
YOLT目標檢測演算法詳細總結分析(one-stage)(深度學習)(CVPR 2018)
論文名稱:《 You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery 》
論文下載:https://arxiv.org/abs/1805.09512
論文程式碼:https://github.com/CosmiQ/yolt
演算法解讀:
這篇文章是做衛星圖的目標檢測,在YOLO v2演算法基礎上做了改進得到YOLT(You Only Look Twice)演算法,因為衛星圖的目標檢測和常見的目標檢測場景最大的區別在於衛星影象本身尺寸很大(比如16000*16000),其次目標尺寸非常小而且常常聚集在一起。因此YOLT演算法整體上是解決衛星圖這種特殊場景的目標檢測,對於通用目標檢測演算法中小目標的檢測有一定的借鑑意義,同時這篇文章也列舉了一些在實際專案中對效果提升有所幫助的點,也值得借鑑。另外,在衛星圖中,用ground sample distance(GSD)表示解析度,比如常見的衛星影象是30cm GSD。

衛星圖的目標檢測主要的幾個難點和這篇文章的解決方案在Figure3中已經詳細列出了,左邊一列是難點,右邊一列是對應的解決方案。主要包括:
一、衛星圖目標的尺寸、方向多樣,因為衛星圖是從空中拍攝的,所以角度不固定,像船、汽車的方向都可能和常規目標檢測演算法中的差別較大,因此檢測難度大。解決方案是對資料做尺度變換、旋轉等資料增強操作。
二、小目標的檢測難度大。解決方案包括:1、修改網路結構,使得從輸入影象到最後特徵的stride等於16,而不是YOLO v2中的32,如果stride等於32,那麼輸入影象中的3232區域在最後輸出特徵中等價於一個點,假如一個目標在輸入影象中的畫素區域小於3232,那麼就難以檢測出來,修改成stride等於16後,就有利於檢測出大小在3232到1616的目標。2、沿用YOLO v2中的passthrough layer,融合不同尺度的特徵(5252和2626大小的特徵),這種特徵融合做法在目前大部分通用目標檢測演算法中被用來提升對小目標的檢測效果。3、不同scale的檢測模型融合,主要是因為待檢測目標的尺度差異較大,比如飛機和機場,因此採用不同尺度的輸入訓練檢測模型,通過融合檢測結果得到最終輸出。
三、衛星圖尺寸太大,超過一般檢測模型的最大輸入尺寸要求,而一般採用對輸入影象進行降取樣後再檢測的演算法效果不好,如圖Figure2所示。解決方案包括:1、將原輸入影象切塊,然後分別輸入模型進行檢測。2、不同scale的檢測模型融合。

Figure2是關於用兩種不同型別影象作為輸入時模型的預測結果對比,模型是基於標準的YOLO v2進行訓練的。左邊是直接將原圖縮小到416416大小,結果模型一個汽車目標都沒有檢測出來。右邊是從原圖中裁剪出416416大小的區域然後作為模型的輸入,結果模型可以將部分汽車目標檢測出來,但是效果依然不算很好。從這個實驗可以看出直接將原圖縮小並作為模型的輸入是不合適的,這也是後面再訓練和測試階段都採用裁剪方式的原因,同時也能增加訓練資料量。同時因為右圖的檢測效果不好很大程度上是因為目標的畫素點少於32這個界限,所以後續對網路結構做了修改,提升了模型對小目標的檢測效果。

Table1是關於YOLT演算法的網路結構示意圖,網路結構與YOLO v2相比比較大的修改是最後輸出特徵尺寸只到2626(針對416416的輸入影象而言,因此stride等於16,YOLO v2等目標檢測演算法中stride一般等於16),這樣就能有效提高對小目標的檢測效果。

