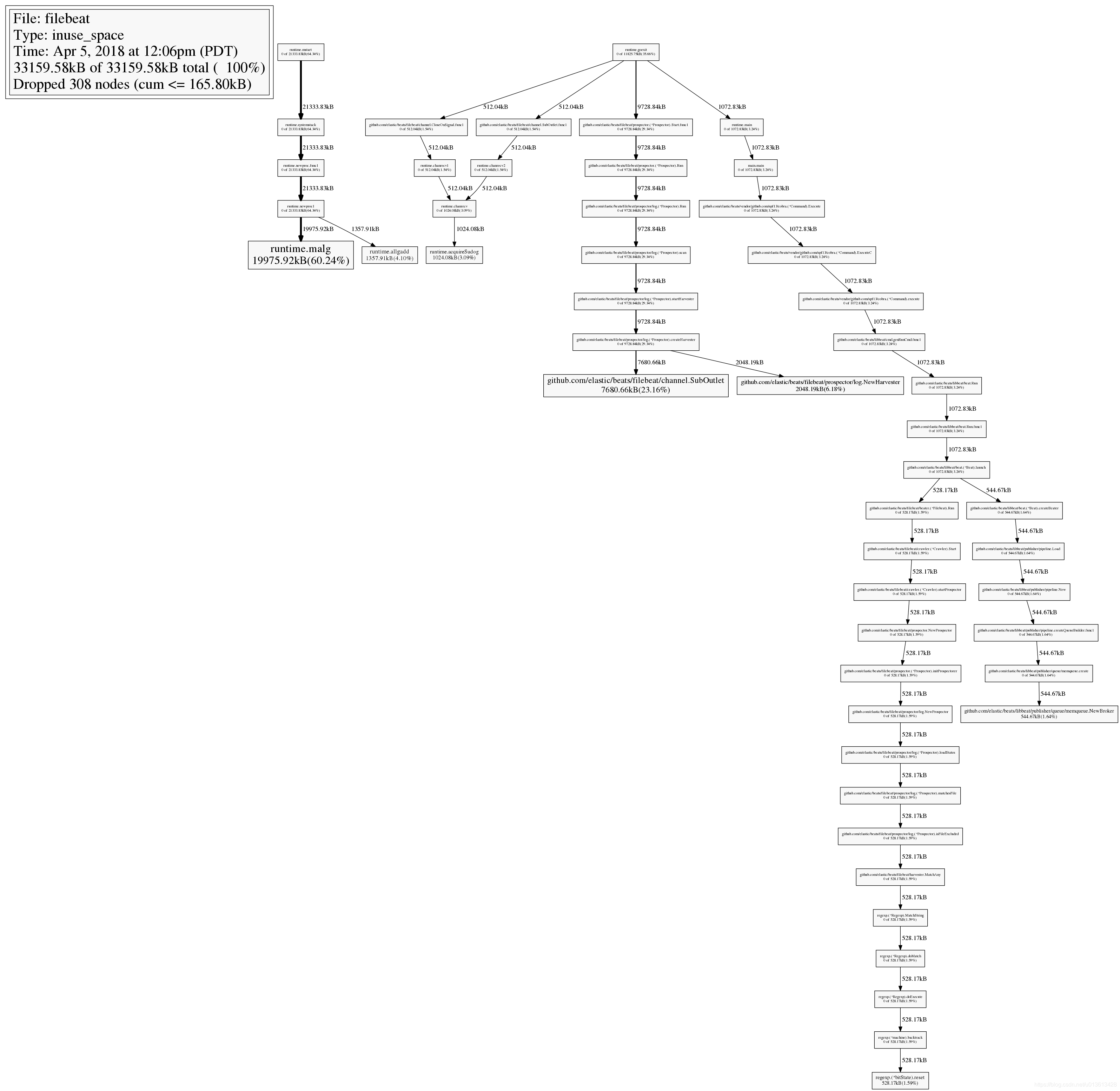
輸入web命令,會生產堆疊呼叫關係的svg圖:
檢視原始碼
通過list命令,可以迅速檢視可以例項的問題原始碼,比如在之前的top10命令中,我們已經看到github.com/elastic/beats/filebeat/channel.SubOutlet這個類的例項佔用了大量的記憶體,我們可以通過list做進一步的分析:
(pprof) list SubOutlet
Total: 32.38MB
ROUTINE ======================== github.com/elastic/beats/filebeat/channel.SubOutlet in /home/jeremy/src/go/src/github.com/elastic/beats/filebeat/channel/util.go
7.50MB 7.50MB (flat, cum) 23.16% of Total
. . 15:// SubOutlet create a sub-outlet, which can be closed individually, without closing the
. . 16:// underlying outlet.
. . 17:func SubOutlet(out Outleter) Outleter {
. . 18: s := &subOutlet{
. . 19: isOpen: atomic.MakeBool(true),
1MB 1MB 20: done: make(chan struct{}),
2MB 2MB 21: ch: make(chan *util.Data),
4.50MB 4.50MB 22: res: make(chan bool, 1),
. . 23: }
. . 24:
. . 25: go func() {
. . 26: for event := range s.ch {
. . 27: s.res <- out.OnEvent(event)