Figure4是關於測試模型時對輸入影象的處理,最上面的是原始的輸入影象,前面提到過衛星圖的原始尺寸很大,難以直接作為模型的輸入,因此這裡通過滑窗方式裁剪指定尺寸(比如416*416)的影象作為模型的輸入(文中將裁剪後的影象稱為chip),而且相鄰chip會有15%區域的重疊,如圖Figure4所示,目的是保證原圖的每個區域都能被完整檢測到,雖然這樣有可能帶來一些重複檢測,但可以通過NMS演算法去除。因此一張衛星圖會裁剪出成百上千的指定尺寸影象,這些影象經過檢測後將檢測結果合併在一起就得到最終的檢測結果。
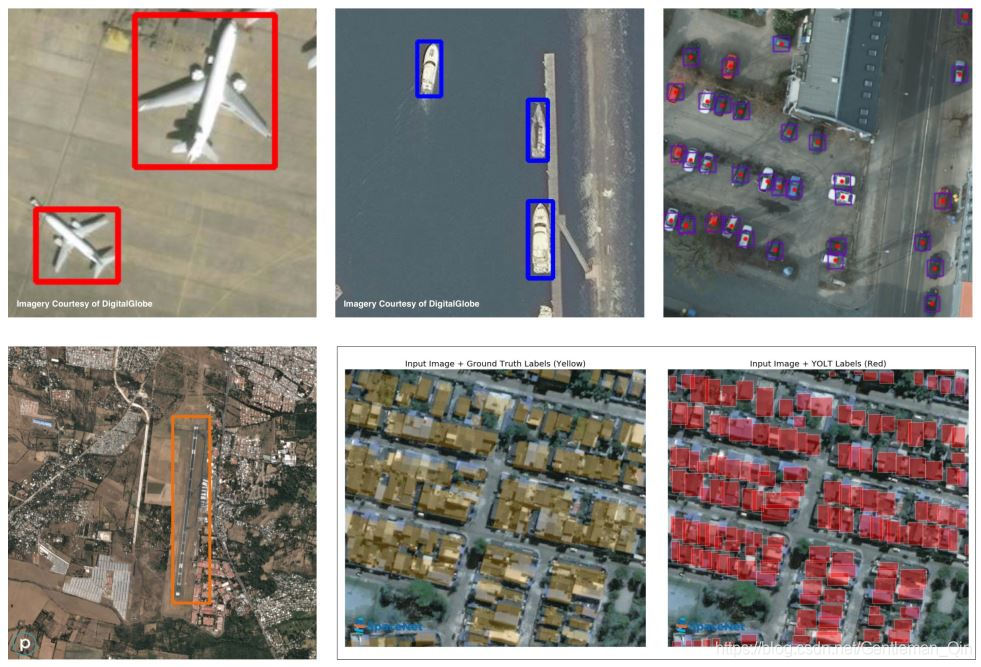
Figure5是關於訓練資料的整體情況,一共檢測5個類別:飛機、船、建築物、汽車、機場。對訓練資料的處理和測試資料類似,也是採用從原圖中裁剪出chip進行訓練。

本來作者是訓練一個模型檢測上述的5種目標,但是在實驗過程中發現不同尺度的目標容易產生誤檢,這才有了這篇文章的基於不同尺度影象訓練兩個檢測模型,通過融合不同模型的結果達到最優效果。Figure6就是關於機場目標的誤檢例項,因為機場的訓練資料非常少,所以直觀的想法是通過增加機場的資料提高機場的檢測效果,即便沒有辦法增加資料,還可以通過一定的後處理邏輯將部分誤檢過濾掉(比如尺寸非常小的機場預測框),當然這篇文章採用的是另外一種方法:融合不同尺度影象的檢測模型結果。這裡針對機場目標和其他目標分別訓練了一個檢測模型,這兩個檢測模型的輸入影象尺度也不一樣,測試影象時同理,最後將不同檢測模型、不同chip的檢測結果合併在一起就得到最終一張衛星影象的輸出。
實驗結果:

Figure7是一張關於汽車目標的檢測結果,檢測效果還是非常不錯的,在1秒內能夠得到檢測結果,同時F1值達到0.95,直觀上可以和前面的Figure2做對比。

在這篇文章中作者還對不同解析度的輸入做了實驗,Figure10是對原始解析度(左上角的0.15m表示GSD是0.15m)做不同程度放大後得到的低解析度影象,這些影象都將用來訓練模型,後面有對應的實驗分析模型對於不同解析度影象的檢測效果。

Figure13是關於不同解析度輸入下檢測模型的F1值,上面的橫座標是目標的畫素尺寸。可以看出隨著解析度的降低,影象中目標的畫素尺寸也越來越小,檢測效果(F1值)也越來越低。不過即便目標只有5個畫素點,依然有很好的檢測效果。

Figure12是對應不同解析度影象的檢測效果直觀對比,左圖是15cm GSD的結果,右圖是90cm GSD的結果。

Table3是YOLT演算法對不同目標的效果和速度情況。